DeepSeek-V4:迈向高效的百万 Token 上下文智能
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
摘要
我们提出 DeepSeek-V4 系列的预览版本,其中包括两个强大的 Mixture-of-Experts(MoE)语言模型——具有 1.6T 参数(49B 激活参数)的 DeepSeek-V4-Pro,以及具有 284B 参数(13B 激活参数)的 DeepSeek-V4-Flash——二者都支持一百万 token 的上下文长度。DeepSeek-V4 系列在架构与优化方面融合了若干关键升级:(1)一种混合注意力架构,将 Compressed Sparse Attention(CSA)与 Heavily Compressed Attention(HCA)结合起来,以提升长上下文效率;(2)Manifold-Constrained Hyper-Connections(mHC),用于增强传统残差连接;(3)Muon 优化器,用于实现更快收敛和更高训练稳定性。我们在超过 32T 的多样且高质量 token 上对两个模型进行了预训练,随后又进行了完整的后训练流程,以释放并进一步增强它们的能力。DeepSeek-V4-Pro-Max 作为 DeepSeek-V4-Pro 的最大推理努力模式,为开放模型重新定义了最先进水平,在核心任务上超过其前代模型。与此同时,DeepSeek-V4 系列在长上下文场景中具有极高效率。在一百万 token 上下文设置下,与 DeepSeek-V3.2 相比,DeepSeek-V4-Pro 仅需要其 27% 的单 token 推理 FLOPs 和 10% 的 KV cache。这使我们能够常规性地支持一百万 token 上下文,从而让长时程任务和进一步的 test-time scaling 更具可行性。模型检查点可在 https://huggingface.co/collections/deepseek-ai/deepseek-v4 获取。
1. 引言
推理模型(DeepSeek-AI, 2025;OpenAI, 2024c)的出现,确立了 test-time scaling 的一种新范式,并推动 Large Language Models(LLMs)取得显著性能提升。然而,这一扩展范式从根本上受限于原始注意力机制(Vaswani et al., 2017)的二次计算复杂度,这为超长上下文与推理过程制造了难以承受的瓶颈。与此同时,长时程场景与任务——从复杂的 agentic 工作流到大规模跨文档分析——的出现,也使得对超长上下文的高效支持成为未来进展的关键。尽管近期的开源工作(Bai et al., 2025a;DeepSeek-AI, 2024;MiniMax, 2025;Qwen, 2025)推进了通用能力,但这种在处理超长序列时的核心架构低效性仍然是一个关键障碍,它限制了 test-time scaling 的进一步收益,也阻碍了对长时程场景与任务的进一步探索。
为了打破超长上下文中的效率壁垒,我们开发了 DeepSeek-V4 系列,其中包括具有 1.6T 参数(49B 激活参数)的 DeepSeek-V4-Pro 预览版,以及具有 284B 参数(13B 激活参数)的 DeepSeek-V4-Flash 预览版。通过架构创新,DeepSeek-V4 系列在处理超长序列的计算效率上实现了显著飞跃。这一突破使得对一百万 token 上下文长度的高效支持成为可能,开启了下一代 LLM 的百万长度上下文新时代。我们相信,我们对超长序列进行高效处理的能力,开启了 test-time scaling 的下一个前沿,为深入研究长时程任务铺平了道路,并为探索诸如在线学习之类的未来范式奠定了必要基础。
与 DeepSeek-V3 架构(DeepSeek-AI, 2024)相比,DeepSeek-V4 系列保留了 DeepSeekMoE 框架(Dai et al., 2024)和 Multi-Token Prediction(MTP)策略,同时在架构与优化方面引入了若干关键创新。为提升长上下文效率,我们设计了一种混合注意力机制,将 Compressed Sparse Attention(CSA)与 Heavily Compressed Attention(HCA)结合起来。CSA 沿序列维压缩 KV caches,然后执行 DeepSeek Sparse Attention(DSA)(DeepSeek-AI, 2025);而 HCA 对 KV caches 施加更激进的压缩,但保留稠密注意力。为增强建模能力,我们引入了 Manifold-Constrained Hyper-Connections(mHC)(Xie et al., 2026),用以升级传统残差连接。此外,我们将 Muon(Jordan et al., 2024;Liu et al., 2025)优化器引入 DeepSeek-V4 系列的训练中,从而带来更快收敛与更好的训练稳定性。
