DeepSeek‑OCR:上下文光学压缩
DeepSeek‑OCR: Contexts Optical Compression
摘要
我们提出 DeepSeek‑OCR,作为通过光学二维映射压缩长上下文可行性的初步探索。DeepSeek‑OCR 由两个组件组成:DeepEncoder 与作为解码器的 DeepSeek3B‑MoE‑A570M。其中,DeepEncoder 是核心引擎:它被设计为在高分辨率输入下保持较低激活,同时实现高压缩比,以确保视觉 token 数量既最优又可控。实验表明,当文本 token 数不超过视觉 token 的 10 倍(即压缩比 < $10\times$)时,模型可达到 97% 的解码(OCR)精度;即便在 $20\times$ 的压缩比下,OCR 准确率仍约为 60%。这为历史长上下文压缩、以及 LLM 中的记忆遗忘机制等研究方向带来可观前景。除此之外,DeepSeek‑OCR 也具有很高的实用价值:在 OmniDocBench 上,它仅用 100 个视觉 token 就超过了 GOT‑OCR2.0(256 token/页),并在使用少于 800 个视觉 token 的情况下优于 MinerU2.0(平均每页 6000+ token)。在生产环境中,DeepSeek‑OCR 可在单张 A100‑40G 上以每天 20 万页以上的规模生成 LLM/VLM 训练数据。代码与模型权重已在 http://github.com/deepseek-ai/DeepSeek-OCR 开源。

1. 引言
现有大语言模型(LLM)在处理长文本内容时面临显著的计算挑战,因为成本随序列长度呈二次增长。我们探索一种潜在解决方案:将视觉模态作为文本信息的高效压缩媒介。一张包含文档文字的图片,可以用远少于等价数字文本的 token 表示丰富信息,这提示:通过视觉 token 进行光学压缩可能实现更高的压缩率。
这一观察促使我们从以 LLM 为中心的视角重新审视视觉‑语言模型(VLM):关注视觉编码器如何提升 LLM 处理文本信息的效率,而不是人类已经很擅长的基础视觉问答(VQA)任务[12,24,32,41,16]。OCR 任务作为连接视觉与语言的中间模态,为“视觉‑文本压缩”范式提供了理想试验台:它在视觉与文本表示之间建立了自然的压缩‑解压映射,并提供可量化的评估指标。
因此,我们提出 DeepSeek‑OCR:一个为高效视觉‑文本压缩而设计的 VLM,作为概念验证(proof‑of‑concept)的初步模型。我们的工作主要贡献如下:
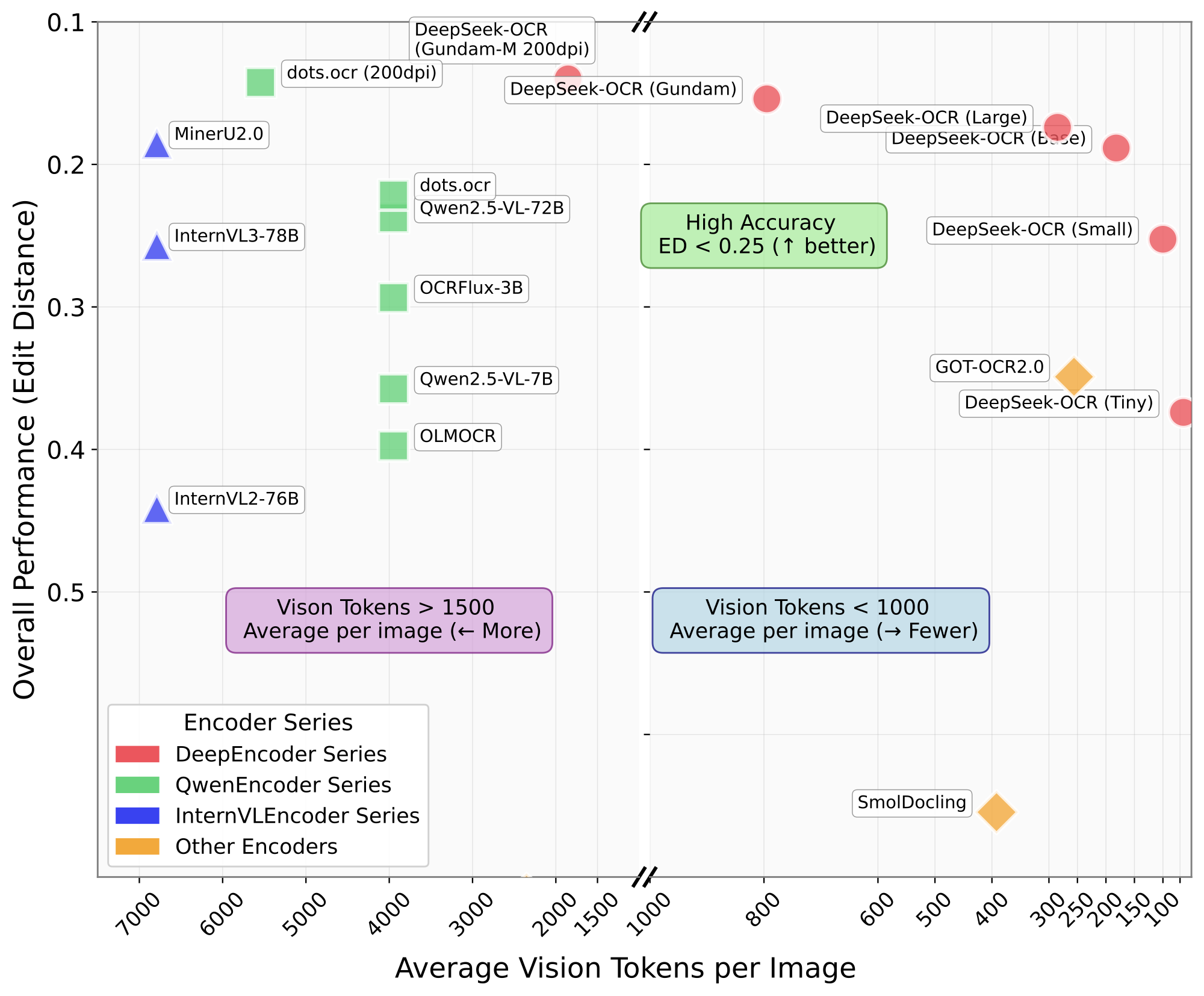
第一,我们给出关于视觉‑文本 token 压缩比的系统性量化分析。在 Fox 基准[21] 的多样文档布局下,当文本压缩比为 $9\text{–}10\times$ 时,我们的方法可实现 96%+ 的 OCR 解码精度;在 $10\text{–}12\times$ 压缩时约为 90%;在 $20\times$ 压缩时仍约为 60%(考虑到输出与真值在格式上的差异,实际准确率可能更高),如图 1(a) 所示。这些结果表明:小型语言模型能够有效学习解码被压缩的视觉表示;因此可以合理推测,更大的 LLM 通过合适的预训练设计可更容易获得类似能力。
第二,我们提出 DeepEncoder:一种在高分辨率输入下仍可保持低激活内存与少量视觉 token 的新型结构。它通过一个 $16\times$ 的卷积压缩器,将以窗口注意力为主的编码器组件与以稠密全局注意力为主的编码器组件串联起来:窗口注意力侧负责处理大量视觉 token,而压缩器在进入稠密全局注意力侧之前减少 token 数,从而实现有效的内存与 token 压缩。
第三,我们基于 DeepEncoder 与 DeepSeek3B‑MoE[19,20] 构建 DeepSeek‑OCR。如图 1(b) 所示,它在 OmniDocBench 上以端到端模型中最少的视觉 token 达到 SOTA 表现。我们还为模型加入图表、化学式、简单平面几何图形与自然图像的解析能力,以进一步提升实用性。在生产环境中,DeepSeek‑OCR 可在 20 个节点(每节点 8 张 A100‑40G)上为 LLM/VLM 生成每天 3300 万页的数据。
总之,本文展示了一项将视觉模态作为高效压缩媒介、用于 LLM 文本信息处理的初步探索。通过 DeepSeek‑OCR,我们说明了对不同历史上下文阶段可实现 $7\text{–}20\times$ 的显著 token 减少,为缓解大模型长上下文挑战提供了一个有前景的方向。我们给出的量化分析为 VLM 的 token 分配优化提供了经验性参考,而提出的 DeepEncoder 结构也展示了真实部署的可行性。尽管本文以 OCR 作为概念验证,但该范式为重新思考视觉与语言模态如何协同提升大规模文本处理与智能体系统的计算效率,打开了新的可能性。

2. 相关工作
2.1 VLM 中的典型视觉编码器
如图 2 所示,当前开源 VLM 主要使用三类视觉编码器。第一类是以 Vary[36] 为代表的双塔(dual‑tower)结构,它通过并行的 SAM[17] 编码器提升用于高分辨率图像处理的视觉词表参数规模。该方法在参数量与激活内存上可控,但也存在显著缺点:需要双路图像预处理,增加部署复杂度,并使训练时的编码器流水线并行(pipeline parallelism)更难实现。第二类是以 InternVL2.0[8] 为代表的切片(tile)方法:将图像切成小块并行处理,从而在高分辨率设置下降低激活内存。虽然可处理极高分辨率,但由于通常原生编码器分辨率较低(低于 $512\times512$),大图会被过度切碎,导致视觉 token 数量过多。第三类是以 Qwen2‑VL[35] 为代表的自适应分辨率编码:采用 NaViT[10] 范式,直接对完整图像做 patch 切分并处理,不依赖切片并行。它能灵活适配不同分辨率,但在处理大图时会遭遇巨大的激活内存消耗,可能导致 GPU 显存溢出;此外,序列打包(sequence packing)训练需要极长序列长度。视觉 token 过长也会拖慢推理时的 prefill 与生成阶段。
2.2 端到端 OCR 模型
OCR(尤其是文档解析任务)一直是图像到文本领域的活跃方向。随着 VLM 的发展,大量端到端 OCR 模型出现,通过简化系统将传统流水线结构(需要分别训练检测与识别专家模型)“端到端化”。Nougat[6] 首先在 arXiv 学术论文 OCR 上采用端到端框架,展示了模型处理稠密感知任务的潜力。GOT‑OCR2.0[38] 将 OCR2.0 的范围拓展到更多合成图像解析任务,并设计了在性能‑效率间折中的 OCR 模型,进一步凸显端到端 OCR 研究潜力。此外,Qwen‑VL 系列[35]、InternVL 系列[8] 等通用视觉模型及其衍生工作持续强化文档 OCR 能力,以探索稠密视觉感知的边界。但一个关键研究问题仍未被很好回答:对于一份包含 1000 个单词的文档,至少需要多少视觉 token 才能完成解码?这一问题对“一图胜千言(a picture is worth a thousand words)”这一原则的研究具有重要意义。
