DeepSeek‑V3.2:推动开源大语言模型前沿
DeepSeek‑V3.2: Pushing the Frontier of Open Large Language Models
摘要
我们提出 DeepSeek‑V3.2:一个在高计算效率与卓越推理/智能体(agent)性能之间实现协同的模型。DeepSeek‑V3.2 的关键技术突破包括:
- DeepSeek 稀疏注意力(DeepSeek Sparse Attention, DSA):我们提出一种高效注意力机制,在长上下文场景中显著降低计算复杂度,同时保持模型性能。
- 可扩展的强化学习框架:通过实现稳健的强化学习(RL)训练协议并扩展后训练计算量,DeepSeek‑V3.2 的表现可与 GPT‑5 相当。值得注意的是,我们的高算力变体 DeepSeek‑V3.2‑Speciale 超越 GPT‑5,并展现出与 Gemini‑3.0‑Pro 同等级的推理能力,在 2025 年国际数学奥林匹克(IMO)与国际信息学奥林匹克(IOI)中均达到金牌水平。
- 大规模智能体任务合成流水线:为将推理能力融入工具使用场景,我们开发了一套新的合成流水线,可在大规模上系统性地产生训练数据。该方法支持可扩展的智能体后训练,在复杂交互环境中的泛化能力与指令遵循鲁棒性上带来显著提升。
基准对比(图)

1. 引言
推理模型的出现[1,2] 是大语言模型(LLM)演进中的关键节点,它在可验证领域推动了整体性能的显著跃迁。自此之后,LLM 能力迅速提升。然而在过去几个月里,一个明显的分化趋势逐渐显现:开源社区虽持续进步[3–6],但闭源专有模型[7–9] 的性能曲线以更陡峭的速度加速上升。结果是,闭源与开源之间的差距并未收敛,反而呈现扩大的趋势;专有系统在复杂任务上的优势愈加明显。
通过分析,我们识别出限制开源模型在复杂任务上能力的三项关键短板。第一,在架构层面,主流仍依赖原始(vanilla)注意力机制[10],这会在长序列场景中严重限制效率,从而对可扩展部署与有效后训练造成显著阻碍。第二,在资源投入上,开源模型的后训练阶段计算投入不足,使得其在高难度任务上的性能受限。第三,在 AI 智能体场景中,相比专有模型,开源模型在泛化与指令遵循方面存在明显滞后[11–13],从而削弱其在真实部署中的效果。
为应对这些限制,我们提出三方面改进。首先,我们提出 DSA:一种高效注意力机制,用以显著降低计算复杂度,并在长上下文场景中保持性能。其次,我们构建稳定且可扩展的 RL 训练协议,使后训练阶段可以显著扩展计算预算;尤其值得强调的是,该框架的后训练计算预算超过预训练成本的 10%,从而解锁更高级能力。第三,我们提出一条新的流水线,用于在工具使用场景中培育可泛化的推理能力:我们先采用 DeepSeek‑V3 方法[14] 实施冷启动,将推理与工具使用统一到同一条轨迹中;随后进入大规模智能体任务合成阶段,生成 1,800+ 个不同环境与 85,000+ 个复杂提示。基于这些合成数据进行 RL,可显著提升模型在智能体场景中的泛化与指令遵循能力。
DeepSeek‑V3.2 在多个推理基准上与 Kimi‑K2‑Thinking 和 GPT‑5 表现相近;同时,它显著提升了开源模型的智能体能力,在 MCP 相关长尾智能体任务上表现突出[11–13]。在智能体场景中,DeepSeek‑V3.2 以显著更低成本逼近前沿闭源模型的能力,明显缩小了开源与专有前沿模型之间的差距。
此外,为进一步推动开源模型在推理领域的上限,我们放宽输出长度约束,构建了 DeepSeek‑V3.2‑Speciale。该模型在性能上可与领先闭源系统 Gemini‑3.0‑Pro[15] 持平,并在 IOI 2025、ICPC 世界总决赛 2025、IMO 2025 与 CMO 2025 达到金牌水平。
2. 架构
本节介绍 DeepSeek‑V3.2 的模型架构与关键组件。DeepSeek‑V3.2 采用与 DeepSeek‑V3.2‑Exp 完全相同的架构;相较于上一版本 DeepSeek‑V3.1‑Terminus,DeepSeek‑V3.2 的唯一架构改动是通过持续训练引入 DeepSeek Sparse Attention(DSA)。
2.1 DeepSeek 稀疏注意力(DSA)
DSA 的原型:闪电索引器与细粒度 Token 选择
DSA 的原型主要由两个组件组成:闪电索引器(lightning indexer)与细粒度 token 选择机制。
闪电索引器计算查询 token $\mathbf{h}_t \in \mathbb{R}^{d}$ 与历史 token $\mathbf{h}_s \in \mathbb{R}^{d}$ 之间的索引得分 $I_{t,s}$,用于决定该查询 token 需要选择哪些历史 token:
其中 $H^{I}$ 为索引器 head 数;$\mathbf{q}^{I}_{t,j} \in \mathbb{R}^{d^{I}}$ 与 $w^I_{t,j} \in \mathbb{R}$ 由查询 token $\mathbf{h}_t$ 生成;$\mathbf{k}^{I}_{s} \in \mathbb{R}^{d^{I}}$ 由历史 token $\mathbf{h}_s$ 生成。出于吞吐考虑,我们选择 ReLU 作为激活函数。由于闪电索引器 head 数较少且可用 FP8 实现,其计算效率非常高。
在获得每个查询 token 的索引得分集合 $\{I_{t,s}\}$ 后,细粒度 token 选择机制仅检索 Top‑k 索引得分对应的键值条目(key‑value entries)$\{\mathbf{c}_s\}$,并在稀疏选择的键值条目上计算注意力输出 $\mathbf{u}_t$:
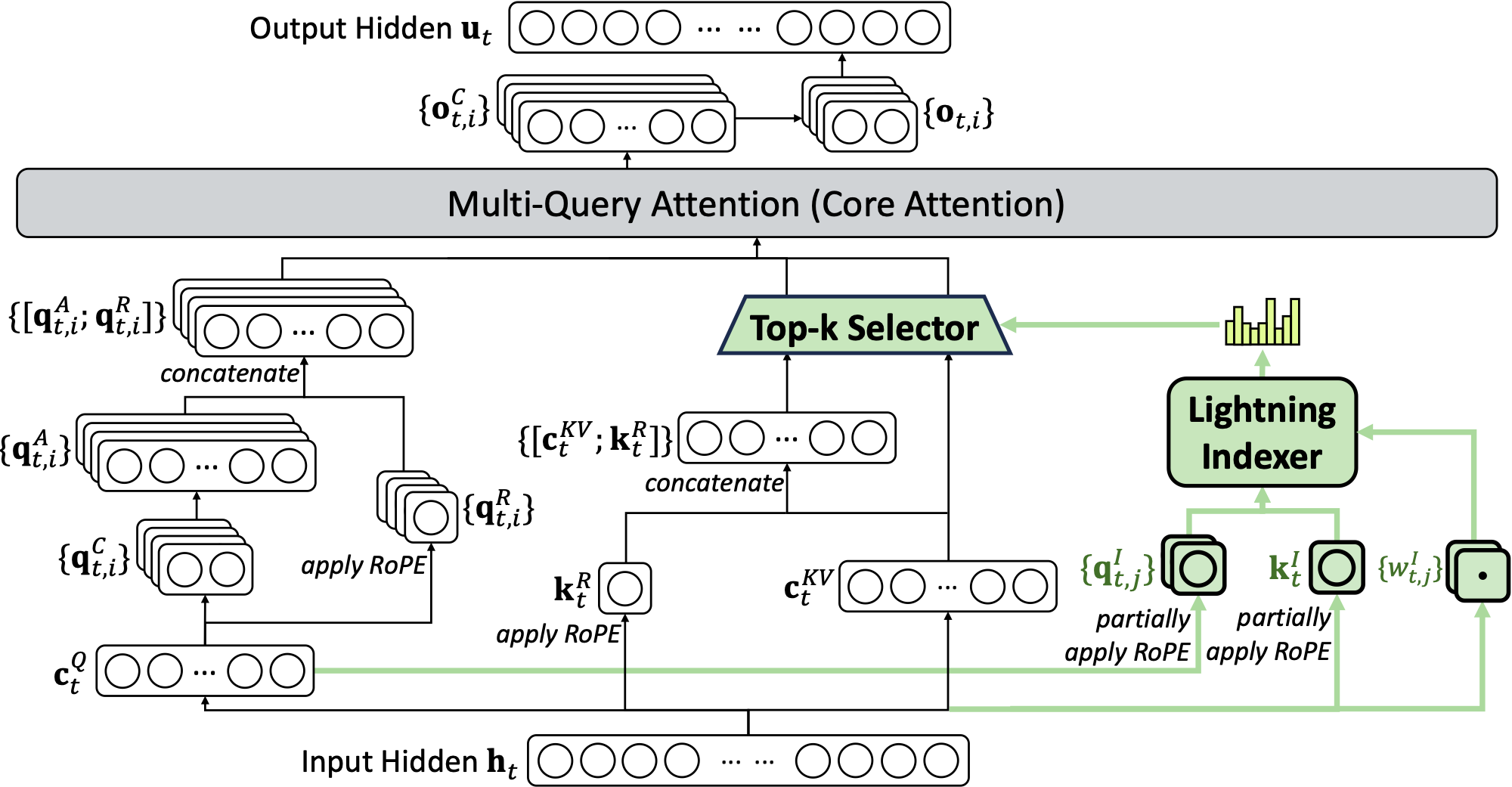
在 MLA 下实例化 DSA
为便于从 DeepSeek‑V3.1‑Terminus 进行持续训练,我们基于 MLA[16] 为 DeepSeek‑V3.2 实例化 DSA。在 kernel 层面,为提升计算效率,每个键值条目需要在多个 query 之间共享[17]。因此,我们在 MLA 的 MQA 模式[18] 下实现 DSA(附录 A 对比 MLA 的 MQA 与 MHA 模式),其中每个潜在向量(MLA 的 key‑value 条目)会在该查询 token 的所有 query head 之间共享。图 2 展示了基于 MLA 的 DSA 结构。我们同时提供了 DeepSeek‑V3.2 的开源实现以明确细节:Hugging Face 推理实现。
2.2 续训预训练