为了实现 DeepSeek-V4 系列的高效训练与推理,并提升开发效率,我们引入了若干基础设施优化。第一,我们为 MoE 模块设计并实现了单一融合 kernel,使计算、通信与内存访问完全重叠。第二,我们采用 TileLang(Wang et al., 2026)这一 Domain-Specific Language(DSL),以平衡开发效率与运行时效率。第三,我们提供高效的 batch-invariant 与 deterministic kernel 库,以确保训练与推理之间的逐比特可复现性。第四,我们对 MoE expert weights 和 indexer 的 QK path 引入 FP4 quantization-aware training,以减少内存与计算开销。第五,在训练框架方面,我们通过 tensor-level checkpointing 扩展 autograd 框架,以实现细粒度重计算控制;并通过用于 Muon 优化器的混合 ZeRO 策略、借助重计算与融合 kernel 的低成本 mHC 实现、以及用于管理压缩注意力的两阶段 contextual parallelism,提升训练效率。最后,在推理框架方面,我们设计了异构 KV cache 结构及其磁盘存储策略,以支持高效的共享前缀复用。
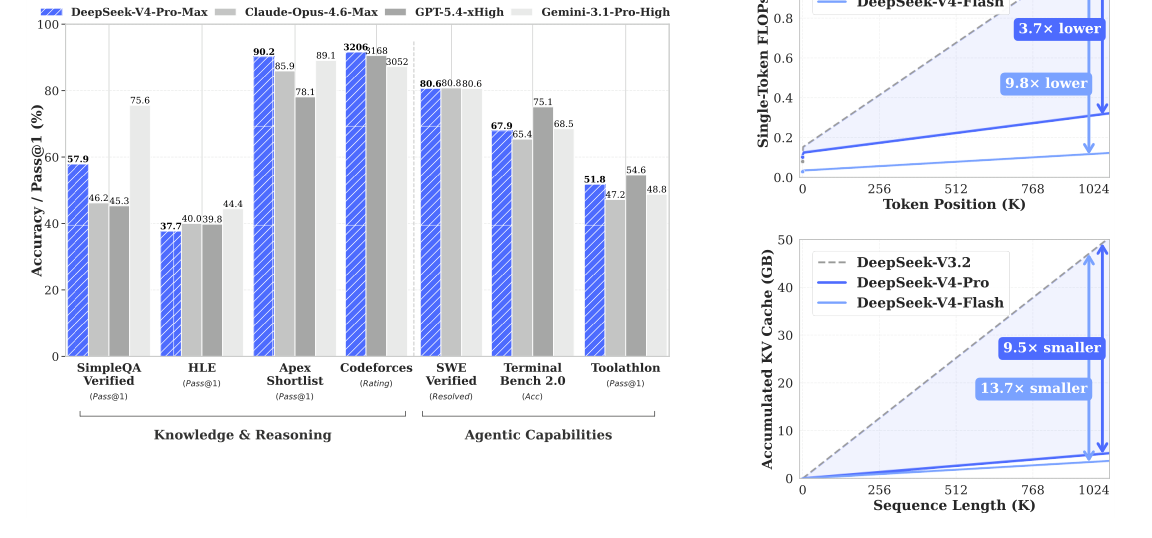
通过采用混合 CSA 与 HCA,并结合计算与存储上的精度优化,DeepSeek-V4 系列相较于 DeepSeek-V3.2 在推理 FLOPs 和 KV cache 大小上都实现了显著降低,尤其是在长上下文设置下。图 1 的右侧展示了 DeepSeek-V3.2 与 DeepSeek-V4 系列估算的单 token 推理 FLOPs 和累计 KV cache 大小。在 1M-token 上下文场景下,即使是激活参数更多的 DeepSeek-V4-Pro,其单 token FLOPs(以等效 FP8 FLOPs 衡量)也仅为 DeepSeek-V3.2 的 27%,KV cache 大小仅为其 10%。此外,激活参数更少的 DeepSeek-V4-Flash 进一步推进了效率:在 1M-token 上下文设置下,它的单 token FLOPs 仅为 DeepSeek-V3.2 的 10%,KV cache 大小仅为其 7%。另外,DeepSeek-V4 系列中的 routed expert 参数使用 FP4 精度。尽管在现有硬件上,FP4 × FP8 运算的峰值 FLOPs 与 FP8 × FP8 目前相同,但在未来硬件上,理论上它可以做到高出 1/3 的效率,这将进一步增强 DeepSeek-V4 系列的效率。
在预训练期间,我们分别在 32T token 上训练 DeepSeek-V4-Flash,在 33T token 上训练 DeepSeek-V4-Pro。预训练之后,这两个模型都可以原生且高效地支持 1M 长度上下文。在我们的内部评测中,凭借更高的参数效率设计,DeepSeek-V4-Flash-Base 已经在大多数基准上超过 DeepSeek-V3.2-Base。DeepSeek-V4-Pro-Base 则进一步扩展了这一优势,在 DeepSeek 基础模型中树立了新的性能标准,在推理、代码、长上下文和世界知识任务上实现了全面领先。
DeepSeek-V4 系列的后训练流水线采用两阶段范式:先独立培养各个领域专家,再通过 on-policy distillation(Lu and Lab, 2025)将其整合为统一模型。起初,对于每个目标领域——例如数学、代码、agent 和 instruction following——都会独立训练一个专家模型。基础模型首先在高质量、领域专用数据上进行 Supervised Fine-Tuning(SFT),以建立基础能力。随后使用 Group Relative Policy Optimization(GRPO)(DeepSeek-AI, 2025)进行 Reinforcement Learning(RL),在与特定成功标准相匹配的奖励模型引导下,进一步将模型优化为与领域一致的行为。该阶段产出一组多样化的专门专家,每个专家都擅长各自领域。最后,为了整合这些不同专长,我们通过 on-policy distillation 训练单一统一模型,其中统一模型作为 student,从 teacher models 中学习优化 reverse KL loss。