3. 方法
3.1 整体架构
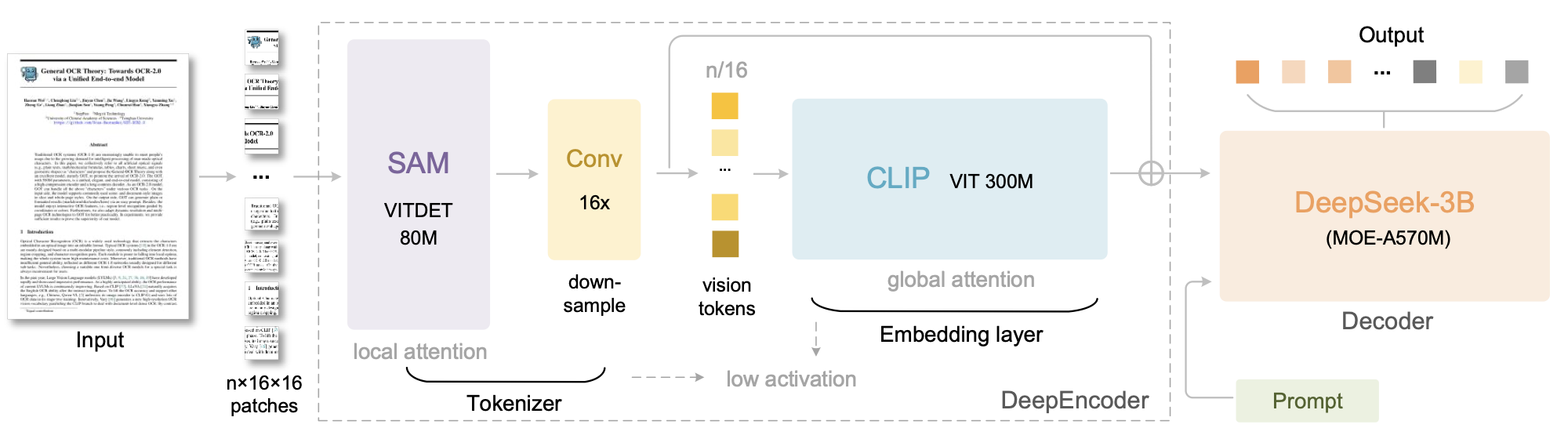
如图 3 所示,DeepSeek‑OCR 采用统一的端到端 VLM 架构,由编码器与解码器组成。编码器(即 DeepEncoder)负责提取图像特征并对视觉表示进行 token 化与压缩;解码器则在图像 token 与提示词(prompt)的条件下生成所需结果。DeepEncoder 参数量约 3.8 亿,主要由 8000 万参数的 SAM‑base[17] 与 3 亿参数的 CLIP‑large[29] 串联构成。解码器采用 3B 的 MoE[19,20] 架构,激活参数量约 5.7 亿。下文将分别介绍模型组件、数据工程与训练技巧。
3.2 DeepEncoder
为探索上下文光学压缩(contexts optical compression)的可行性,我们需要一个具备如下特性的视觉编码器:
- 能够处理高分辨率输入;
- 在高分辨率下激活内存较低;
- 输出的视觉 token 数量少;
- 支持多分辨率输入;
- 参数量适中。
然而,如 2.1 节所述,现有开源编码器难以同时满足这些条件。因此我们自行设计了一种新的视觉编码器,命名为 DeepEncoder。

3.2.1 DeepEncoder 的结构
DeepEncoder 主要由两个部分组成:以窗口注意力为主的视觉感知特征提取模块,以及带稠密全局注意力的视觉知识特征提取模块。为充分利用既有工作的预训练增益,我们分别采用 SAM‑base(patch size 16)与 CLIP‑large 作为两部分的主干架构。对于 CLIP,我们移除了第一层 patch embedding,因为其输入不再是图像,而是上一阶段流水线输出的 token。两部分之间借鉴 Vary[36],使用两层卷积模块对视觉 token 做 $16\times$ 下采样。每层卷积核大小为 3,stride 为 2,padding 为 1,通道数从 256 增加到 1024。若输入一张 $1024\times1024$ 图像,DeepEncoder 会将其切分为 $1024/16\times1024/16=4096$ 个 patch token。由于编码器前半部分以窗口注意力为主且仅 8000 万参数,激活开销可接受;在进入全局注意力之前,4096 个 token 经过压缩模块减少为 $4096/16=256$,从而使整体激活内存可控。
表 1:DeepEncoder 的多分辨率支持。出于研究与应用目的,我们为 DeepEncoder 设计了多样的原生分辨率(native resolution)与动态分辨率(dynamic resolution)模式。
| 模式(Mode) | 原生分辨率(Native Resolution) | 动态分辨率(Dynamic Resolution) | ||||
|---|---|---|---|---|---|---|
| Tiny | Small | Base | Large | Gundam | Gundam‑M | |
| 分辨率(Resolution) | 512 | 640 | 1024 | 1280 | 640+1024 | 1024+1280 |
| Token 数(Tokens) | 64 | 100 | 256 | 400 | $n\times100+256$ | $n\times256+400$ |
| 处理方式(Process) | resize | resize | padding | padding | resize + padding | resize + padding |
3.2.2 多分辨率支持
假设我们有一张包含 1000 个光学字符的图像,并希望测试解码所需的最小视觉 token 数。这要求模型支持可变数量的视觉 token,也即 DeepEncoder 必须支持多种分辨率。
我们通过对位置编码进行动态插值来满足这一需求,并设计若干分辨率模式进行联合训练,从而让一个 DeepSeek‑OCR 模型同时支持多分辨率。如图 4 所示,DeepEncoder 主要支持两类输入模式:原生分辨率与动态分辨率,每类都包含多个子模式。
原生分辨率包含四种子模式:Tiny、Small、Base 与 Large,对应分辨率与 token 数分别为 $512\times512$(64)、$640\times640$(100)、$1024\times1024$(256)与 $1280\times1280$(400)。由于 Tiny 与 Small 的分辨率较小,为避免浪费视觉 token,我们直接将原图 resize 到目标分辨率;对于 Base 与 Large,为保留原始长宽比,我们将图像 padding 到目标尺寸。padding 后,有效视觉 token 数会小于实际视觉 token 数,其计算为:
其中 $w$ 与 $h$ 分别表示原始输入图像的宽与高。
动态分辨率由两种原生分辨率组合而成。例如,Gundam 模式由 $n\times640\times640$ 的 tile(局部视图)与一个 $1024\times1024$ 的全局视图组成,其切片方式遵循 InternVL2.0[8]。引入动态分辨率主要出于应用考虑,尤其用于超高分辨率输入(如报纸图像)。切片可视为二次窗口注意力,有助于进一步降低激活内存。需要指出的是,由于我们的原生分辨率较大,动态分辨率下图像不会被切得过碎(tile 数量控制在 2–9 之间)。在 Gundam 模式下,DeepEncoder 输出的视觉 token 数为 $n\times100+256$,其中 $n$ 为 tile 数;当图像宽高均小于 640 时,$n$ 设为 0,即 Gundam 模式退化为 Base 模式。
我们将 Gundam 模式与四种原生分辨率模式一同训练,以实现单一模型支持多分辨率。需要注意的是,Gundam‑master 模式($1024\times1024$ 的局部视图 + $1280\times1280$ 的全局视图)是通过对已训练的 DeepSeek‑OCR 模型做继续训练得到的。这主要出于负载均衡考虑:Gundam‑master 的分辨率过大,若与其他模式共同训练会降低整体训练速度。
3.3 MoE 解码器
我们的解码器采用 DeepSeekMoE[19,20],具体为 DeepSeek‑3B‑MoE。在推理时,模型会在 64 个路由专家(routed experts)中激活其中 6 个,并激活 2 个共享专家(shared experts),激活参数量约 5.7 亿。DeepSeek‑3B‑MoE 非常适合我们这种面向领域(OCR)的 VLM 研究:它具备 3B 模型的表达能力,同时享有约 5 亿小模型的推理效率。
解码器从 DeepEncoder 压缩后的潜在视觉 token 中重建原始文本表示:
其中 $\mathbf{Z} \in \mathbb{R}^{n \times d_{\text{latent}}}$ 为 DeepEncoder 输出的压缩潜在(视觉)token,$\hat{\mathbf{X}} \in \mathbb{R}^{N \times d_{\text{text}}}$ 为重建后的文本表示。$f_{\text{dec}}$ 表示一个非线性映射,可通过 OCR 风格训练由紧凑语言模型有效学习。我们也合理推测,更大的 LLM 通过专门的预训练优化,将更自然地整合此类能力。