我们从 DeepSeek‑V3.1‑Terminus 的一个基础 checkpoint 开始,该 checkpoint 已将上下文长度扩展到 128K。随后进行续训预训练并接着进行后训练,从而得到 DeepSeek‑V3.2。
续训预训练包含两个阶段,且两阶段的训练数据分布均与 DeepSeek‑V3.1‑Terminus 的 128K 长上下文扩展数据完全对齐。
稠密热身阶段(Dense Warm‑up Stage)
我们首先用一个短的热身阶段初始化闪电索引器。在该阶段中,我们保持稠密注意力(dense attention),冻结除闪电索引器之外的全部模型参数。为使索引器输出与主注意力分布对齐,对于第 $t$ 个 query token,我们先在所有注意力 head 上对主注意力分数求和,再在序列维度上做 L1 归一化得到目标分布 $p_{t,:} \in \mathbb{R}^{t}$。基于该目标分布,我们以 KL 散度作为索引器训练目标:
热身阶段学习率设为 $10^{-3}$。我们仅训练索引器 1000 步,每步包含 16 条长度 128K 的序列,总计 2.1B tokens。
稀疏训练阶段(Sparse Training Stage)
在索引器热身之后,我们引入细粒度 token 选择机制,并优化所有模型参数,使模型适应 DSA 的稀疏模式。在该阶段中,我们仍将索引器输出与主注意力分布对齐,但仅在被选择的 token 集合上计算:
需要指出的是,我们将索引器输入从计算图中分离以便进行独立优化:索引器仅从 $\mathcal{L}^{I}$ 获得训练信号,而主模型仅依据语言建模损失进行优化。在稀疏训练阶段,学习率设为 $7.3\times 10^{-6}$,每个 query token 选择 2048 个 key‑value token。我们对主模型与索引器训练 15000 步,每步包含 480 条长度 128K 的序列,总计 943.7B tokens。
2.3 一致性评估(Parity Evaluation)
标准基准(Standard Benchmark)
在 2025 年 9 月,我们在一组覆盖多种能力的基准上评测 DeepSeek‑V3.2‑Exp,并与 DeepSeek‑V3.1‑Terminus 进行对比,结果显示两者总体性能相近。尽管 DeepSeek‑V3.2‑Exp 在长序列下的计算效率显著提升,但我们未观察到其在短/长上下文任务上的明显性能退化。
人类偏好(Human Preference)
由于直接的人类偏好评估容易受到偏差影响,我们使用 ChatbotArena 作为间接评估框架,以近似用户对新 base 模型的偏好。DeepSeek‑V3.1‑Terminus 与 DeepSeek‑V3.2‑Exp 采用相同的后训练策略;在 2025‑11‑10 的 Elo 评测中,两者得分非常接近。这表明在引入稀疏注意力机制后,新 base 模型仍可达到与上一版本相当的表现。
长上下文评测(Long Context Eval)
DeepSeek‑V3.2‑Exp 发布后,多个独立长上下文评测使用了此前未见的测试集。典型的基准包括 AA‑LCR(链接),DeepSeek‑V3.2‑Exp 在推理模式下比 DeepSeek‑V3.1‑Terminus 高 4 分;在 Fiction.liveBench(链接)中,DeepSeek‑V3.2‑Exp 在多项指标上稳定优于 DeepSeek‑V3.1‑Terminus。这些证据表明 DeepSeek‑V3.2‑Exp 的 base checkpoint 在长上下文任务上并未出现性能回退。
2.4 推理成本(Inference Costs)
DSA 将主模型核心注意力的复杂度从 $\mathcal{O}(L^2)$ 降低到 $\mathcal{O}(Lk)$,其中 $k(\ll L)$ 为被选择 token 的数量。尽管闪电索引器仍具有 $\mathcal{O}(L^2)$ 的复杂度,但与 DeepSeek‑V3.1‑Terminus 中的 MLA 相比,其计算量要小得多。在我们的优化实现下,DSA 在长上下文场景中实现了显著的端到端加速。
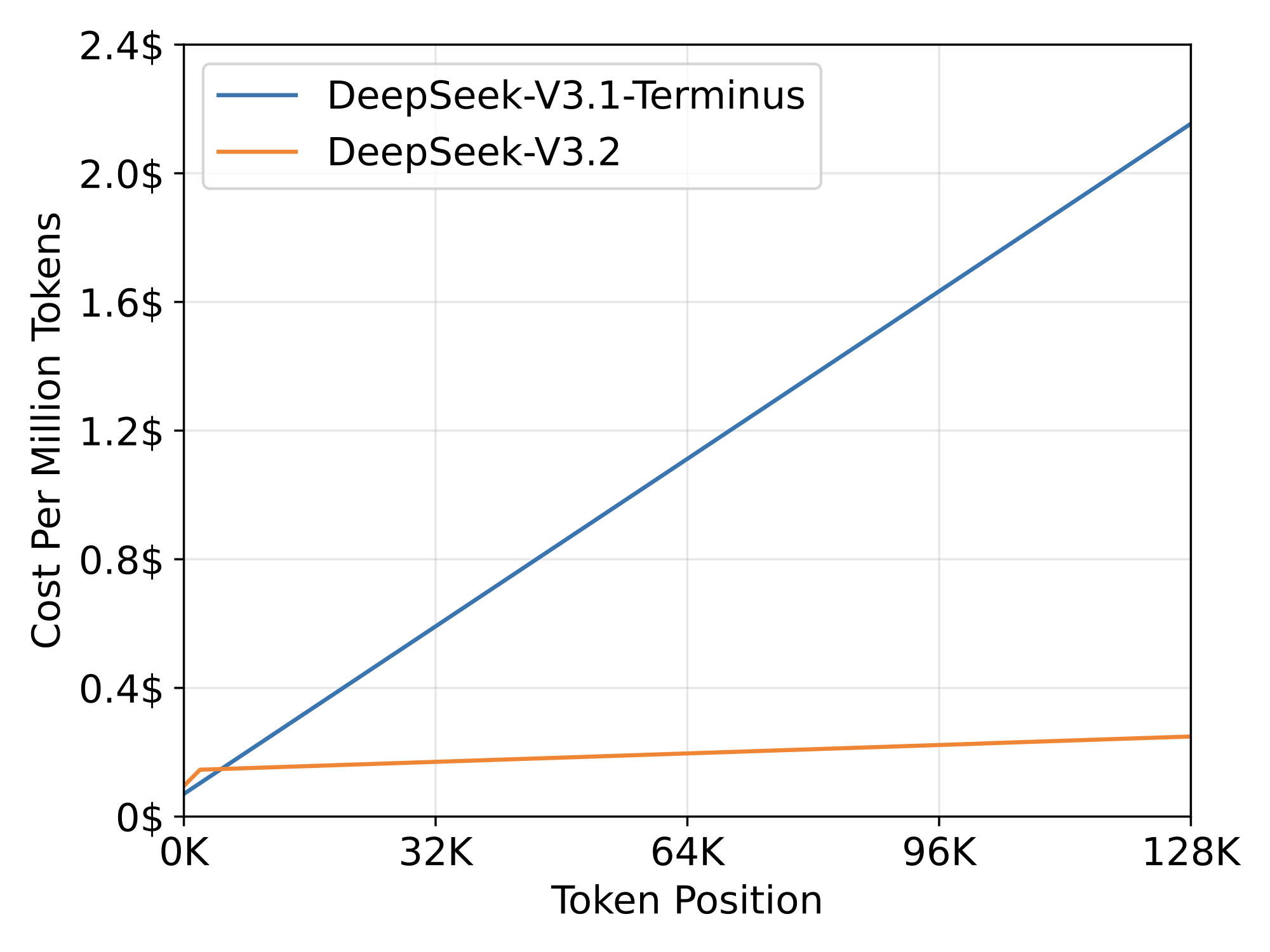
图 3 展示了 DeepSeek‑V3.1‑Terminus 与 DeepSeek‑V3.2 的 token 成本随序列位置的变化。成本估计来自在 H800 GPU 上部署的实际服务基准测试,并以每 GPU 小时 2 美元的租赁价格折算。对于短序列的 prefilling,我们特别实现了 masked MHA 模式来模拟 DSA,以在短上下文条件下获得更高效率。

3. 后训练(Post‑Training)
在续训预训练之后,我们进行后训练以得到最终的 DeepSeek‑V3.2。DeepSeek‑V3.2 的后训练同样采用与稀疏续训预训练阶段一致的稀疏注意力方式。我们保持与 DeepSeek‑V3.2‑Exp 相同的后训练流水线,该流水线包含 专家模型蒸馏(specialist distillation)与混合 RL 训练(mixed RL training)。
专家模型蒸馏(Specialist Distillation)
针对每一类任务,我们首先构建一个专门面向该领域的专家模型,所有专家模型均从同一预训练 DeepSeek‑V3.2 base checkpoint 微调得到。除写作任务与一般问答外,我们的框架还覆盖六个专业域:数学、编程、通用逻辑推理、通用智能体任务、智能体代码、智能体搜索;所有域均支持思考(thinking)与非思考(non‑thinking)两种模式。每个专家都使用大规模 RL 计算进行训练。
此外,我们使用不同模型分别生成长链式思考推理(thinking 模式)与直接作答(non‑thinking 模式)的训练数据。专家模型准备好后,会生成用于最终 checkpoint 的领域数据。实验表明,基于蒸馏数据训练出的模型性能仅略低于对应领域专家,而后续 RL 训练可进一步消除该差距。
混合 RL 训练(Mixed RL Training)
DeepSeek‑V3.2 仍采用 Group Relative Policy Optimization(GRPO)[19,2] 作为 RL 训练算法。与 DeepSeek‑V3.2‑Exp 一样,我们将推理、智能体、人类对齐训练合并到一个 RL 阶段中,从而在多域间有效平衡性能,并避免多阶段训练范式常见的灾难性遗忘问题。针对推理与智能体任务,我们使用基于规则的结果奖励、长度惩罚与语言一致性奖励;针对一般任务,我们使用生成式奖励模型(generative reward model),其中每个提示都包含自己的评估 rubric。