核心评测结果摘要
- 知识:在广泛世界知识评测中,DeepSeek-V4-Pro-Max 作为 DeepSeek-V4-Pro 的最大推理努力模式,在 SimpleQA(OpenAI, 2024d)和 Chinese-SimpleQA(He et al., 2024)基准上显著超过领先开源模型。对于教育知识——通过 MMLU-Pro(Wang et al., 2024b)、HLE(Phan et al., 2025)和 GPQA(Rein et al., 2023)评测——DeepSeek-V4-Pro-Max 相比其开源对应模型表现出小幅领先。尽管在这些基于知识的评测中它仍落后于 Gemini-3.1-Pro,但已经显著缩小了与领先闭源模型之间的差距。
- 推理:随着推理 token 的扩展,DeepSeek-V4-Pro-Max 在标准推理基准上展现出相对 GPT-5.2 与 Gemini-3.0-Pro 的更优表现。不过,它的表现仍略逊于 GPT-5.4 与 Gemini-3.1-Pro,这表明其发展轨迹大约落后最前沿模型 3 到 6 个月。此外,DeepSeek-V4-Flash-Max 取得了与 GPT-5.2 和 Gemini-3.0-Pro 相当的表现,使其成为复杂推理任务上一种极具成本效益的架构。
- Agent:在公开基准上,DeepSeek-V4-Pro-Max 与领先开源模型——例如 Kimi-K2.6 和 GLM-5.1——大致相当,但略逊于前沿闭源模型。在我们的内部评测中,DeepSeek-V4-Pro-Max 超过 Claude Sonnet 4.5,并接近 Opus 4.5 的水平。
- 长上下文:在一百万 token 上下文窗口下,DeepSeek-V4-Pro-Max 在合成与真实使用场景中都给出了强劲结果,甚至在学术基准上超过 Gemini-3.1-Pro。
- DeepSeek-V4-Pro 对比 DeepSeek-V4-Flash:由于参数规模更小,DeepSeek-V4-Flash-Max 在知识评测中的表现更低。然而,当给予更大的思考预算时,它在推理任务上取得了可比结果。在 agent 评测中,虽然 DeepSeek-V4-Flash-Max 在若干基准上可以匹配 DeepSeek-V4-Pro-Max 的表现,但在更复杂、难度更高的任务上仍落后于更大的对应模型。
2. 架构
总体而言,DeepSeek-V4 系列保留了 Transformer(Vaswani et al., 2017)架构和 Multi-Token Prediction(MTP)模块(DeepSeek-AI, 2024;Gloeckle et al., 2024),同时相较于 DeepSeek-V3 引入了若干关键升级:(1)首先,我们引入 Manifold-Constrained Hyper-Connections(mHC)(Xie et al., 2026)来增强传统残差连接;(2)其次,我们设计了一种混合注意力架构,通过 Compressed Sparse Attention 和 Heavily Compressed Attention 大幅提升长上下文效率;(3)第三,我们采用 Muon(Jordan et al., 2024;Liu et al., 2025)作为优化器。对于 Mixture-of-Experts(MoE)部分,我们仍然采用 DeepSeekMoE(Dai et al., 2024)架构,只对 DeepSeek-V3 做了少量调整。Multi-Token Prediction(MTP)(DeepSeek-AI, 2024;Gloeckle et al., 2024;Li et al., 2024;Qi et al., 2020)的配置与 DeepSeek-V3 完全相同。其余未特别说明的细节均沿用 DeepSeek-V3(DeepSeek-AI, 2024)中的设定。图 2 展示了 DeepSeek-V4 的整体架构,具体细节如下所述。