3.4 数据引擎
我们为 DeepSeek‑OCR 构建了复杂且多样的训练数据,包括:OCR 1.0 数据(主要由传统 OCR 任务构成,例如场景文字识别与文档 OCR);OCR 2.0 数据(主要包含对复杂人工图像的解析任务,如常见图表、化学式与平面几何解析);以及通用视觉数据(用于向 DeepSeek‑OCR 注入一定的通用图像理解能力并保留通用视觉接口)。

3.4.1 OCR 1.0 数据
文档数据是 DeepSeek‑OCR 的最高优先级。我们从互联网收集了覆盖约 100 种语言的 3000 万页多样 PDF 数据,其中中文与英文约 2500 万页,其它语言约 500 万页。针对这部分数据,我们构建两类真值:粗标注与精标注。粗标注直接用 fitz 从全量数据中提取,旨在教会模型识别光学文本(尤其是小语种)。精标注包含中英文各 200 万页:使用先进的版面模型(如 PP‑DocLayout[33])与 OCR 模型(如 MinerU[34] 与 GOT‑OCR2.0[38])构建检测‑识别交织的数据。对于小语种,在检测侧我们发现版面模型具有一定的泛化能力;在识别侧,我们使用 fitz 生成小 patch 数据训练一个 GOT‑OCR2.0,然后在版面处理后对小 patch 做标注,通过“模型飞轮(model flywheel)”最终构建 60 万条数据样本。在 DeepSeek‑OCR 训练中,我们通过不同 prompt 区分粗标注与精标注。精标注的图文真值示例如图 5 所示。我们还收集了 300 万份 Word 数据,通过直接抽取内容构建高质量的无布局图文对,该数据主要对公式与 HTML 格式表格有益。此外,我们也选取部分开源数据[28,37]作为补充。
对于自然场景 OCR,我们主要支持中文与英文。图像数据来自 LAION[31] 与 Wukong[13],使用 PaddleOCR[9] 进行标注,中英文各 1000 万条样本。与文档 OCR 类似,自然场景 OCR 也可通过 prompt 控制是否输出检测框。
3.4.2 OCR 2.0 数据
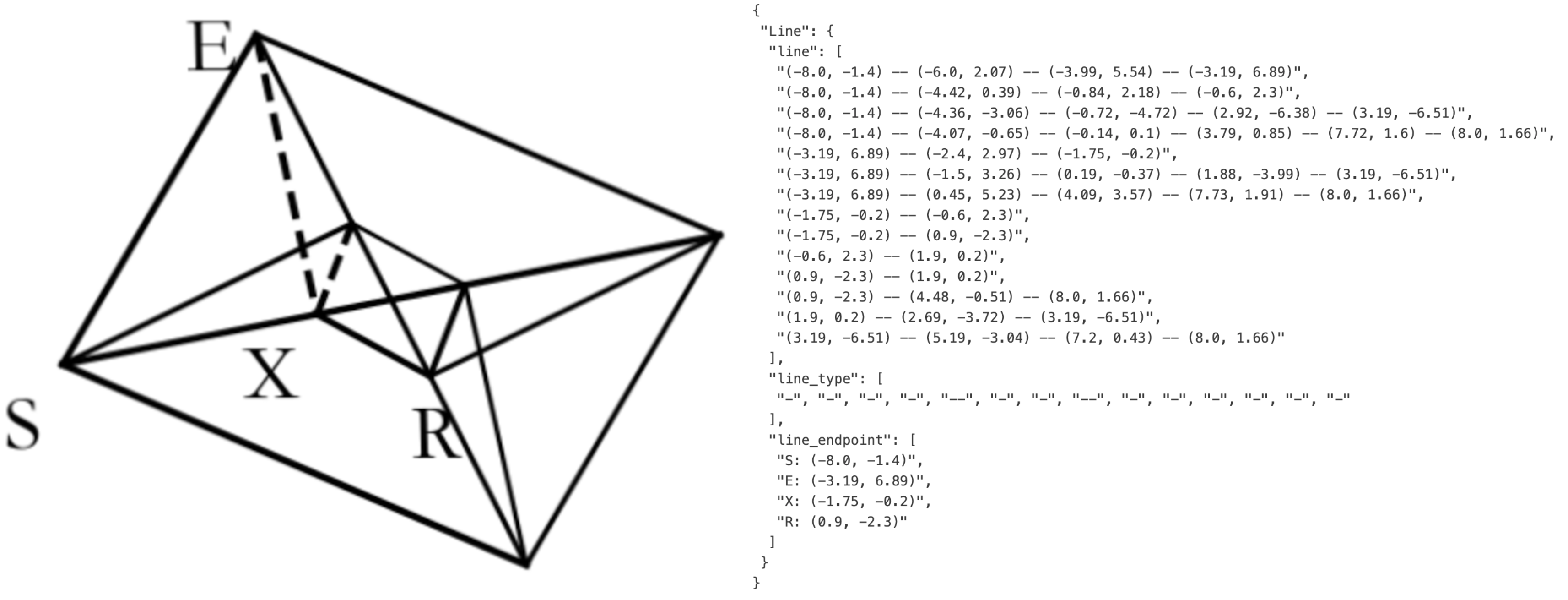
遵循 GOT‑OCR2.0[38],我们将图表、化学式与平面几何解析数据称为 OCR 2.0 数据。对于图表数据,参考 OneChart[7],我们使用 pyecharts 与 matplotlib 渲染 1000 万张图像,主要包括常见折线图、柱状图、饼图与组合图等。我们将图表解析定义为“图像 → HTML 表格”的转换任务,如图 6(a) 所示。对于化学式,我们以 PubChem 的 SMILES 格式为数据源,并用 RDKit 将其渲染为图像,构建 500 万对图文数据。对于平面几何图像,我们遵循 Slow Perception[39] 的生成方式:具体地,我们将 perception‑ruler 的 size 设为 4 以刻画每条线段。为增加渲染数据多样性,我们引入几何平移不变数据增强:同一几何图形在原图中平移,但对应的真值在坐标系中仍绘制在中心位置。基于此,我们构建了总计 100 万条平面几何解析数据,如图 6(b) 所示。
3.4.3 通用视觉数据
DeepEncoder 可从 CLIP 的预训练中获益,并具备足够参数容量以吸收通用视觉知识。因此,我们也为 DeepSeek‑OCR 准备了相应数据。遵循 DeepSeek‑VL2[40],我们为图像描述(caption)、检测(detection)与指代定位(grounding)等任务生成训练数据。需要强调的是,DeepSeek‑OCR 并非通用 VLM,该部分数据仅占总数据的 20%。引入该类数据主要是为了保留通用视觉接口,使未来对通用视觉任务感兴趣的研究者可以更方便地在此模型基础上推进工作。
3.4.4 纯文本数据
为确保模型语言能力,我们引入 10% 的内部纯文本预训练数据,并将数据统一处理到 8192 token 长度(这也是 DeepSeek‑OCR 的序列长度)。总之,在训练 DeepSeek‑OCR 时,OCR 数据占 70%,通用视觉数据占 20%,纯文本数据占 10%。
3.5 训练流程
我们的训练流程较为简单,主要包括两阶段:a) 独立训练 DeepEncoder;b) 训练 DeepSeek‑OCR。需要注意的是,Gundam‑master 模式是通过在已训练的 DeepSeek‑OCR 模型上,用 600 万条采样数据做继续训练得到。由于训练协议与其它模式一致,本文不再赘述。
3.5.1 训练 DeepEncoder
遵循 Vary[36],我们使用一个紧凑语言模型[15],采用 next token prediction 框架训练 DeepEncoder。在这一阶段,我们使用上述所有 OCR 1.0 与 2.0 数据,以及从 LAION[31] 采样的 1 亿条通用数据。我们以 batch size 1280 训练 2 个 epoch,优化器为 AdamW[23],学习率为 $5\times10^{-5}$,并使用余弦退火调度(cosine annealing scheduler)[22]。训练序列长度为 4096。
3.5.2 训练 DeepSeek‑OCR
在 DeepEncoder 准备完成后,我们使用 3.4 节所述数据训练 DeepSeek‑OCR,整个训练过程在 HAI‑LLM[14] 平台上进行。全模型使用流水线并行(pipeline parallelism, PP),分为 4 段:DeepEncoder 占两段、解码器占两段。对于 DeepEncoder,我们将 SAM 与压缩器视为视觉 tokenizer,放在 PP0 并冻结参数;将 CLIP 部分视为输入 embedding 层,放在 PP1 并解冻权重参与训练。对于语言模型部分,由于 DeepSeek3B‑MoE 共有 12 层,我们在 PP2 与 PP3 各放置 6 层。训练使用 20 个节点(每节点 8 张 A100‑40G),数据并行(DP)为 40,全局 batch size 为 640。我们使用 AdamW 优化器与 step‑based scheduler,初始学习率为 $3\times10^{-5}$。在纯文本数据上训练速度为 900 亿 token/天;在多模态数据上训练速度为 700 亿 token/天。
表 2:我们使用 Fox 基准[21] 中所有 600–1300 token 的英文文档测试 DeepSeek‑OCR 的视觉‑文本压缩比。Text tokens 表示使用 DeepSeek‑OCR 分词器对真值文本分词后的 token 数。Vision Tokens=64 或 100 分别表示将输入图像缩放到 $512\times512$ 与 $640\times640$ 后,DeepEncoder 输出的视觉 token 数。
| Text Tokens | Vision Tokens = 64 | Vision Tokens = 100 | Pages | ||