DeepSeek‑V3.2 与 DeepSeek‑V3.2‑Speciale
DeepSeek‑V3.2 融合了由专家蒸馏得到的推理、智能体与人类对齐数据,并在此基础上进行数千步的继续 RL 训练以得到最终 checkpoint。为探索更长思考(extended thinking)的潜力,我们进一步构建了实验变体 DeepSeek‑V3.2‑Speciale:该模型仅在推理数据上训练,并在 RL 中降低长度惩罚;同时引入 DeepSeekMath‑V2[20] 的数据集与奖励方法,以增强数学证明能力。
我们将在 3.1 节 强调如何建立可稳定扩展 RL 计算的训练配方;并在 3.2 节 说明如何将思考能力整合到智能体任务中。
3.1 扩展 GRPO(Scaling GRPO)
我们先回顾 GRPO 的目标函数。GRPO 在每个问题 $q$ 上,从旧策略 $\pi_{\mathrm{old}}$ 采样一组响应 $\{o_1,\ldots,o_G\}$,并通过最大化以下目标来优化策略模型 $\pi_{\theta}$:
其中
是当前策略与旧策略之间的重要性采样比率。$\varepsilon$ 与 $\beta$ 分别控制截断范围与 KL 惩罚强度。$\hat A_{i,t}$ 是对 $o_{i,t}$ 的 advantage,其通过对每组内的结果奖励进行归一化获得:一组奖励模型为每个输出 $o_i$ 打分得到结果奖励 $R_i$,形成 $\boldsymbol{R}=\{R_1,\ldots,R_G\}$;随后通过 $\hat A_{i,t}=R_i-\mathrm{mean}(\boldsymbol{R})$ 计算 advantage。
下面我们在 GRPO 的基础上提出若干额外策略,用以稳定 RL 规模扩展。
无偏 KL 估计(Unbiased KL Estimate)
鉴于 $o_{i,t}$ 来自旧策略 $\pi_{\mathrm{old}}(\cdot\mid q,o_{i,<t})$ 的采样,我们修正 K3 估计器[21],利用当前策略 $\pi_\theta$ 与旧策略 $\pi_{\mathrm{old}}$ 的重要性采样比率获得无偏 KL 估计:
该调整直接带来一个结果:该 KL 估计器的梯度变为无偏,从而消除系统性估计误差并促进稳定收敛。与原始 K3 估计器相比,这一差异在如下情形尤为显著:当采样到的 token 在当前策略下概率远低于参考策略(即 $\pi_\theta \ll \pi_{\mathrm{ref}}$)时,K3 估计器会为这些 token 的似然最大化赋予不成比例、无界的大权重,导致噪声梯度更新,累积后会降低后续迭代中的样本质量并引发训练不稳定。实践中我们发现,不同领域对 KL 正则强度的需求不同;在某些领域(如数学)中,较弱的 KL 惩罚甚至完全去除 KL 惩罚都可能带来更好表现。
离策略序列掩码(Off‑Policy Sequence Masking)
为提高 RL 系统效率,我们通常一次生成大量 rollout 数据,并将其拆分为多个 mini‑batch 进行多次梯度更新。这会引入离策略(off‑policy)行为。此外,高度优化的推理框架在实现细节上往往与训练框架不同,这种训练‑推理不一致会进一步加剧离策略程度。为稳定训练并提升对离策略更新的容忍度,我们将会造成显著策略偏离的负样本序列进行掩码处理,偏离程度用旧策略 $\pi_{\mathrm{old}}$ 与当前策略 $\pi_\theta$ 的 KL 散度度量。具体而言,我们在 GRPO 损失中引入二值掩码 $M$:
其中
$\delta$ 为控制策略偏离阈值的超参数。注意此处 $\pi_{\mathrm{old}}$ 指推理框架直接返回的采样概率,因此旧/新策略的 KL 散度同时涵盖上文提到的两类离策略来源。另一个细节是:我们只掩码 advantage 为负的序列。
直觉上,模型从自身错误中学习收益最大;而高度离策略的负样本可能具有破坏性,可能误导或扰乱优化过程。我们在实验中观察到,该离策略序列掩码操作能在原本会不稳定的训练情形下提升稳定性。
保持路由(Keep Routing)
混合专家(MoE)模型在推理时仅激活少量专家模块,从而提高计算效率。但由于推理与训练框架差异以及策略更新的叠加,即使输入相同,推理与训练中的专家路由也可能不一致。这类不一致会导致活跃参数子空间发生突变,从而使优化不稳定并加剧离策略问题。为缓解这一点,我们保留推理框架采样时使用的专家路由路径,并在训练时强制使用相同路径,从而确保优化的是同一组专家参数。自 DeepSeek‑V3‑0324 起,该“保持路由”操作被证明对 MoE 的 RL 训练稳定性至关重要,并已纳入我们的 RL 训练流水线。
保持采样掩码(Keep Sampling Mask)
Top‑p 与 Top‑k 采样常用于提升 LLM 生成质量。在 RL 训练中采用这些策略也有助于避免采样概率极低的 token(否则会成为优化目标)。然而,这类截断会引入 $\pi_{\mathrm{old}}$ 与 $\pi_\theta$ 的动作空间不一致,从而违背重要性采样原则并导致训练不稳定。为解决该问题,我们保留从 $\pi_{\mathrm{old}}$ 采样时的截断掩码,并在训练时对 $\pi_\theta$ 应用相同掩码,使两种策略共享一致的动作子空间。经验上我们发现,将 Top‑p 与“保持采样掩码”结合能有效维持 RL 训练中的语言一致性。
3.2 工具使用中的思考(Thinking in Tool‑Use)
思考上下文管理(Thinking Context Management)
DeepSeek‑R1 表明,引入思考过程可以显著增强模型解决复杂问题的能力。基于这一启示,我们希望将思考能力整合到工具调用场景中。
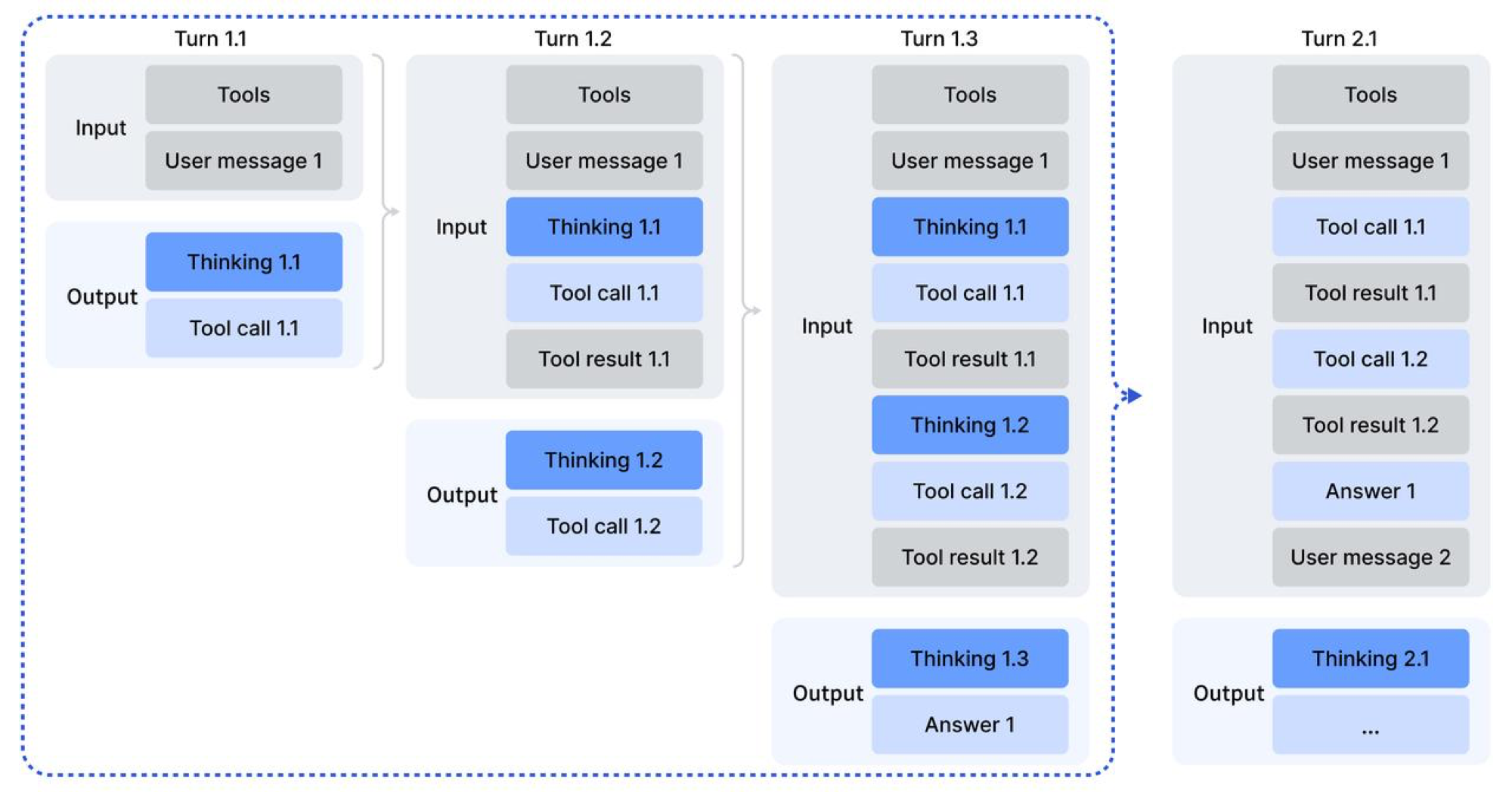
我们观察到,如果直接复用 DeepSeek‑R1 的策略——在收到第二轮消息时丢弃推理内容——会造成显著的 token 低效:模型必须为每一次后续工具调用重新对整个问题进行推理。为此,我们针对工具调用场景开发了严格的上下文管理机制(见图 4):
- 仅当对话中引入新的用户消息(user message)时,才丢弃历史推理内容;若只是追加与工具有关的消息(如工具输出),则在整个交互过程中保留推理内容。
- 当推理轨迹被移除时,仍保留历史的工具调用及其结果。
需要注意的是,一些智能体框架(如 Roo Code 或 Terminus)通过用户消息模拟工具交互,这些框架可能无法完全受益于上述“推理保留”规则。因此,我们建议在此类架构下使用非思考模型以获得最佳表现。