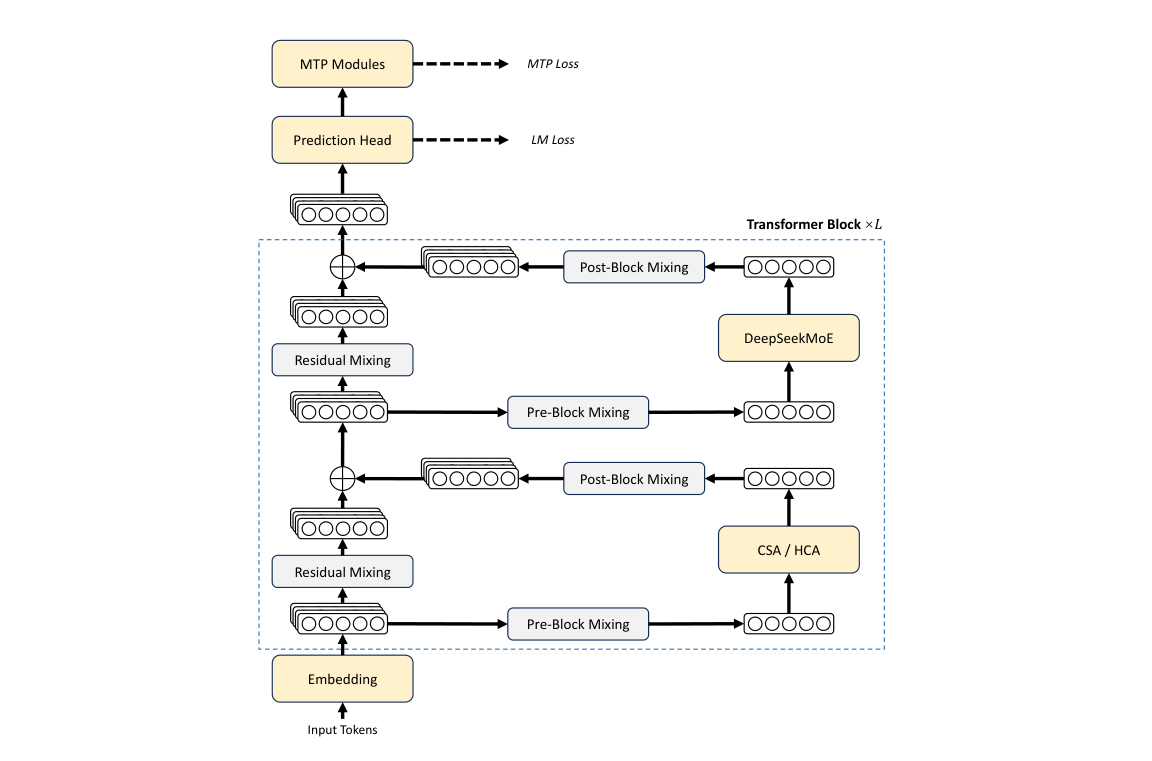
2.1. 继承自 DeepSeek-V3 的设计
Mixture-of-Experts
与以往的 DeepSeek 系列模型(DeepSeek-AI, 2024;DeepSeek-AI, 2024)一样,DeepSeek-V4 系列也在 Feed-Forward Networks(FFNs)中采用 DeepSeekMoE 范式(Dai et al., 2024),设置了细粒度 routed experts 和 shared experts。与 DeepSeek-V3 不同的是,我们将用于计算亲和力分数的激活函数从 Sigmoid(·) 改为 Sqrt(Softplus(·))。在负载均衡方面,我们也采用 auxiliary-loss-free 策略(DeepSeek-AI, 2024;Wang et al., 2024a),并辅以轻微的 sequence-wise balance loss,以防止单个序列内部出现极端不均衡。对于 DeepSeek-V4,我们取消了对 routing 目标节点数量的约束,并仔细重新设计了并行策略,以维持训练效率。此外,相比 DeepSeek-V3,我们将最初若干 Transformer block 中的稠密 FFN 层替换为采用 Hash routing(Roller et al., 2021)的 MoE 层。Hash routing 策略根据预定义的哈希函数、相对于输入 token ID 来决定每个 token 的目标 expert。
Multi-Token Prediction
与 DeepSeek-V3 一样,DeepSeek-V4 系列也设置了 MTP 模块和训练目标。鉴于 MTP 策略已经在 DeepSeek-V3 中得到验证,我们在 DeepSeek-V4 系列中不加修改地沿用了同样的策略。
2.2. Manifold-Constrained Hyper-Connections
如图 2 所示,DeepSeek-V4 系列引入了 Manifold-Constrained Hyper-Connections(mHC)(Xie et al., 2026),以增强相邻 Transformer block 之间的传统残差连接。与朴素的 Hyper-Connections(HC)(Zhu et al., 2025)相比,mHC 的核心思想是将残差映射约束在特定流形上,从而在保留模型表达能力的同时,增强跨层信号传播的稳定性。本小节简要介绍标准 HC,并说明我们如何设计 mHC 以实现稳定训练。
标准 Hyper-Connections
标准 HC 将残差流的宽度扩展到原来的 n_hc 倍。具体而言,残差流的形状由 R^d 扩展为 R^(n_hc × d),其中 d 是实际层输入的 hidden size。设 X_l = [x_(l,1); ...; x_(l,n_hc)]^T ∈ R^(n_hc × d) 为第 l 层之前的残差状态。HC 引入三个线性映射:输入映射 A_l ∈ R^(1 × n_hc)、残差变换 B_l ∈ R^(n_hc × n_hc),以及输出映射 C_l ∈ R^(n_hc × 1)。残差状态的更新写为:
X_(l+1) = B_l X_l + C_l F_l(A_l X_l) (1)
其中 F_l 表示第 l 层(例如一个 MoE 层),其输入与输出形状都为 R^d。注意,实际层输入 A_l X_l ∈ R^d 仍然是 d 维,因此扩展后的残差宽度不会影响内部层的设计。HC 将残差宽度与实际 hidden size 解耦,在计算开销很小的情况下提供了一条互补的扩展轴,因为 n_hc 通常远小于 hidden size d。然而,尽管 HC 已经表现出改善模型性能的潜力,我们发现当堆叠多层时,训练会频繁出现数值不稳定,这阻碍了 HC 的扩展。
流形约束残差映射
mHC 的核心创新,是将残差映射矩阵 B_l 约束到双随机矩阵流形(Birkhoff polytope)M 上,从而增强跨层信号传播的稳定性:
B_l ∈ M ≔ { M ∈ R^(n × n) | M 1_n = 1_n, 1_n^T M = 1_n^T, M ≥ 0 } (2)
这一约束确保映射矩阵的谱范数 ||B_l||_2 被 1 所界定,因此残差变换是非扩张的,这提升了前向传播和反向传播中的数值稳定性。此外,集合 M 对乘法封闭,这保证了在深层 mHC 堆叠场景中的稳定性。除此之外,输入变换 A_l 与输出变换 C_l 也通过 Sigmoid 函数被约束为非负且有界,以避免信号相互抵消的风险。