|---|---|---|---|---|---|
| Precision | Compression | Precision | Compression | ||
| 600–700 | 96.5% | $10.5\times$ | 98.5% | $6.7\times$ | 7 |
| 700–800 | 93.8% | $11.8\times$ | 97.3% | $7.5\times$ | 28 |
| 800–900 | 83.8% | $13.2\times$ | 96.8% | $8.5\times$ | 28 |
| 900–1000 | 85.9% | $15.1\times$ | 96.8% | $9.7\times$ | 14 |
| 1000–1100 | 79.3% | $16.5\times$ | 91.5% | $10.6\times$ | 11 |
| 1100–1200 | 76.4% | $17.7\times$ | 89.8% | $11.3\times$ | 8 |
| 1200–1300 | 59.1% | $19.7\times$ | 87.1% | $12.6\times$ | 4 |
表 3:我们使用 OmniDocBench[27] 测试 DeepSeek‑OCR 在真实文档解析任务上的性能。表中所有指标均为编辑距离(edit distance),数值越小表示表现越好。“Tokens”表示每页平均使用的视觉 token 数;“†200dpi”表示使用 fitz 将原始图像插值到 200dpi。对于 DeepSeek‑OCR,“Tokens”列括号内为有效视觉 token 数,按公式 (1) 计算。
| Model | Tokens | English | Chinese | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| overall | text | formula | table | order | overall | text | formula | table | order | ||
| Pipeline Models | |||||||||||
| Dolphin[11] | – | 0.356 | 0.352 | 0.465 | 0.258 | 0.35 | 0.44 | 0.44 | 0.604 | 0.367 | 0.351 |
| Marker[1] | – | 0.296 | 0.085 | 0.374 | 0.609 | 0.116 | 0.497 | 0.293 | 0.688 | 0.678 | 0.329 |
| Mathpix[2] | – | 0.191 | 0.105 | 0.306 | 0.243 | 0.108 | 0.364 | 0.381 | 0.454 | 0.32 | 0.30 |
| MinerU‑2.1.1[34] | – | 0.162 | 0.072 | 0.313 | 0.166 | 0.097 | 0.244 | 0.111 | 0.581 | 0.15 | 0.136 |
| MonkeyOCR‑1.2B[18] | – | 0.154 | 0.062 | 0.295 | 0.164 | 0.094 | 0.263 | 0.179 | 0.464 | 0.168 | 0.243 |
| PPstructure‑v3[9] | – | 0.152 | 0.073 | 0.295 | 0.162 | 0.077 | 0.223 | 0.136 | 0.535 | 0.111 | 0.11 |
| End‑to‑end Models | |||||||||||
| Nougat[6] | 2352 | 0.452 | 0.365 | 0.488 | 0.572 | 0.382 | 0.973 | 0.998 | 0.941 | 1.00 | 0.954 |
| SmolDocling[25] | 392 | 0.493 | 0.262 | 0.753 | 0.729 | 0.227 | 0.816 | 0.838 | 0.997 | 0.907 | 0.522 |
| InternVL2‑76B[8] | 6790 | 0.44 | 0.353 | 0.543 | 0.547 | 0.317 | 0.443 | 0.29 | 0.701 | 0.555 | 0.228 |
| Qwen2.5‑VL‑7B[5] | 3949 | 0.316 | 0.151 | 0.376 | 0.598 | 0.138 | 0.399 | 0.243 | 0.5 | 0.627 | 0.226 |
| OLMOCR[28] | 3949 | 0.326 | 0.097 | 0.455 | 0.608 | 0.145 | 0.469 | 0.293 | 0.655 | 0.652 | 0.277 |
| GOT‑OCR2.0[38] | 256 | 0.287 | 0.189 | 0.360 | 0.459 | 0.141 | 0.411 | 0.315 | 0.528 | 0.52 | 0.28 |
| OCRFlux‑3B[3] | 3949 | 0.238 | 0.112 | 0.447 | 0.269 | 0.126 | 0.349 | 0.256 | 0.716 | 0.162 | 0.263 |
| GPT4o[26] | – | 0.233 | 0.144 | 0.425 | 0.234 | 0.128 | 0.399 | 0.409 | 0.606 | 0.329 | 0.251 |
| InternVL3‑78B[42] | 6790 | 0.218 | 0.117 | 0.38 | 0.279 | 0.095 | 0.296 | 0.21 | 0.533 | 0.282 | 0.161 |
| Qwen2.5‑VL‑72B[5] | 3949 | 0.214 | 0.092 | 0.315 | 0.341 | 0.106 | 0.261 | 0.18 | 0.434 | 0.262 | 0.168 |
| dots.ocr[30] | 3949 | 0.182 | 0.137 | 0.320 | 0.166 | 0.182 | 0.261 | 0.229 | 0.468 | 0.160 | 0.261 |
| Gemini2.5‑Pro[4] | – | 0.148 | 0.055 | 0.356 | 0.13 | 0.049 | 0.212 | 0.168 | 0.439 | 0.119 | 0.121 |
| MinerU2.0[34] | 6790 | 0.133 | 0.045 | 0.273 | 0.15 | 0.066 | 0.238 | 0.115 | 0.506 | 0.209 | 0.122 |
| dots.ocr†200dpi[30] | 5545 | 0.125 | 0.032 | 0.329 | 0.099 | 0.04 | 0.16 | 0.066 | 0.416 | 0.092 | 0.067 |
| DeepSeek‑OCR(end2end) | |||||||||||