冷启动(Cold‑Start)
鉴于我们既拥有(非智能体)推理数据,又拥有非推理的智能体数据,一种直接的能力融合策略是通过精心设计的提示(prompting)将两者结合。我们假设模型具备足够能力准确遵循显式指令,从而把工具执行无缝嵌入推理过程。
为展示冷启动机制的工作方式,我们在附录表 B.1–B.3 中抽样展示了训练数据。需要注意,不同任务提示对应不同 system prompt。表 B.1–B.3 给出一个与竞赛编程提示相对应的示例:表 B.1 展示推理数据(system prompt 要求模型在最终答案前进行推理,并使用特殊标签 <think></think> 标注推理路径);表 B.2 展示非推理智能体数据(system prompt 包含工具调用指导);表 B.3 展示我们设计的 system prompt,用于指示模型在推理过程中嵌入多次工具调用。
通过这种方式,尽管工具使用模式下的推理可能缺乏鲁棒性,模型仍可在部分样本中生成所需轨迹,为后续强化学习阶段提供基础。
大规模智能体任务(Large‑Scale Agentic Tasks)
多样化的 RL 任务对提升模型鲁棒性至关重要。对于搜索、代码工程与代码解释等任务,我们使用真实世界工具(商业网页搜索 API、编码工具、Jupyter Notebook)。这些 RL 环境是真实的,但提示要么从互联网来源抽取,要么为合成生成,而非来自真实用户交互。对于其他任务,环境与提示均为合成构建。我们使用的智能体任务类型如表 1 所示。
| 任务数量 | 环境 | 提示来源 | |
|---|---|---|---|
| 代码智能体(code agent) | 24,667 | 真实 | 抽取 |
| 搜索智能体(search agent) | 50,275 | 真实 | 合成 |
| 通用智能体(general agent) | 4,417 | 合成 | 合成 |
| 代码解释器(code interpreter) | 5,908 | 真实 | 抽取 |
搜索智能体(Search Agent)
我们基于 DeepSeek‑V3.2 构建了多智能体流水线以生成多样、高质量训练数据。我们先从大规模网络语料中跨领域采样信息量高的长尾实体;问题构造智能体随后使用搜索工具,并以可配置的深度/广度参数探索每个实体,将发现的信息整合为问答对。接着,多回答生成智能体采用异构配置(不同 checkpoint、system prompt 等)为每个问答对生成多样候选答案。带搜索能力的验证智能体通过多轮验证过滤样本,仅保留“ground truth 正确且所有候选答案均可验证为错误”的样本。这些数据覆盖多语言、多领域与多难度层级。
为补充上述可验证样本并更贴近真实使用,我们还从既有的 helpful RL 数据集中筛选出“搜索工具可带来可测量收益”的样本进行增强。随后我们为多个质量维度制定详细 rubric,并用生成式奖励模型按 rubric 为响应评分。该混合方法使模型既能优化事实可靠性,也能优化实际帮助性。
代码智能体(Code Agent)
我们通过挖掘 GitHub 上数百万的 Issue‑Pull Request(PR)配对,构建了大规模可执行的软件问题修复环境。数据集经启发式规则与 LLM 判别严格过滤,要求每条样本包含合理的问题描述、关联的 gold patch,以及用于验证的测试补丁。我们使用由 DeepSeek‑V3.2 驱动的自动化环境搭建智能体来构建可执行环境,该智能体负责包安装、依赖解析与测试执行,并以标准 JUnit 格式输出测试结果以确保跨语言/框架的一致解析。
只有当应用 gold patch 后:假阳性转真阳性(F2P)测试用例数量大于 0(表示问题被修复),且通过转失败(P2F)用例数量为 0(表示无回归),我们才认为环境搭建成功。借助该流水线,我们构建了覆盖 Python、Java、JavaScript、TypeScript、C、C++、Go、PHP 等多语言的数万可复现问题修复环境。
代码解释器智能体(Code Interpreter Agent)
我们使用 Jupyter Notebook 作为代码解释器来解决复杂推理任务。为此,我们整理了涵盖数学、逻辑与数据科学的多样问题集,要求模型通过执行代码来得到答案。
通用智能体(General Agent)
为在 RL 中扩展智能体环境与任务,我们使用自动化环境合成智能体生成 1,827 个面向任务的环境。这些任务“难解但易验”。合成工作流包含环境与工具集构建、任务合成、解答生成三个阶段,具体流程为:
- 给定一个任务类别(如规划旅行路线)与一个带 bash 与搜索工具的沙盒,智能体先使用工具从互联网生成或检索相关数据并写入沙盒数据库。
- 随后智能体合成一组任务专用工具,每个工具以函数形式实现。
- 为生成既具挑战性又可自动验证的任务,智能体会基于当前数据库先提出一个简单任务,并给出其解答函数与验证函数(Python 实现)。解答函数只能调用工具函数或进行逻辑计算,不能调用其他函数或直接访问数据库,从而保证任务必须通过工具接口完成;解答函数的结果必须能被验证函数检验。若验证失败,智能体会修改解答/验证函数直到通过。然后智能体迭代提高任务难度并同步更新解答/验证函数;若当前工具集不足以解决任务,则扩展工具集。
按此流程,我们得到数千个 $\langle\text{environment},\text{tools},\text{task},\text{verifier}\rangle$ 四元组。随后我们在该数据集上对 DeepSeek‑V3.2 进行 RL,并仅保留 pass@100 非零的样本,最终得到 1,827 个环境及其对应任务(合计 4,417 个)。下文给出一个合成的行程规划示例,说明在巨大组合空间中搜索满足全部约束的行程很难,但验证给定候选是否满足约束相对容易。
合成任务示例:行程规划(Trip Planning)
我计划从杭州出发进行三天旅行,需要你帮我生成 2025 年 10 月 1 日到 10 月 3 日的行程安排。
一些重要要求:整个行程中不要重复任何城市、酒店、景点或餐厅;并且确保你推荐的每一家酒店、餐厅和景点确实位于当天我所停留的城市。
另外关于第二天:我希望控制预算。如果我订到每晚价格不低于 800 元的豪华酒店,那么其他开销要更谨慎:两顿正餐(午餐和晚餐)的总花费要低于 350 元,两家餐厅评分都至少 4.0 分,下午的景点门票要低于 120 元。
如果第二天的酒店属于中高档(500–800 元),我就有更大空间:只需保证至少一家餐厅评分 ≥ 4.0,且景点门票低于 180 元。
如果酒店更经济(200–500 元),只需保证至少一家餐厅评分 ≥ 3.2。
你能帮我制定这个行程吗?