动态参数化
三个线性映射的参数都是动态生成的,它们被分解为动态(依赖输入)分量和静态(不依赖输入)分量。给定输入 X_l ∈ R^(n_hc × d),我们先将其展平并归一化:X̂_l = RMSNorm(vec(X_l)) ∈ R^(1 × n_hc d)。随后,我们遵循标准 HC 的做法,生成无约束的原始参数 Ã_l ∈ R^(1 × n_hc)、B̃_l ∈ R^(n_hc × n_hc) 和 Ĉ_l ∈ R^(n_hc × 1):
Ã_l = α_l^pre · (X̂_l W_l^pre) + S_l^pre (3)
B̃_l = α_l^res · Mat(X̂_l W_l^res) + S_l^res (4)
Ĉ_l = α_l^post · (X̂_l W_l^post)^T + S_l^post (5)
其中,W_l^pre、W_l^post ∈ R^(n_hc d × n_hc) 以及 W_l^res ∈ R^(n_hc d × n_hc^2) 是用于生成动态分量的可学习参数;Mat(·) 将一个大小为 1 × n_hc^2 的向量重塑为大小为 n_hc × n_hc 的矩阵;S_l^pre ∈ R^(1 × n_hc)、S_l^post ∈ R^(n_hc × 1) 和 S_l^res ∈ R^(n_hc × n_hc) 是可学习的静态偏置;而 α_l^pre、α_l^res、α_l^post 是初始化为较小值的可学习门控因子。
施加参数约束
在得到无约束原始参数 Ã_l、B̃_l、Ĉ_l 之后,我们再对其施加前文描述的约束,以增强数值稳定性。具体来说,对于输入映射和输出映射,我们使用 Sigmoid 函数 σ(·) 来保证其非负性和有界性:
A_l = σ(Ã_l) (6)
C_l = 2σ(Ĉ_l) (7)
对于残差映射 B̃_l,我们将其投影到双随机矩阵流形 M 上。这通过 Sinkhorn-Knopp 算法实现:先对 B̃_l 应用指数函数以保证其为正,得到 M^(0) = exp(B̃_l),然后交替执行列归一化和行归一化:
M^(t) = T_r(T_c(M^(t-1))) (8)
其中 T_r 和 T_c 分别表示行归一化和列归一化。该迭代会收敛到受约束的双随机矩阵 B_l = M^(t_max)。我们选择 t_max = 20 作为实践中的取值。
2.3. 结合 CSA 与 HCA 的混合注意力
随着上下文长度达到极端规模,注意力机制成为模型中的主要计算瓶颈。对于 DeepSeek-V4,我们设计了两种高效注意力架构——Compressed Sparse Attention(CSA)与 Heavily Compressed Attention(HCA)——并采用二者交错的混合配置,从而在长文本场景下大幅降低注意力的计算成本。CSA 同时结合压缩与稀疏注意力策略:它先把每 m 个 token 的 Key-Value(KV)cache 压缩成一个条目,然后执行 DeepSeek Sparse Attention(DSA)(DeepSeek-AI, 2025),使每个 query token 只关注 k 个压缩后的 KV 条目。HCA 的目标则是极致压缩:它将每 m'(且 m' ≫ m)个 token 的 KV cache 合并为一个条目。CSA 与 HCA 的混合架构显著提升了 DeepSeek-V4 系列的长上下文效率,使一百万 token 上下文在实践中成为可行方案。本小节描述我们混合注意力架构的核心技术;我们也提供了开源实现以无歧义地说明更多细节:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/tree/main/inference
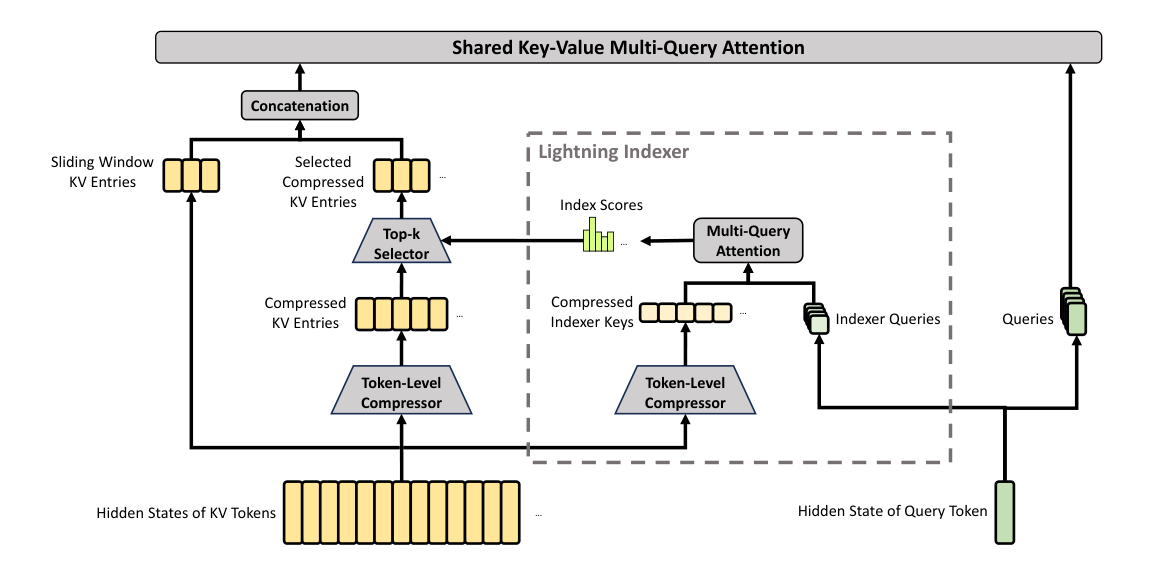
2.3.1. Compressed Sparse Attention
CSA 的核心架构如图 3 所示。它首先将每 m 个 token 的 KV cache 压缩为一个条目,然后应用 DeepSeek Sparse Attention 进一步加速。
压缩 Key-Value 条目
设 H ∈ R^(n×d) 为输入 hidden states 序列,其中 n 是序列长度,d 是 hidden size。CSA 首先计算两组 KV 条目 C^a, C^b ∈ R^(n×c) 及其对应的压缩权重 Z^a, Z^b ∈ R^(n×c),其中 c 是 head dimension:
C^a = H · W_KV^a, C^b = H · W_KV^b (9)
Z^a = H · W_Z^a, Z^b = H · W_Z^b (10)
其中 W_KV^a、W_KV^b、W_Z^a、W_Z^b ∈ R^(d×c) 为可训练参数。接着,C^a 与 C^b 中每 m 个 KV 条目会依据其压缩权重和可学习的位置偏置 B_a, B_b ∈ R^(m×c) 被压缩为一个条目,得到 C^Comp ∈ R^((n/m)×c)。每个压缩条目由式(11)(12)计算:对来自 Z^a 与 Z^b 的总计 2m 个元素沿行执行 Softmax_row 归一化,再用得到的权重对对应的 C^a 与 C^b 条目做 Hadamard 加权求和。
[S^a; S^b] = Softmax_row([Z^a + B_a; Z^b + B_b]) (11)
C_i^Comp = Σ_j S_j^a ⊙ C_j^a + Σ_j S_j^b ⊙ C_j^b (12)
其中 ⊙ 表示 Hadamard product;Softmax_row(·) 表示沿行维度执行 softmax。 当 i = 0 时,不足部分用负无穷与零做填充。注意,每个 C_i^Comp 来自 2m 个 KV 条目,但用于 C_i^Comp 的 C^b 索引与用于 C_(i-1)^Comp 的 C^a 索引发生重叠。因此,CSA 实际上将序列长度压缩到原来的 1/m。
用于稀疏选择的 Lightning Indexer
得到压缩后的 KV 条目 C^Comp 之后,CSA 采用 DSA 策略,为核心注意力选择 top-k 个压缩 KV 条目。首先,CSA 对 C^Comp 所用的同一压缩操作进行复用,得到压缩后的 indexer keys K_I^Comp ∈ R^((n/m)×c_I),其中 c_I 是 indexer head dimension。然后,对 query token t,我们以低秩方式生成 indexer query:
c_t^Q = h_t · W_DQ (13)
[q_(t,1)^I; ...; q_(t,n_h^I)^I] = q_t^I = c_t^Q · W_UQ^I (14)
其中 h_t ∈ R^d 是 query token t 的输入 hidden state;c_t^Q ∈ R^(d_c) 是 query 的压缩 latent vector;d_c 表示 query compression dimension;n_h^I 表示 indexer query heads 的数量;W_DQ ∈ R^(d×d_c) 和 W_UQ^I ∈ R^(d_c×c_I n_h^I) 分别为 down-projection 与 up-projection 矩阵。
随后,query token t 与先前压缩块 s(s < floor(t/m))之间的 index score I_(t,s) 按如下方式计算:
[w_(t,1)^I; ...; w_(t,n_h^I)^I] = w_t^I = h_t · W_w^I (15)
I_(t,s) = Σ_h w_(t,h)^I · ReLU(q_(t,h)^I · K_s^IComp) (16)
其中 W_w^I ∈ R^(d×n_h^I) 是可学习矩阵;w_(t,h)^I ∈ R 是第 h 个 indexer head 的权重。对给定 query token t,基于其 index scores I_(t,:),我们使用 top-k selector 选择保留下游核心注意力所需的压缩 KV 子集:
C_t^SprsComp = { C_s^Comp | I_(t,s) ∈ Top-k(I_(t,:)) } (17)
共享 Key-Value MQA
在选择出稀疏 KV 条目之后,CSA 以 Multi-Query Attention(MQA)(Shazeer, 2019)的方式执行核心注意力,其中 C_t^SprsComp 中的每个压缩 KV 条目同时充当 attention key 与 value。具体来说,对 query token t,我们先从压缩 latent vector c_t^Q 生成注意力 query {q_(t,1), q_(t,2), ..., q_(t,n_h)}:
[q_(t,1); q_(t,2); ...; q_(t,n_h)] = q_t = c_t^Q · W_UQ (18)