| Tiny | 64 | 0.386 | 0.373 | 0.469 | 0.422 | 0.283 | 0.361 | 0.307 | 0.635 | 0.266 | 0.236 |
| Small | 100 | 0.221 | 0.142 | 0.373 | 0.242 | 0.125 | 0.284 | 0.24 | 0.53 | 0.159 | 0.205 |
| Base | 256(182) | 0.137 | 0.054 | 0.267 | 0.163 | 0.064 | 0.24 | 0.205 | 0.474 | 0.1 | 0.181 |
| Large | 400(285) | 0.138 | 0.054 | 0.277 | 0.152 | 0.067 | 0.208 | 0.143 | 0.461 | 0.104 | 0.123 |
| Gundam | 795 | 0.127 | 0.043 | 0.269 | 0.134 | 0.062 | 0.181 | 0.097 | 0.432 | 0.089 | 0.103 |
| Gundam‑M†200dpi | 1853 | 0.123 | 0.049 | 0.242 | 0.147 | 0.056 | 0.157 | 0.087 | 0.377 | 0.08 | 0.085 |
4. 实验评估
4.1 视觉‑文本压缩研究
我们选用 Fox 基准[21] 来验证 DeepSeek‑OCR 在富文本(text‑rich)文档上的压缩‑解压能力,以初步探索上下文光学压缩的可行性与边界。我们使用 Fox 的英文文档部分,并用 DeepSeek‑OCR 的分词器(词表规模约 12.9 万)对真值文本 token 化,选择 600–1300 token 的文档进行测试(刚好 100 页)。由于文本 token 数量不算大,我们只需测试 Tiny 与 Small 两种模式:Tiny 对应 64 token,Small 对应 100 token。我们使用不带布局的 prompt:<image>\\nFree OCR. 来控制模型输出格式。尽管如此,输出格式仍无法与 Fox 的基准格式完全匹配,因此实际性能可能略高于测试结果。
如表 2 所示,在 $10\times$ 以内的压缩比下,模型解码精度可达约 97%,这是非常有希望的结果。未来或可通过“文本 → 图像”的方式实现近似 $10\times$ 的无损上下文压缩。当压缩比超过 $10\times$ 时,性能开始下降,可能有两个原因:一是长文档的布局更复杂;二是长文本在 $512\times512$ 或 $640\times640$ 分辨率下会变得模糊。我们认为,第一个问题可通过将文本渲染到单一布局页面来解决;第二个问题则可能成为“遗忘机制”的一项特征。即便在接近 $20\times$ 的压缩下,我们仍观察到精度可接近 60%。这些结果表明,上下文光学压缩是一个非常有前景且值得投入的研究方向;同时,它不会带来额外开销,因为可直接复用 VLM 的基础设施——多模态系统天然需要额外的视觉编码器。
表 4:OmniDocBench 中不同文档类别的编辑距离。结果表明,某些类型文档仅需 64 或 100 个视觉 token 即可达到良好表现,而另一些则需要 Gundam 模式。
| 模式 \ 类型 | Book | Slides | Financial Report | Textbook | Exam Paper | Magazine | Academic Papers | Notes | Newspaper | Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| Tiny | 0.147 | 0.116 | 0.207 | 0.173 | 0.294 | 0.201 | 0.395 | 0.297 | 0.94 | 0.32 |
| Small | 0.085 | 0.111 | 0.079 | 0.147 | 0.171 | 0.107 | 0.131 | 0.187 | 0.744 | 0.205 |
| Base | 0.037 | 0.08 | 0.027 | 0.1 | 0.13 | 0.073 | 0.052 | 0.176 | 0.645 | 0.156 |
| Large | 0.038 | 0.108 | 0.022 | 0.084 | 0.109 | 0.06 | 0.053 | 0.155 | 0.353 | 0.117 |
| Gundam | 0.035 | 0.085 | 0.289 | 0.095 | 0.094 | 0.059 | 0.039 | 0.153 | 0.122 | 0.083 |
| Gundam‑M | 0.052 | 0.09 | 0.034 | 0.091 | 0.079 | 0.079 | 0.048 | 0.1 | 0.099 | 0.077 |
4.2 OCR 实用性能
DeepSeek‑OCR 不仅是实验模型;它也具备很强的实用能力,可用于构建 LLM/VLM 预训练数据。为量化 OCR 性能,我们在 OmniDocBench[27] 上评测 DeepSeek‑OCR,结果见表 3。仅需 100 个视觉 token($640\times640$ 分辨率)时,DeepSeek‑OCR 即超过使用 256 token 的 GOT‑OCR2.0[38];当使用 400 token(有效 token 为 285,$1280\times1280$ 分辨率)时,可达到与该基准 SOTA 接近的水平。使用少于 800 token(Gundam 模式)时,DeepSeek‑OCR 优于需要接近 7000 个视觉 token 的 MinerU2.0[34]。这些结果表明 DeepSeek‑OCR 在实际应用中很强,同时也因为更高的 token 压缩而具备更高的研究上限。
如表 4 所示,一些文档类别仅需很少 token 就能达到满意性能,例如幻灯片仅需 64 个视觉 token。对于图书与报告类文档,DeepSeek‑OCR 仅用 100 个视觉 token 便可取得良好表现。结合 4.1 节的分析,这可能是因为这些类别中大多数样本的文本 token 数在 1000 以内,使视觉 token 的压缩比不超过 $10\times$。对于报纸类文档,则需要 Gundam,甚至 Gundam‑master 模式才能达到可接受的编辑距离,因为报纸的文本 token 数在 4000–5000,远超其他模式的 $10\times$ 压缩范围。这些实验结果进一步展示了上下文光学压缩的边界,并可为 VLM 的视觉 token 优化、以及 LLM 的上下文压缩与遗忘机制研究提供有效参考。
4.3 定性研究
4.3.1 深度解析(Deep parsing)
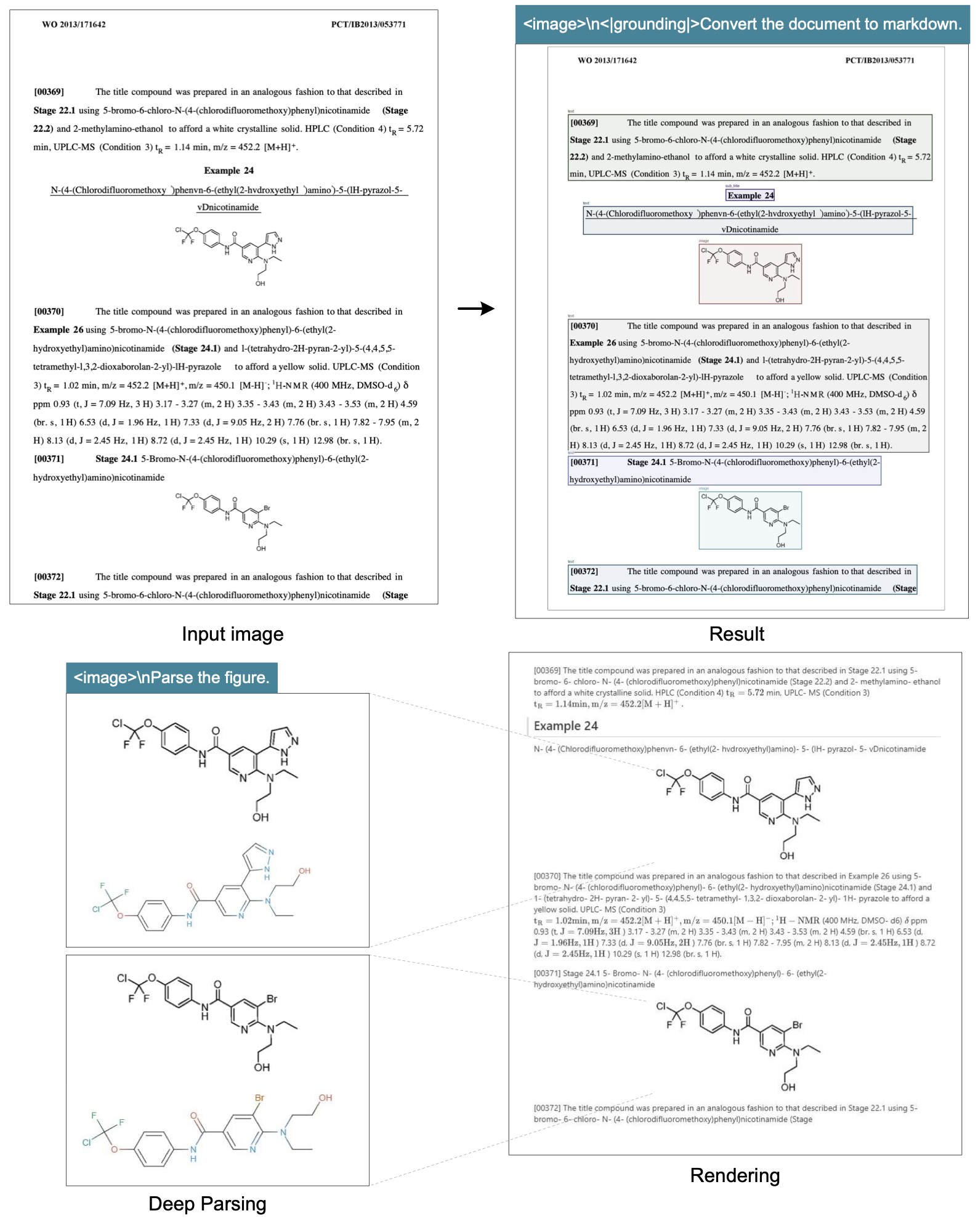
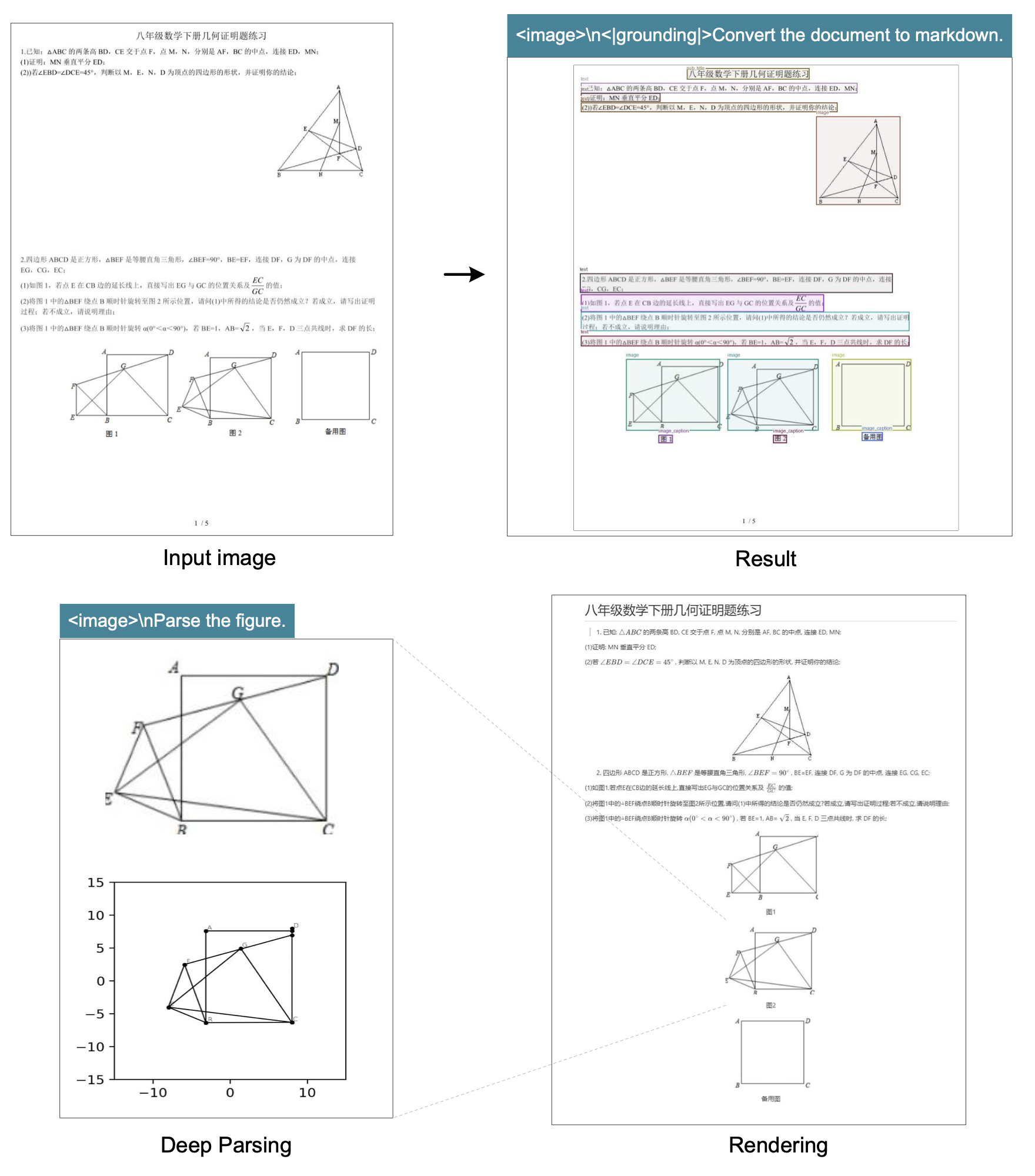