提交结果格式:
[
{
\"time\": \"2025-10-01\",
\"city\": \"cite_name\",
\"hotel\": \"hotel_name\",
\"afternoon_restaurant\": \"restaurant_name\",
\"afternoon_attraction\": \"attraction_name\",
\"evening_restaurant\": \"restaurant_name\"
},
{
\"time\": \"2025-10-02\",
\"city\": \"cite_name\",
\"hotel\": \"hotel_name\",
\"afternoon_restaurant\": \"restaurant_name\",
\"afternoon_attraction\": \"attraction_name\",
\"evening_restaurant\": \"restaurant_name\"
},
{
\"time\": \"2025-10-03\",
\"city\": \"cite_name\",
\"hotel\": \"hotel_name\",
\"afternoon_restaurant\": \"restaurant_name\",
\"afternoon_attraction\": \"attraction_name\",
\"evening_restaurant\": \"restaurant_name\"
}
]工具集合:行程规划(Tool Set for Trip Planning)
| 函数名 | 说明 |
|---|---|
get_all_attractions_by_city(city) | 获取指定城市的所有景点。 |
get_all_cities() | 从数据库获取所有城市。 |
get_all_hotels_by_city(city) | 获取指定城市的所有酒店。 |
get_all_restaurants_by_city(city) | 获取指定城市的所有餐厅。 |
get_city_by_attraction(attraction) | 根据景点名获取其所在城市。 |
get_city_by_hotel(hotel) | 根据酒店名获取其所在城市。 |
get_city_by_restaurant(restaurant) | 根据餐厅名获取其所在城市。 |
get_city_transport(city) | 获取指定城市的市内交通选项。 |
get_infos_by_attraction(info_keywords, attraction) | 获取指定景点的特定信息字段。 |
get_infos_by_city(info_keywords, city) | 获取指定城市的特定信息字段。 |
get_infos_by_hotel(info_keywords, hotel) | 获取指定酒店的特定信息字段。 |
get_infos_by_restaurant(info_keywords, restaurant) | 获取指定餐厅的特定信息字段。 |
get_inter_city_transport(from_city, to_city) | 获取两城市之间的交通选项。 |
get_weather_by_city_date(city, date) | 获取指定城市与日期的天气。 |
submit_result(answer_text) | 提交最终答案内容。 |
4. 评测(Evaluation)
4.1 主要结果(Main Results)
我们在如下基准上评测模型:MMLU‑Pro[22]、GPQA Diamond[23]、Human Last Exam(HLE)纯文本[24]、LiveCodeBench(2024.08–2025.04)、Codeforces、Aider‑Polyglot、AIME 2025、HMMT Feb 2025、HMMT Nov 2025[25]、IMOAnswerBench[26]、Terminal Bench 2.0、SWE‑Verified[27]、SWE Multilingual[28]、BrowseComp[29]、BrowseCompZh[30]、$\tau^2$‑bench[31]、MCP‑Universe[12]、MCP‑Mark[11]、Tool‑Decathlon[13]。工具使用类基准使用标准函数调用格式评测,模型配置为思考模式。
对于 MCP‑Universe 与 MCP‑Mark,我们使用内部环境评测所有模型,因为搜索与 playwright 环境可能与官方设置略有差异。我们将温度设为 1.0,上下文窗口设为 128K tokens。对于 AIME、HMMT、IMOAnswerBench 与 HLE 等数学任务,我们使用模板:"{question}\\nPlease reason step by step, and put your final answer within \\boxed{}."。在 HLE 上,我们还使用官方模板评测 DeepSeek‑V3.2‑Thinking,得到 23.9 分。
| Benchmark(指标) | Claude‑4.5‑Sonnet | GPT‑5 High | Gemini‑3.0 Pro | Kimi‑K2 Thinking | MiniMax M2 | DeepSeek‑V3.2 Thinking | |
|---|---|---|---|---|---|---|---|
| English | MMLU‑Pro(EM) | 88.2 | 87.5 | 90.1 | 84.6 | 82.0 | 85.0 |
| GPQA Diamond(Pass@1) | 83.4 | 85.7 | 91.9 | 84.5 | 77.7 | 82.4 | |
| HLE(Pass@1) | 13.7 | 26.3 | 37.7 | 23.9 | 12.5 | 25.1 | |
| Code | LiveCodeBench(Pass@1‑COT) | 64.0 | 84.5 | 90.7 | 82.6 | 83.0 | 83.3 |
| Codeforces(Rating) | 1480 | 2537 | 2708 | – | – | 2386 | |
| Math | AIME 2025(Pass@1) | 87.0 | 94.6 | 95.0 | 94.5 | 78.3 | 93.1 |
| HMMT Feb 2025(Pass@1) | 79.2 | 88.3 | 97.5 | 89.4 | – | 92.5 | |
| HMMT Nov 2025(Pass@1) | 81.7 | 89.2 | 93.3 | 89.2 | – | 90.2 | |
| IMOAnswerBench(Pass@1) | – | 76.0 | 83.3 | 78.6 | – | 78.3 | |
| Code Agent | Terminal Bench 2.0(Acc) | 42.8 | 35.2 | 54.2 | 35.7 | 30.0 | 46.4 |
| SWE Verified(Resolved) | 77.2 | 74.9 | 76.2 | 71.3 | 69.4 | 73.1 | |
| SWE Multilingual(Resolved) | 68.0 | 55.3 | – | 61.1 | 56.5 | 70.2 | |
| Search Agent | BrowseComp(Pass@1) | 24.1 | 54.9 | – | –/60.2* | 44.0 | 51.4/67.6* |
| BrowseCompZh(Pass@1) | 42.4 | 63.0 | – | 62.3 | 48.5 | 65.0 | |
| HLE(Pass@1) | 32.0 | 35.2 | 45.8 | 44.9 | 31.8 | 40.8 | |
| ToolUse | $\tau^2$‑Bench(Pass@1) | 84.7 | 80.2 | 85.4 | 74.3 | 76.9 | 80.3 |
| MCP‑Universe(Success Rate) | 46.5 | 47.9 | 50.7 | 35.6 | 29.4 | 45.9 | |
| MCP‑Mark(Pass@1) | 33.3 | 50.9 | 43.1 | 20.4 | 24.4 | 38.0 | |
| Tool‑Decathlon(Pass@1) | 38.6 | 29.0 | 36.4 | 17.6 | 16.0 | 35.2 |
表 2:DeepSeek‑V3.2 与闭源/开源模型对比。加粗数字表示各类别内最佳(开源/闭源分别比较)。$\tau^2$‑Bench 为各类别平均;BrowseComp 中带 * 的结果使用了上下文管理技术。
整体而言,DeepSeek‑V3.2 在推理任务上与 GPT‑5‑High 表现相近,但略逊于 Gemini‑3.0‑Pro。与 K2‑Thinking 相比,DeepSeek‑V3.2 在保持相近得分的同时使用显著更少的输出 token(见表 3)。这些性能提升可归因于 RL 训练所分配的更高计算资源。过去几个月中,我们观察到随 RL 训练预算扩展(已超过预训练成本的 10%)而持续提升的规律,并推测进一步增加计算预算有望继续增强推理能力。需要注意的是,本文展示的 DeepSeek‑V3.2 性能受到“长度约束奖励模型”的限制;移除该限制后,模型性能会进一步提高(见 4.2 节)。
在代码智能体评测中,DeepSeek‑V3.2 在 SWE‑bench Verified 与 Terminal Bench 2.0 上显著优于开源 LLM,显示其在真实编码工作流中的潜力。对于 Terminal Bench 2.0,由于我们的思考模式上下文管理策略与 Terminus 不兼容,表 2 中的 46.4 分是在 Claude Code 框架下获得。我们也在 Terminus 下以非思考模式评测 DeepSeek‑V3.2,得到 39.3 分。SWE‑bench Verified 的主分数来自内部框架;在 Claude Code 与 RooCode 等其他设置以及非思考模式下的鲁棒性测试也保持一致,分数范围为 72–74。
在搜索智能体评测中,我们用标准商业搜索 API 评测模型。由于 DeepSeek‑V3.2 最大上下文长度仅 128K,约 20%+ 的测试用例超过该限制;我们通过上下文管理方法得到最终分数。作为对照,不采用上下文管理时分数为 51.4(详见 4.4 节)。