其中 n_h 表示 query heads 数量;W_UQ ∈ R^(d_c×c n_h) 是 queries 的 up-projection 矩阵。注意,latent query vector c_t^Q 与 indexer query 所使用的向量是共享的。随后,我们在 {q_(t,i)} 与 C_t^SprsComp 上执行 MQA:
o_(t,i) = CoreAttn(query=q_(t,i), key=C_t^SprsComp, value=C_t^SprsComp) (19)
其中 o_(t,i) ∈ R^c 是第 i 个 head 在第 t 个 token 的核心注意力输出;CoreAttn(·) 表示核心注意力操作。
分组输出投影
在 DeepSeek-V4 的配置下,c n_h 非常大。因此,若直接将核心注意力输出 [o_(t,1); o_(t,2); ...; o_(t,n_h)] = o_t ∈ R^(c n_h) 投影到一个 d 维 hidden state,会带来较大计算负担。为降低这一成本,我们设计了 grouped output projection 策略。具体而言,我们先将 n_h 个输出划分为 g 个组,然后对每个组的输出 o_(t,i)^G ∈ R^(c n_h/g),将其投影到一个 d_g' 维中间输出,其中 d_g' < c n_h/g。最后,我们再把这些中间输出拼接后投影为最终注意力输出 ô_t ∈ R^d。
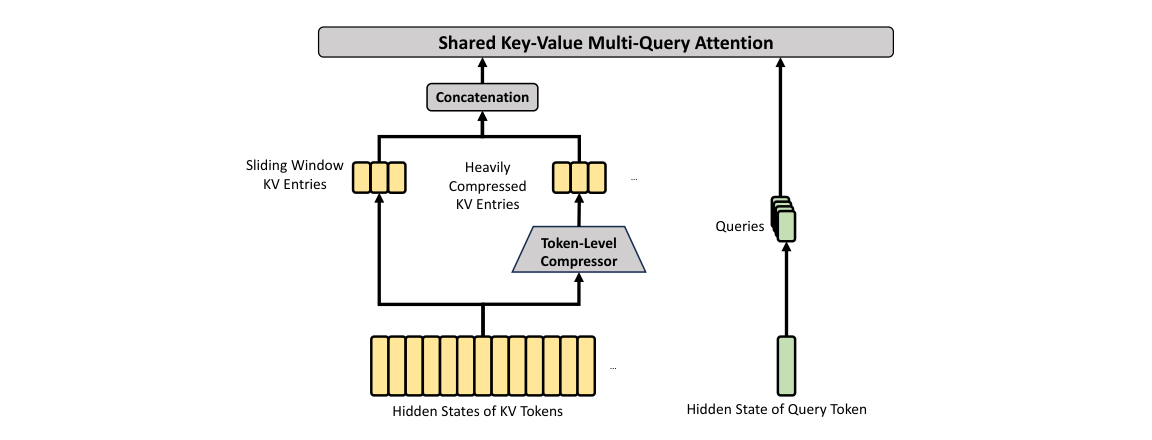
2.3.2. Heavily Compressed Attention
HCA 的核心架构如图 4 所示。它以更重的方式压缩 KV cache,但不使用稀疏注意力。
压缩 Key-Value 条目
总体上,HCA 的压缩策略与 CSA 相似,但采用更大的压缩率 m'(m' ≫ m),且不执行重叠压缩。设 H ∈ R^(n×d) 为输入 hidden states 序列,HCA 首先计算原始 KV 条目 C ∈ R^(n×c) 及其对应压缩权重 Z ∈ R^(n×c):
C = H · W_KV (20)
Z = H · W_Z (21)
其中 W_KV, W_Z ∈ R^(d×c) 为可训练参数。随后,C 中每 m' 个 KV 条目会依据压缩权重与可学习的位置偏置 B ∈ R^(m'×c) 被压缩为一个条目,得到 C^Comp ∈ R^((n/m')×c)。每个压缩条目由下式给出:
S = Softmax_row(Z + B) (22)
C_i^Comp = Σ_j S_j ⊙ C_j (23)
通过这一压缩操作,HCA 将序列长度压缩到原来的 1/m'。
共享 Key-Value MQA 与分组输出投影
HCA 与 CSA 一样,也采用共享 KV MQA 与 grouped output projection。KV 压缩完成后,对 query token t,HCA 首先以低秩方式生成注意力 query {q_(t,1), q_(t,2), ..., q_(t,n_h)}:
c_t^Q = h_t · W_DQ (24)
[q_(t,1); q_(t,2); ...; q_(t,n_h)] = q_t = c_t^Q · W_UQ (25)
其中 h_t ∈ R^d 是 query token t 的输入 hidden state;n_h 表示 query heads 数量;W_DQ ∈ R^(d×d_c) 与 W_UQ ∈ R^(d_c×c n_h) 分别是 queries 的 down-projection 与 up-projection 矩阵。接着,我们在 {q_(t,i)} 与 C^Comp 上执行 MQA:
o_(t,i) = CoreAttn(query=q_(t,i), key=C^Comp, value=C^Comp) (26)
其中 o_(t,i) ∈ R^c 是第 i 个 head 在第 t 个 token 的核心注意力输出。然后,与 CSA 一样,HCA 将 n_h 个输出分为 g 组,并把每组输出投影为更低维的中间结果,再投影为最终注意力输出 ô_t ∈ R^d。
2.3.3. 其他细节
除了上面介绍的 CSA 与 HCA 核心架构之外,我们的混合注意力还包含若干其他技术。为了叙述清晰,我们在前面的介绍中省略了这些额外技术,并在本小节中做简要说明。本小节只聚焦这些技术的核心思想,出于简化目的可能省略部分很细微的实现细节。我们建议读者参考我们的开源实现以获取无歧义的细节。
Query 与 Key-Value 条目归一化