DeepSeek‑OCR 同时具备版面能力与 OCR 2.0 能力,使其可以通过二次模型调用进一步解析文档内的图像,我们将该特性称为“深度解析(deep parsing)”。如图 7–10 所示,我们的模型仅需统一 prompt,便可对图表、几何、化学式乃至自然图像进行深度解析。


4.3.2 多语言识别
互联网 PDF 数据不仅包含中文与英文,还包含大量多语言数据,这在训练 LLM 时同样关键。对于 PDF 文档,DeepSeek‑OCR 可处理近 100 种语言。与中文和英文文档类似,多语言数据也同时支持带布局与不带布局的 OCR 输出格式。图 11 给出可视化结果,我们选择阿拉伯语与僧伽罗语(Sinhala)进行展示。

4.3.3 通用视觉理解
我们也为 DeepSeek‑OCR 提供了一定程度的通用图像理解能力,相关可视化结果见图 12。

5. 讨论
我们的工作是对视觉‑文本压缩边界的一次初步探索,核心问题是:要解码 $N$ 个文本 token,需要多少视觉 token?初步结果令人鼓舞:在约 $10\times$ 压缩比下,DeepSeek‑OCR 可实现近无损 OCR 压缩;在 $20\times$ 压缩时仍可保留约 60% 的准确率。这些发现为未来应用提供了方向,例如在多轮对话中,对超过 $k$ 轮的历史对话做光学处理,从而达到 $10\times$ 的压缩效率。
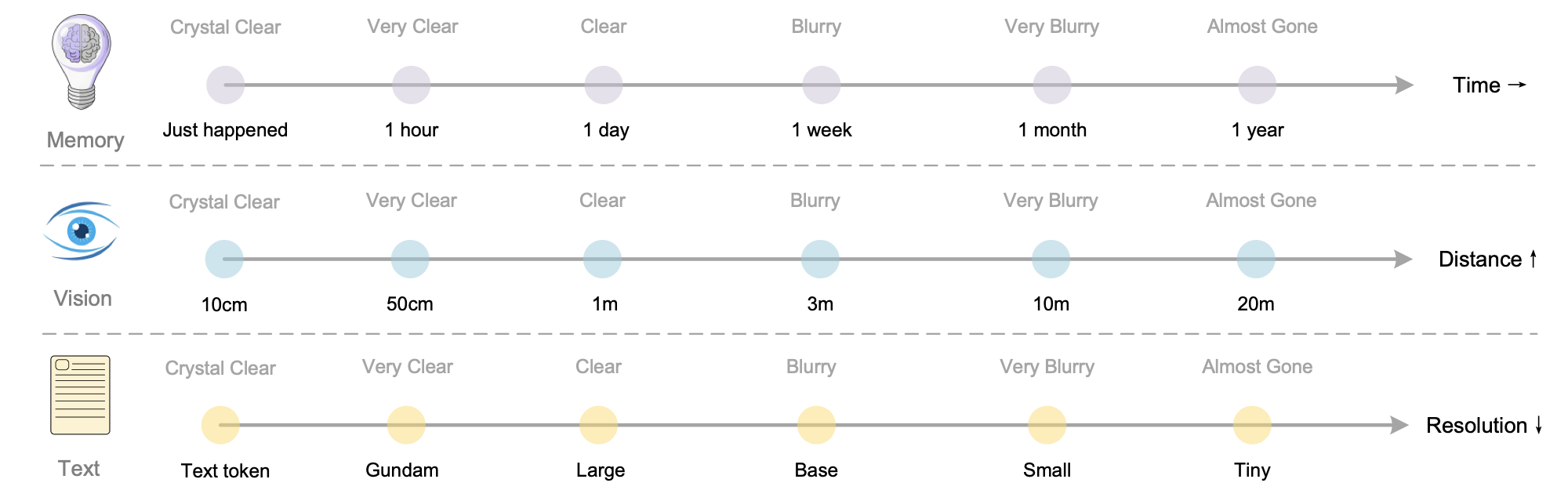
对于更久远的上下文,我们可以逐步缩小渲染图像的尺寸以进一步降低 token 消耗。这一假设来自人类记忆随时间衰减与视觉感知随空间距离退化之间的自然类比——二者都呈现相似的渐进式信息损失模式,如图 13 所示。将这些机制结合后,上下文光学压缩可实现一种更接近生物遗忘曲线的“记忆衰减”:近期信息保持高保真,而久远记忆则通过更高压缩比自然淡化。
尽管我们的初步探索展示了可扩展的超长上下文处理潜力(近期上下文保持高分辨率、远期上下文消耗更少资源),但我们也承认这仍是早期工作,需要进一步研究。该方法为“理论上无限上下文”的架构提供了一条可能路径:在计算约束下平衡信息保留与资源消耗;但此类视觉‑文本压缩系统的实际影响与局限仍有待后续更深入的研究。
6. 结论
在本技术报告中,我们提出 DeepSeek‑OCR,并对上下文光学压缩的可行性做了初步验证:该模型能够从较少的视觉 token 中有效解码出超过其 10 倍数量的文本 token。我们相信这一发现将推动未来 VLM 与 LLM 的发展。此外,DeepSeek‑OCR 也是一个高度实用的模型,能够进行大规模预训练数据生产,成为 LLM 不可或缺的助手。当然,仅用 OCR 仍不足以完全验证真正的上下文光学压缩;我们未来将开展数字‑光学文本交错预训练(digital‑optical text interleaved pretraining)、needle‑in‑a‑haystack 测试等更多评估。从另一个角度看,上下文光学压缩仍有大量研究与改进空间,是一个值得投入的全新方向。
参考文献
- Marker. URL https://github.com/datalab-to/marker.
- Mathpix. URL https://mathpix.com/.
- OCRFlux, 2025. URL https://github.com/chatdoc-com/OCRFlux.
- G. AI. Gemini 2.5‑pro, 2025. URL https://gemini.google.com/.
- S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y. Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y. Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin. Qwen2.5‑vl technical report. arXiv preprint arXiv:2502.13923, 2025.
- L. Blecher, G. Cucurull, T. Scialom, and R. Stojnic. Nougat: Neural optical understanding for academic documents. arXiv preprint arXiv:2308.13418, 2023.
- J. Chen, L. Kong, H. Wei, C. Liu, Z. Ge, L. Zhao, J. Sun, C. Han, and X. Zhang. OneChart: Purify the chart structural extraction via one auxiliary token. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 147–155, 2024.
- Z. Chen, W. Wang, H. Tian, S. Ye, Z. Gao, E. Cui, W. Tong, K. Hu, J. Luo, Z. Ma, et al. How far are we to GPT‑4V? Closing the gap to commercial multimodal models with open‑source suites. arXiv preprint arXiv:2404.16821, 2024.
- C. Cui, T. Sun, M. Lin, T. Gao, Y. Zhang, J. Liu, X. Wang, Z. Zhang, C. Zhou, H. Liu, et al. PaddleOCR 3.0 technical report. arXiv preprint arXiv:2507.05595, 2025.
- M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin, et al. Patch n’ pack: NaViT, a vision transformer for any aspect ratio and resolution. Advances in Neural Information Processing Systems, 36:3632–3656, 2023.
- H. Feng, S. Wei, X. Fei, W. Shi, Y. Han, L. Liao, J. Lu, B. Wu, Q. Liu, C. Lin, et al. Dolphin: Document image parsing via heterogeneous anchor prompting. arXiv preprint arXiv:2505.14059, 2025.
- Y. Goyal, T. Khot, D. Summers‑Stay, D. Batra, and D. Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913, 2017.