在工具使用基准上,DeepSeek‑V3.2 显著缩小了开源与闭源 LLM 的差距,但仍低于前沿模型。对于 $\tau^2$‑bench,我们使用模型自身作为用户智能体,最终在各类别取得 63.8(Airline)、81.1(Retail)、96.2(Telecom)。对于 MCP 基准,我们采用函数调用格式,并将工具输出放入 role 为 tool 的消息,而不是 user。测试中我们观察到 DeepSeek‑V3.2 常进行冗余自验证,生成过长轨迹,导致在 MCP‑Mark GitHub 与 Playwright 等任务上容易超过 128K 限制并影响最终性能;引入上下文管理策略可进一步提升表现。我们将其视为未来工作方向与用户实践中的重要考虑。即便如此,DeepSeek‑V3.2 仍明显优于现有开源模型。
值得强调的是,这些工具使用基准中的环境与工具集并未在 RL 训练中出现,因此性能提升表明 DeepSeek‑V3.2 能将推理策略泛化到域外(out‑of‑domain)的智能体场景中。非思考模式在智能体场景下的评测结果见附录表 C.1。
4.2 高算力变体:DeepSeek‑V3.2‑Speciale
表 3 展示了不同推理模型的基准表现与效率。每个基准单元格同时报告准确率与输出 token 数(千为单位)。每列最高准确率加粗,次高以下划线表示。
| Benchmark | GPT‑5 High | Gemini‑3.0 Pro | Kimi‑K2 Thinking | DeepSeek‑V3.2 Thinking | DeepSeek‑V3.2 Speciale |
|---|---|---|---|---|---|
| AIME 2025(Pass@1) | 94.6(13k) | 95.0(15k) | 94.5(24k) | 93.1(16k) | 96.0(23k) |
| HMMT Feb 2025(Pass@1) | 88.3(16k) | 97.5(16k) | 89.4(31k) | 92.5(19k) | 99.2(27k) |
| HMMT Nov 2025(Pass@1) | 89.2(20k) | 93.3(15k) | 89.2(29k) | 90.2(18k) | 94.4(25k) |
| IMOAnswerBench(Pass@1) | 76.0(31k) | 83.3(18k) | 78.6(37k) | 78.3(27k) | 84.5(45k) |
| LiveCodeBench(Pass@1‑COT) | 84.5(13k) | 90.7(13k) | 82.6(29k) | 83.3(16k) | 88.7(27k) |
| CodeForces(Rating) | 2537(29k) | 2708(22k) | – | 2386(42k) | 2701(77k) |
| GPQA Diamond(Pass@1) | 85.7(8k) | 91.9(8k) | 84.5(12k) | 82.4(7k) | 85.7(16k) |
| HLE(Pass@1) | 26.3(15k) | 37.7(15k) | 23.9(24k) | 25.1(21k) | 30.6(35k) |
表 3:推理模型的性能与输出 token 效率对比。
表 3 显示,DeepSeek‑V3.2‑Speciale 通过使用更多推理 token 获得更强性能,并在多个基准上超过 Gemini‑3.0‑Pro。更进一步,如表 4 所示,该通用模型无需定向训练即可在 2025 IOI 与 ICPC 世界总决赛达到金牌水平;此外,通过引入 DeepSeekMath‑V2[20] 的技术,该模型在 2025 IMO 与 CMO 的复杂证明题上也达到金牌阈值(我们评测的是 CMO 2025 的英文版;题目与推理代码见:DeepSeek‑Math‑V2 仓库)。详细评测协议见附录 D。
与此同时,DeepSeek‑V3.2‑Speciale 的 token 效率仍显著弱于 Gemini‑3.0‑Pro。为降低部署成本与时延,我们在官方 DeepSeek‑V3.2 的训练中施加更严格的 token 约束,旨在优化性能‑成本权衡。我们认为 token 效率仍是未来的重要研究方向。
| Competition | P1 | P2 | P3 | P4 | P5 | P6 | Overall | Medal |
|---|---|---|---|---|---|---|---|---|
| IMO 2025 | 7 | 7 | 7 | 7 | 7 | 0 | 35/42 | Gold |
| CMO 2025 | 18 | 18 | 9 | 21 | 18 | 18 | 102/126 | Gold |
| IOI 2025 | 100 | 82 | 72 | 100 | 55 | 83 | 492/600 | Gold |
| Competition | A | B | C | D | E | F | G | H | I | J | K | L | Overall | Medal |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ICPC WF 2025 | 3 | – | 1 | 1 | 2 | 2 | – | 1 | 1 | 1 | 1 | 1 | 10/12 | Gold |
表 4:DeepSeek‑V3.2‑Speciale 在顶级数学与编程竞赛中的表现。ICPC WF 2025 以每道题成功解出的提交次数统计;该模型在 ICPC WF 2025 排名第 2,在 IOI 2025 排名第 10。
4.3 合成智能体任务消融(Synthesis Agentic Tasks)
本节通过消融实验研究“合成智能体任务”的效果,聚焦两个问题:第一,合成任务是否足够困难以用于强化学习?第二,合成任务的泛化性如何——能否迁移到不同下游任务或真实环境?
为回答第一个问题,我们从通用合成智能体任务中随机抽样 50 个实例,评测合成所用模型与前沿闭源 LLM。表 5 显示,DeepSeek‑V3.2‑Exp 的准确率仅为 12%,而前沿闭源模型最高也仅达到 62%。这表明合成数据确实包含对 DeepSeek‑V3.2‑Exp 与前沿闭源模型都具有挑战性的智能体任务。
| Pass@K | DeepSeek‑V3.2‑Exp | Sonnet‑4.5 | Gemini‑3.0 Pro | GPT‑5 Thinking |
|---|---|---|---|---|
| 1 | 12% | 34% | 51% | 62% |
| 2 | 18% | 47% | 65% | 75% |
| 4 | 26% | 62% | 74% | 82% |
表 5:不同模型在通用合成任务上的准确率。
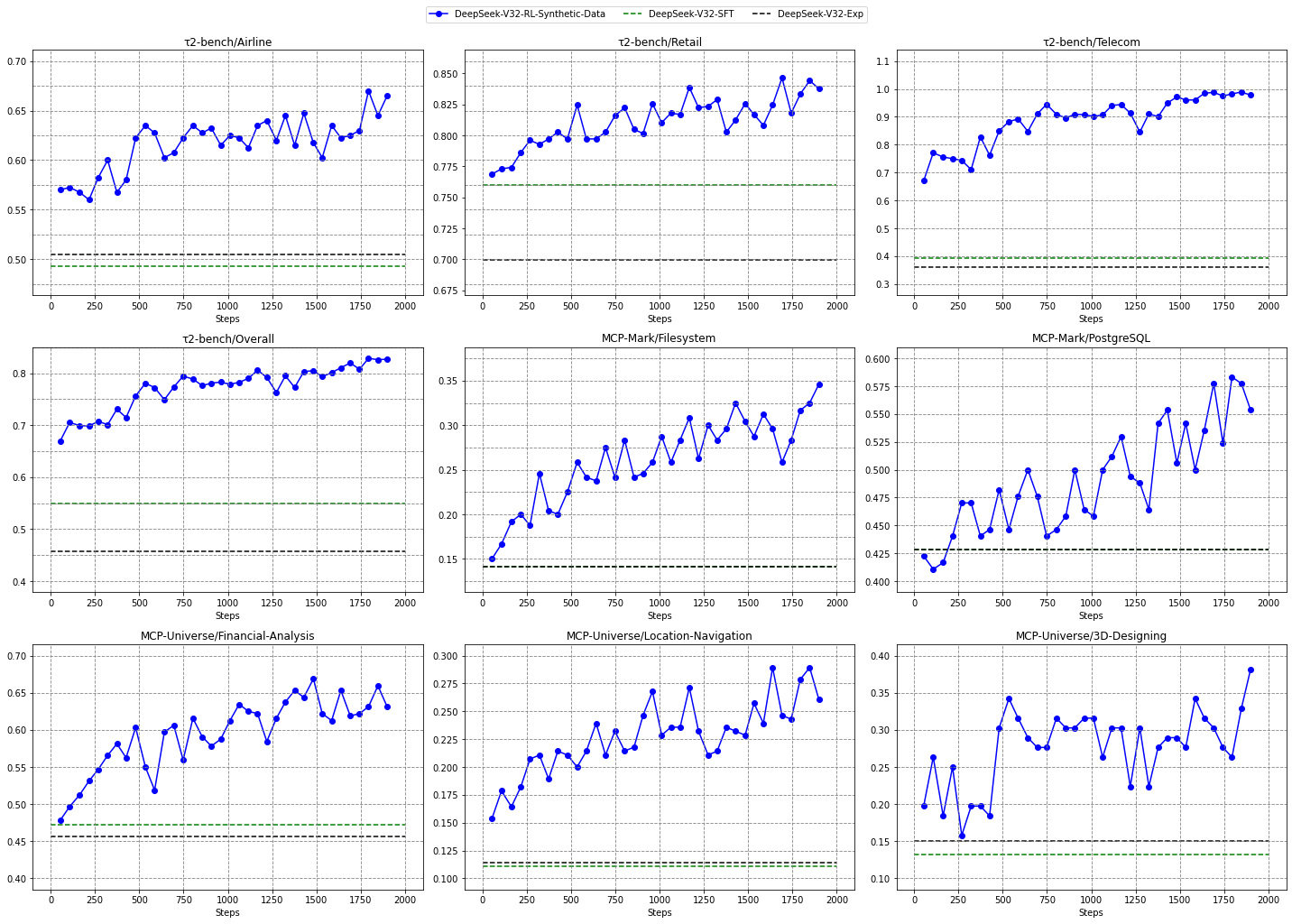
为研究“仅在合成数据上进行 RL”是否能泛化到不同任务/真实环境,我们在 DeepSeek‑V3.2 的 SFT checkpoint(记为 DeepSeek‑V3.2‑SFT)上,仅用合成通用智能体任务、且在非思考模式下进行 RL,以排除长 CoT 与其他 RL 数据的影响。我们将其与 DeepSeek‑V3.2‑SFT 及 DeepSeek‑V3.2‑Exp 对比:DeepSeek‑V3.2‑Exp 仅在搜索与代码环境中做 RL。图 5 显示,大规模合成数据 RL 在 Tau2Bench、MCP‑Mark 与 MCP‑Universe 上相对 DeepSeek‑V3.2‑SFT 带来显著提升;而将 RL 限制在代码与搜索场景并不能改善这些基准上的表现,进一步凸显合成数据的潜力。
4.4 搜索智能体的上下文管理(Context Management of Search Agent)

即便上下文窗口扩展到 128K,智能体工作流(尤其搜索场景)仍常触及最大长度限制,从而过早截断推理过程,抑制测试时计算(test‑time compute)的潜力释放。为此,我们在 token 使用超过上下文窗口长度的 80% 时,引入简单的上下文管理策略以在测试时扩展 token 预算:
- Summary:对溢出的轨迹进行摘要并重新发起 rollout;
- Discard‑75%:丢弃轨迹中最早的 75% 工具调用历史以释放空间;
- Discard‑all:丢弃全部历史工具调用以重置上下文(类似 Claude Opus 4.5 系统卡中的 new context 工具[32])。
作为对照,我们还实现了并行扩展基线 Parallel‑fewest‑step:采样 N 条独立轨迹,并选择步数最少的轨迹。
我们在 BrowseComp 基准[29] 上评测这些策略。图 6 显示,在不同计算预算下,上下文管理能通过允许模型扩展测试时计算带来显著收益,为模型提供更多执行步数空间。例如,Summary 可将平均步数扩展到 364,最高带来 60.2 的分数提升,但整体效率较低。尽管非常简单,Discard‑all 在效率与可扩展性上表现良好,取得 67.6 的分数,与并行扩展相当,但使用的步数显著更少。
综上,测试时计算既可以通过上下文管理进行串行扩展,也可以通过并行方式扩展,两者都能有效提升模型解决问题的能力。但不同策略在效率与可扩展性上差异明显,因此在基准评测中必须考虑实际计算成本。如何寻找串行与并行扩展的最优组合以同时最大化效率与可扩展性,仍是关键的未来研究方向。
5. 结论、局限与未来工作
本文提出 DeepSeek‑V3.2:一个在计算效率与高级推理能力之间有效桥接的框架。通过 DSA,我们在不牺牲长上下文性能的前提下解决了关键计算复杂度瓶颈;通过增加计算预算,DeepSeek‑V3.2 在推理基准上达到与 GPT‑5 相当的性能;通过大规模智能体任务合成流水线,我们显著提升了模型的工具使用能力,为更稳健、可泛化的开源 LLM 智能体打开了新可能。进一步地,我们的高算力变体 DeepSeek‑V3.2‑Speciale 在 IMO 与 IOI 的金牌成绩验证下,为开源 LLM 树立了新的里程碑。
尽管如此,与 Gemini‑3.0‑Pro 等前沿闭源模型相比,我们仍存在若干局限。第一,由于总训练 FLOPs 更少,DeepSeek‑V3.2 的世界知识广度仍落后于领先专有模型;我们计划在未来通过扩展预训练计算来缩小该差距。第二,token 效率仍是挑战:DeepSeek‑V3.2 往往需要更长的生成轨迹(更多 token)才能达到类似输出质量;未来工作将聚焦于提升推理链条的“智能密度”以改善效率。第三,在解决极复杂任务方面仍弱于前沿模型,这也促使我们继续完善基础模型与后训练配方。
参考文献