- J. Gu, X. Meng, G. Lu, L. Hou, N. Minzhe, X. Liang, L. Yao, R. Huang, W. Zhang, X. Jiang, et al. Wukong: A 100 million large‑scale Chinese cross‑modal pre‑training benchmark. Advances in Neural Information Processing Systems, 35:26418–26431, 2022.
- High‑flyer. HAI‑LLM: Efficient and lightweight training tool for large models, 2023. URL https://www.high-flyer.cn/en/blog/hai-llm.
- S. Iyer, X. V. Lin, R. Pasunuru, T. Mihaylov, D. Simig, P. Yu, K. Shuster, T. Wang, Q. Liu, P. S. Koura, et al. OPT‑IML: Scaling language model instruction meta learning through the lens of generalization. arXiv preprint arXiv:2212.12017, 2022.
- S. Kazemzadeh, V. Ordonez, M. Matten, and T. Berg. ReferItGame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, pages 787–798, 2014.
- A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.‑Y. Lo, et al. Segment Anything. arXiv preprint arXiv:2304.02643, 2023.
- Z. Li, Y. Liu, Q. Liu, Z. Ma, Z. Zhang, S. Zhang, Z. Guo, J. Zhang, X. Wang, and X. Bai. MonkeyOCR: Document parsing with a structure‑recognition‑relation triplet paradigm. arXiv preprint arXiv:2506.05769, 2025.
- A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Deng, C. Ruan, D. Dai, D. Guo, et al. DeepSeek‑V2: A strong, economical, and efficient mixture‑of‑experts language model. arXiv preprint arXiv:2405.04434, 2024.
- A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. DeepSeek‑V3 technical report. arXiv preprint arXiv:2412.19437, 2024.
- C. Liu, H. Wei, J. Chen, L. Kong, Z. Ge, Z. Zhu, L. Zhao, J. Sun, C. Han, and X. Zhang. Focus anywhere for fine‑grained multi‑page document understanding. arXiv preprint arXiv:2405.14295, 2024.
- I. Loshchilov and F. Hutter. SGDR: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- A. Masry, D. X. Long, J. Q. Tan, S. Joty, and E. Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. arXiv preprint arXiv:2203.10244, 2022.
- A. Nassar, A. Marafioti, M. Omenetti, M. Lysak, N. Livathinos, C. Auer, L. Morin, R. T. de Lima, Y. Kim, A. S. Gurbuz, et al. SmolDocling: An ultra‑compact vision‑language model for end‑to‑end multi‑modal document conversion. arXiv preprint arXiv:2502.18443, 2025.
- OpenAI. GPT‑4 technical report, 2023.
- L. Ouyang, Y. Qu, H. Zhou, J. Zhu, R. Zhang, Q. Lin, B. Wang, Z. Zhao, M. Jiang, X. Zhao, et al. OmniDocBench: Benchmarking diverse PDF document parsing with comprehensive annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025.
- J. Poznanski, A. Rangapur, J. Borchardt, J. Dunkelberger, R. Huff, D. Lin, C. Wilhelm, K. Lo, and L. Soldaini. OLMOCR: Unlocking trillions of tokens in PDFs with vision language models. arXiv preprint arXiv:2502.18443, 2025.
- A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- Rednote. dots.ocr, 2025. URL https://github.com/rednote-hilab/dots.ocr.
- C. Schuhmann, R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki. LAION‑400M: Open dataset of CLIP‑filtered 400 million image‑text pairs. arXiv preprint arXiv:2111.02114, 2021.
- A. Singh, V. Natarajan, M. Shah, Y. Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach. Towards VQA models that can read. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8317–8326, 2019.