- OpenAI “Learning to reason with LLMs” 2024. https://openai.com/index/learning-to-reason-with-llms/
- DeepSeek-AI “DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning” Nature 2025
- Qwen “Qwen3 Technical Report” 2025. https://arxiv.org/abs/2505.09388
- ZhiPu-AI “Glm-4.5: Agentic, reasoning, and coding (arc) foundation models” arXiv preprint arXiv:2508.06471 2025
- MiniMax “https://www.minimax.io/news/minimax-m2” 2025. https://www.minimax.io/news/minimax-m2
- MoonShot “Introducing Kimi K2 Thinking” 2025. https://moonshotai.github.io/Kimi-K2/thinking.html
- OpenAI “Introducing GPT-5” 2025. https://openai.com/index/introducing-gpt-5/
- Anthropic “Introducing Claude Sonnet 4.5” 2025. https://www.anthropic.com/news/claude-sonnet-4-5l
- DeepMind “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities” arXiv preprint arXiv:2507.06261 2025
- Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin “Attention is All you Need” Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017 2017. https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
- EvalSys “MCPMark Leaderboard” 2025. https://mcpmark.ai/leaderboard
- Luo, Ziyang and Shen, Zhiqi and Yang, Wenzhuo and Zhao, Zirui and Jwalapuram, Prathyusha and Saha, Amrita and Sahoo, Doyen and Savarese, Silvio and Xiong, Caiming and Li, Junnan “Mcp-universe: Benchmarking large language models with real-world model context protocol servers” arXiv preprint arXiv:2508.14704 2025
- Li, Junlong and Zhao, Wenshuo and Zhao, Jian and Zeng, Weihao and Wu, Haoze and Wang, Xiaochen and Ge, Rui and Cao, Yuxuan and Huang, Yuzhen and Liu, Wei and others “The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution” arXiv preprint arXiv:2510.25726 2025
- DeepSeek-AI “DeepSeek-V3 Technical Report” 2024. https://arxiv.org/abs/2412.19437
- Google DeepMind “Gemini 3 Pro Model Card” 2025. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
- DeepSeek{-}AI “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model” CoRR 2024. https://doi.org/10.48550/arXiv.2405.04434
- Jingyang Yuan and Huazuo Gao and Damai Dai and Junyu Luo and Liang Zhao and Zhengyan Zhang and Zhenda Xie and Yuxing Wei and Lean Wang and Zhiping Xiao and Yuqing Wang and Chong Ruan and Ming Zhang and Wenfeng Liang and Wangding Zeng “Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention” Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025 2025. https://aclanthology.org/2025.acl-long.1126/
- Noam Shazeer “Fast Transformer Decoding: One Write-Head is All You Need” CoRR 2019. http://arxiv.org/abs/1911.02150
- Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models” CoRR 2024. https://doi.org/10.48550/arXiv.2402.03300
- Zhihong Shao and Yuxiang Luo and Chengda Lu and Z.Z. Ren and Jiewen Hu and Tian Ye and Zhibin Gou and Shirong Ma and Xiaokang Zhang “DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning” 2025
- John Schulman “Approximating KL Divergence” 2020. http://joschu.net/blog/kl-approx.html
- Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen “MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark” CoRR 2024. https://doi.org/10.48550/arXiv.2406.01574
- Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R “GPQA: A graduate-level google-proof q&a benchmark” arXiv preprint arXiv:2311.12022 2023
- Phan, Long and Gatti, Alice and Han, Ziwen and Li, Nathaniel and Hu, Josephina and Zhang, Hugh and Zhang, Chen Bo Calvin and Shaaban, Mohamed and Ling, John and Shi, Sean and others “Humanity's last exam” arXiv preprint arXiv:2501.14249 2025
- Mislav Balunović and Jasper Dekoninck and Ivo Petrov and Nikola Jovanović and Martin Vechev “MathArena: Evaluating LLMs on Uncontaminated Math Competitions” Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmark 2025
- Thang Luong and Dawsen Hwang and Hoang H. Nguyen and Golnaz Ghiasi and Yuri Chervonyi and Insuk Seo and Junsu Kim and Garrett Bingham and Jonathan Lee and Swaroop Mishra and Alex Zhai and Clara Huiyi Hu and Henryk Michalewski and Jimin Kim and Jeonghyun Ahn and Junhwi Bae and Xingyou Song and Trieu H. Trinh and Quoc V. Le and Junehyuk Jung “Towards Robust Mathematical Reasoning” Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing 2025. https://aclanthology.org/2025.emnlp-main.1794/
- OpenAI “Introducing SWE-bench Verified We’re releasing a human-validated subset of SWE-bench that more” 2024. https://openai.com/index/introducing-swe-bench-verified/
- John Yang and Kilian Lieret and Carlos E. Jimenez and Alexander Wettig and Kabir Khandpur and Yanzhe Zhang and Binyuan Hui and Ofir Press and Ludwig Schmidt and Diyi Yang “SWE-smith: Scaling Data for Software Engineering Agents” 2025. https://arxiv.org/abs/2504.21798
- Wei, Jason and Sun, Zhiqing and Papay, Spencer and McKinney, Scott and Han, Jeffrey and Fulford, Isa and Chung, Hyung Won and Passos, Alex Tachard and Fedus, William and Glaese, Amelia “Browsecomp: A simple yet challenging benchmark for browsing agents” arXiv preprint arXiv:2504.12516 2025
- Zhou, Peilin and Leon, Bruce and Ying, Xiang and Zhang, Can and Shao, Yifan and Ye, Qichen and Chong, Dading and Jin, Zhiling and Xie, Chenxuan and Cao, Meng and others “Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese” arXiv preprint arXiv:2504.19314 2025
- Victor Barres and Honghua Dong and Soham Ray and Xujie Si and Karthik Narasimhan “$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment” 2025. https://arxiv.org/abs/2506.07982
- Anthropic “System Card: Claude Opus 4.5” 2025. https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf
注:参考文献按本文首次引用顺序编号,对应正文中的方括号引用。
附录
A. MLA 的 MHA 与 MQA 模式
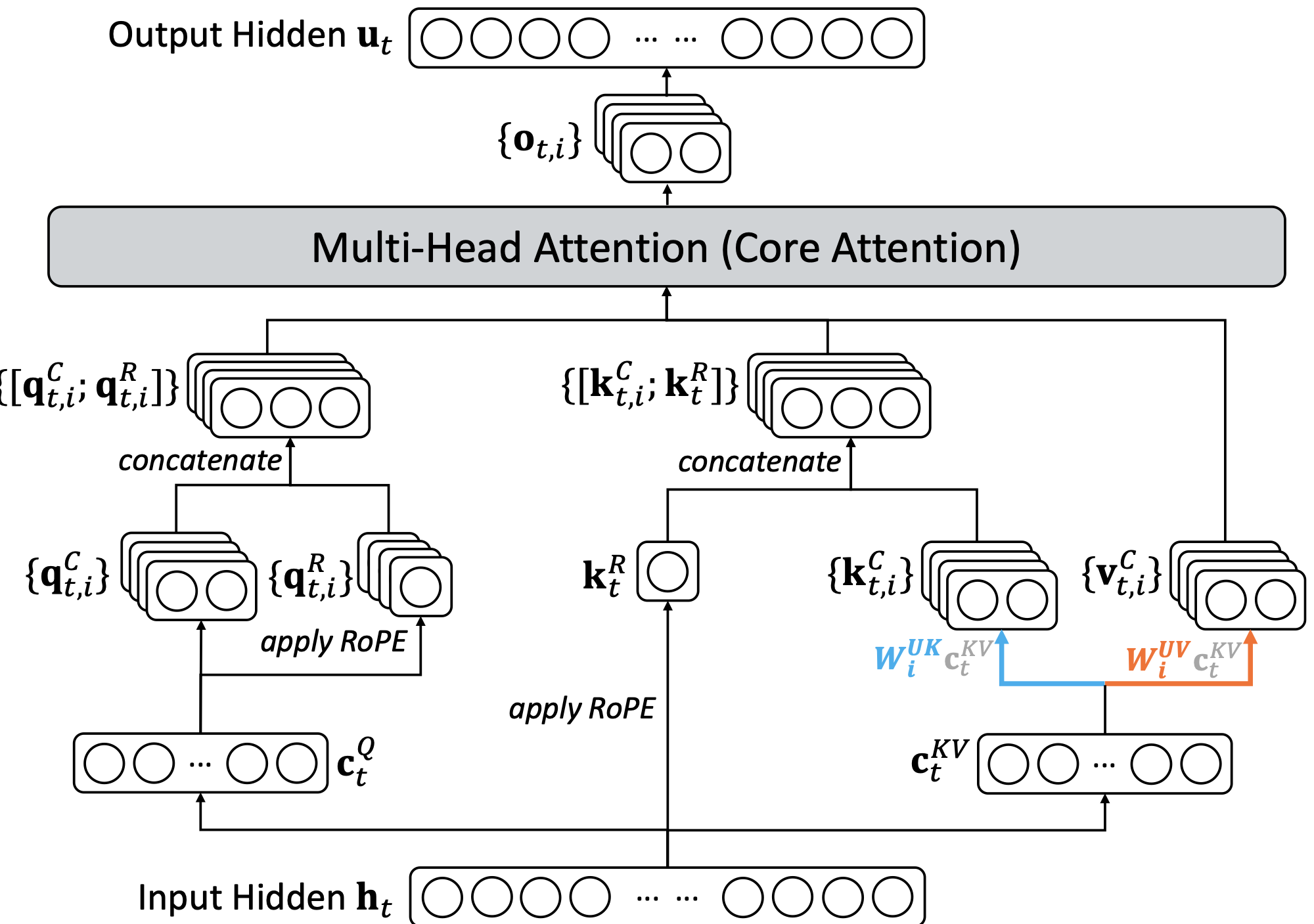
图 A.1 展示了 MLA 的两种模式(MHA 与 MQA)及其相互转换。对于 DeepSeek‑V3.1‑Terminus:训练与 prefilling 使用 MHA 模式,而 decoding 使用 MQA 模式。
B. 冷启动模板
本节展示冷启动阶段抽样的训练数据示例。表 B.1 为推理数据的 system prompt(要求模型在 <think></think> 中输出推理过程);表 B.2 展示非推理智能体数据的 system prompt,其中 {TOOL‑DESCRIPTIONS} 与 {TOOLCALL‑FORMAT} 会替换为具体工具与我们设计的 toolcall 格式;表 B.3 展示“在思考中进行工具调用”的 system prompt。
表 B.1:推理数据 system prompt(示例)
Reasoning System Prompt:
You are an expert Python programmer. You will be given a question (problem specification) and will generate a correct Python program that matches the specification and passes all tests. Please first reason before giving the final answer.
The reasoning process enclosed within <think> </think>. The final answer is output after the </think> tag.
Prompt:
Given a linked list, swap every two adjacent nodes and return its head ...
Reasoning Response:
<think>
...
</think>
[FINAL ANSWER]表 B.2:非推理智能体数据 system prompt(示例)
Agent System Prompt:
Use Python interpreter tool to execute Python code. The code will not be shown to the user. This tool should be used for internal reasoning, but not for code that is intended to be visible to the user (e.g. when creating plots, tables, or files). When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 120.0 seconds.
## Tools
You have access to the following tools:
{TOOL-DESCRIPTIONS}
Important: ALWAYS adhere to this exact format for tool use:
{TOOLCALL-FORMAT}
Prompt:
Given a linked list, swap every two adjacent nodes and return its head ...
Agent Response:
[MULTI-TURN TOOLCALL]
[FINAL ANSWER]表 B.3:在思考中进行工具调用的 system prompt(示例)
Reasoning Required Agent System Prompt:
You are a helpful assistant with access to a Python interpreter.
- You may use the Python tool multiple times during your reasoning, a.k.a in <think></think>, with a maximum of 20 code executions.
- Call the Python tool early in your reasoning to aid in solving the task. Continue reasoning and invoking tools as needed until you reach the final answer. Once you have the answer, stop reasoning and present your solution using Markdown and LaTeX.
- Do NOT invoke any tools in your presented final solution steps.
- To improve efficiency and accuracy, you should prefer code execution over language-based reasoning whenever possible. Keep your reasoning succinct; let the code do the heavy lifting.
## Tools
You have access to the following tools:
{TOOL-DESCRIPTIONS}
Important: ALWAYS adhere to this exact format for tool use:
{TOOLCALL-FORMAT}
Prompt:
Given a linked list, swap every two adjacent nodes and return its head ...
Agent Response with Thinking:
<think>
[MULTI-TURN Thinking-Then-TOOLCALL]
</think>
[FINAL ANSWER]C. 非思考模式 DeepSeek‑V3.2 的智能体评测
表 C.1 比较 DeepSeek‑V3.2 的非思考与思考模式。表中 Terminal Bench 评分使用 Claude Code 框架评测;在 Terminus 框架下的 Terminal Bench 2.0 非思考分数为 39.3。
| Benchmark(指标) | non‑thinking | thinking | |
|---|---|---|---|
| Code Agent | Terminal Bench 2.0(Acc) | 37.1 | 46.4 |
| SWE Verified(Resolved) | 72.1 | 73.1 | |
| SWE Multilingual(Resolved) | 68.9 | 70.2 | |
| ToolUse | $\tau^2$‑bench(Pass@1) | 77.2 | 80.3 |
| MCP‑Universe(Success Rate) | 38.6 | 45.9 | |
| MCP‑Mark(Pass@1) | 26.5 | 38.0 | |
| Tool‑Decathlon(Pass@1) | 25.6 | 35.2 |
总体而言,非思考模式的表现略弱于思考模式,但仍具有竞争力。
D. IOI、ICPC WF、IMO 与 CMO 的评测方法
对于所有竞赛,我们将模型最大生成长度设为 128K,不使用任何工具或互联网访问,并严格遵守竞赛的时间与尝试次数限制。
IOI:我们依据官方规则设计提交策略:每题最多 50 次提交,最终得分为所有子任务中最高得分的最大值。具体而言,我们先为每题采样 500 个候选解,再通过多阶段过滤:第一阶段移除无法通过样例或超出长度限制的无效提交;随后使用 DeepSeek‑V32‑Exp 识别并移除模型明确表示无法/拒绝解题的样本;在剩余有效候选中选择“思考轨迹最长”的 50 个样本进行最终提交。
ICPC WF:我们采用相同过滤方法,但初始采样量更小:每题生成 32 个候选解,并用相同过滤标准选择提交。
IMO/CMO:我们采用“生成‑验证‑改进”(generate‑verify‑refine)循环,模型迭代改进解答直到自评满分或达到最大修订次数上限;该流程与 DeepSeekMath‑V2[20] 一致。