- T. Sun, C. Cui, Y. Du, and Y. Liu. PP‑DocLayout: A unified document layout detection model to accelerate large‑scale data construction. arXiv preprint arXiv:2503.17213, 2025.
- B. Wang, C. Xu, X. Zhao, L. Ouyang, F. Wu, Z. Zhao, R. Xu, K. Liu, Y. Qu, F. Shang, et al. MinerU: An open‑source solution for precise document content extraction. arXiv preprint arXiv:2409.18839, 2024.
- P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al. Qwen2‑VL: Enhancing vision‑language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024.
- H. Wei, L. Kong, J. Chen, L. Zhao, Z. Ge, J. Yang, J. Sun, C. Han, and X. Zhang. Vary: Scaling up the vision vocabulary for large vision‑language model. In European Conference on Computer Vision, pages 408–424. Springer, 2024.
- H. Wei, L. Kong, J. Chen, L. Zhao, Z. Ge, E. Yu, J. Sun, C. Han, and X. Zhang. Small language model meets with reinforced vision vocabulary. arXiv preprint arXiv:2401.12503, 2024.
- H. Wei, C. Liu, J. Chen, J. Wang, L. Kong, Y. Xu, Z. Ge, L. Zhao, J. Sun, Y. Peng, et al. General OCR theory: Towards OCR‑2.0 via a unified end‑to‑end model. arXiv preprint arXiv:2409.01704, 2024.
- H. Wei, Y. Yin, Y. Li, J. Wang, L. Zhao, J. Sun, Z. Ge, X. Zhang, and D. Jiang. Slow Perception: Let’s perceive geometric figures step‑by‑step. arXiv preprint arXiv:2412.20631, 2024.
- Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y. Ma, C. Wu, B. Wang, et al. DeepSeek‑VL2: Mixture‑of‑experts vision‑language models for advanced multimodal understanding. arXiv preprint arXiv:2412.10302, 2024.
- W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, and L. Wang. MM‑VET: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023.
- J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y. Duan, W. Su, J. Shao, et al. InternVL3: Exploring advanced training and test‑time recipes for open‑source multimodal models. arXiv preprint arXiv:2504.10479, 2025.
- Marker. URL https://github.com/datalab-to/marker.
- Mathpix. URL https://mathpix.com/.
- Ocrflux, 2025. URL https://github.com/chatdoc-com/OCRFlux.
- G. AI. Gemini 2.5-pro, 2025. URL https://gemini.google.com/.
- S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y. Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y. Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923, 2025.
- L. Blecher, G. Cucurull, T. Scialom, and R. Stojnic. Nougat: Neural optical understanding for academic documents. arXiv preprint arXiv:2308.13418, 2023.
- J. Chen, L. Kong, H. Wei, C. Liu, Z. Ge, L. Zhao, J. Sun, C. Han, and X. Zhang. Onechart: Purify the chart structural extraction via one auxiliary token. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 147--155, 2024a.
- Z. Chen, W. Wang, H. Tian, S. Ye, Z. Gao, E. Cui, W. Tong, K. Hu, J. Luo, Z. Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821, 2024b.
- C. Cui, T. Sun, M. Lin, T. Gao, Y. Zhang, J. Liu, X. Wang, Z. Zhang, C. Zhou, H. Liu, et al. Paddleocr 3.0 technical report. arXiv preprint arXiv:2507.05595, 2025.
- M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin, et al. Patch n' pack: Navit, a vision transformer for any aspect ratio and resolution. Advances in Neural Information Processing Systems, 36: 3632--3656, 2023.
- H. Feng, S. Wei, X. Fei, W. Shi, Y. Han, L. Liao, J. Lu, B. Wu, Q. Liu, C. Lin, et al. Dolphin: Document image parsing via heterogeneous anchor prompting. arXiv preprint arXiv:2505.14059, 2025.
- Y. Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6904--6913, 2017.
- J. Gu, X. Meng, G. Lu, L. Hou, N. Minzhe, X. Liang, L. Yao, R. Huang, W. Zhang, X. Jiang, et al. Wukong: A 100 million large-scale chinese cross-modal pre-training benchmark. Advances in Neural Information Processing Systems, 35: 26418--26431, 2022.
- High-flyer. HAI-LLM: Efficient and lightweight training tool for large models, 2023. URL https://www.high-flyer.cn/en/blog/hai-llm.
- S. Iyer, X. V. Lin, R. Pasunuru, T. Mihaylov, D. Simig, P. Yu, K. Shuster, T. Wang, Q. Liu, P. S. Koura, et al. Opt-iml: Scaling language model instruction meta learning through the lens of generalization. arXiv preprint arXiv:2212.12017, 2022.
- S. Kazemzadeh, V. Ordonez, M. Matten, and T. Berg. Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787--798, 2014.
- A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- Z. Li, Y. Liu, Q. Liu, Z. Ma, Z. Zhang, S. Zhang, Z. Guo, J. Zhang, X. Wang, and X. Bai. Monkeyocr: Document parsing with a structure-recognition-relation triplet paradigm. arXiv preprint arXiv:2506.05218, 2025.
- A. Liu, B. Feng, B. Wang, B. Wang, B. Liu, C. Zhao, C. Dengr, C. Ruan, D. Dai, D. Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434, 2024a.
- A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024b.
- C. Liu, H. Wei, J. Chen, L. Kong, Z. Ge, Z. Zhu, L. Zhao, J. Sun, C. Han, and X. Zhang. Focus anywhere for fine-grained multi-page document understanding. arXiv preprint arXiv:2405.14295, 2024c.
- I. Loshchilov and F. Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- A. Masry, D. X. Long, J. Q. Tan, S. Joty, and E. Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. arXiv preprint arXiv:2203.10244, 2022.
- A. Nassar, A. Marafioti, M. Omenetti, M. Lysak, N. Livathinos, C. Auer, L. Morin, R. T. de Lima, Y. Kim, A. S. Gurbuz, et al. Smoldocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion. arXiv preprint arXiv:2503.11576, 2025.
- OpenAI. Gpt-4 technical report, 2023.
- L. Ouyang, Y. Qu, H. Zhou, J. Zhu, R. Zhang, Q. Lin, B. Wang, Z. Zhao, M. Jiang, X. Zhao, et al. Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24838--24848, 2025.
- J. Poznanski, A. Rangapur, J. Borchardt, J. Dunkelberger, R. Huff, D. Lin, C. Wilhelm, K. Lo, and L. Soldaini. olmocr: Unlocking trillions of tokens in pdfs with vision language models. arXiv preprint arXiv:2502.18443, 2025.
- A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PMLR, 2021.
- Rednote. dots.ocr, 2025. URL https://github.com/rednote-hilab/dots.ocr.
- C. Schuhmann, R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- A. Singh, V. Natarajan, M. Shah, Y. Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317--8326, 2019.
- T. Sun, C. Cui, Y. Du, and Y. Liu. Pp-doclayout: A unified document layout detection model to accelerate large-scale data construction. arXiv preprint arXiv:2503.17213, 2025.
- B. Wang, C. Xu, X. Zhao, L. Ouyang, F. Wu, Z. Zhao, R. Xu, K. Liu, Y. Qu, F. Shang, et al. Mineru: An open-source solution for precise document content extraction. arXiv preprint arXiv:2409.18839, 2024a.
- P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024b.
- H. Wei, L. Kong, J. Chen, L. Zhao, Z. Ge, J. Yang, J. Sun, C. Han, and X. Zhang. Vary: Scaling up the vision vocabulary for large vision-language model. In European Conference on Computer Vision, pages 408--424. Springer, 2024a.
- H. Wei, L. Kong, J. Chen, L. Zhao, Z. Ge, E. Yu, J. Sun, C. Han, and X. Zhang. Small language model meets with reinforced vision vocabulary. arXiv preprint arXiv:2401.12503, 2024b.
- H. Wei, C. Liu, J. Chen, J. Wang, L. Kong, Y. Xu, Z. Ge, L. Zhao, J. Sun, Y. Peng, et al. General ocr theory: Towards ocr-2.0 via a unified end-to-end model. arXiv preprint arXiv:2409.01704, 2024c.
- H. Wei, Y. Yin, Y. Li, J. Wang, L. Zhao, J. Sun, Z. Ge, X. Zhang, and D. Jiang. Slow perception: Let's perceive geometric figures step-by-step. arXiv preprint arXiv:2412.20631, 2024d.
- Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y. Ma, C. Wu, B. Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding. arXiv preprint arXiv:2412.10302, 2024.
- W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, and L. Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023.
- J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y. Duan, W. Su, J. Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025.