对于 CSA 与 HCA,我们会在核心注意力操作之前,对每个 head 的 queries 以及压缩 KV 条目的唯一 head 额外执行一次 RMSNorm。这种归一化可以避免 attention logits 爆炸,并可能改善训练稳定性。
局部 Rotary Positional Embedding
对于 CSA 与 HCA,我们在 attention queries、KV 条目以及核心注意力输出上部分使用 Rotary Positional Embedding(RoPE)(Su et al., 2024)。具体来说,对于 CSA 和 HCA 中使用的每个 query 向量与 KV 条目向量,我们将 RoPE 施加到其最后 64 个维度上。由于 KV 条目同时作为 attention keys 和 values,朴素的核心注意力输出 {o_(t,i)} 会携带由 KV 条目加权和所带来的绝对位置嵌入。为应对这一点,我们还会在每个 o_(t,i) 的最后 64 个维度上以位置 -i 再施加一次 RoPE。这样一来,核心注意力的输出也会携带相对位置嵌入——每个 KV 条目对核心注意力输出的贡献,也会与 query 和该 KV 条目之间的距离相关。
附加的滑动窗口注意力分支
为了在 CSA 与 HCA 中严格保持因果性,每个 query 只关注先前的压缩 KV 块。因此,一个 query 无法访问其所属压缩块内其他 token 的信息。同时,在语言建模中,近期 token 往往与 query token 具有更高相关性。基于这些原因,我们以 sliding window 的形式为 CSA 与 HCA 都引入了一个补充注意力分支,以更好地建模局部依赖。具体而言,对每个 query token,我们额外产生与最近 n_win 个 token 对应的 n_win 个未压缩 KV 条目。在 CSA 与 HCA 的核心注意力中,这些滑动窗口内的 KV 条目会与压缩 KV 条目一起使用。
Attention Sink
在 CSA 与 HCA 的核心注意力中,我们采用 attention sink 技巧(OpenAI, 2025;Xiao et al., 2024)。具体来说,我们设置一组可学习的 sink logits {z'_1, z'_2, ..., z'_(n'_h)}。对于第 h 个 attention head,Exp(z'_h) 会被加到注意力分数分母中:
s_(h,i,j) = Exp(z_(h,i,j)) / (Σ_k Exp(z_(h,i,k)) + Exp(z'_h)) (27)
其中 s_(h,i,j) 与 z_(h,i,j) 分别表示第 h 个 attention head 在第 i 个 query token 与第 j 个先前 token 或压缩块之间的 attention score 与 attention logit。这一技术允许每个 query head 将其总注意力分数调整为不必等于 1,甚至可以接近 0。
2.3.4. 效率讨论
由于采用混合 CSA 与 HCA,并结合低精度计算与存储,DeepSeek-V4 系列的注意力模块在 attention FLOPs 与 KV cache 大小两方面都实现了显著效率优势,尤其是在长上下文场景下。首先,我们为 KV 条目采用混合存储格式:Rotary Positional Embedding(RoPE)维度使用 BF16 精度,剩余维度使用 FP8 精度。与纯 BF16 存储相比,这种混合表示将 KV cache 大小几乎减半。第二,lightning indexer 内部的注意力计算采用 FP4 精度,这在超长上下文下加速了注意力操作。第三,相比 DeepSeek-V3.2,DeepSeek-V4 系列选择了更小的 attention top-k,因此提升了模型在短文本和中等长度文本上的效率。最后,也是最重要的一点,压缩注意力与混合注意力技术显著降低了 KV cache 大小与计算 FLOPs。
以 head dimension 为 128 的 BF16 GQA8(Ainslie et al., 2023)作为基线——这是 LLM 注意力的一种常见配置——在 1M-context 设置下,DeepSeek-V4 系列的 KV cache 大小可以大幅降到该基线的大约 2%。
图 1(右):DeepSeek-V4 系列与 DeepSeek-V3.2 的单 token 推理 FLOPs 和累计 KV cache 大小对比。
此外,即便与已经相当高效的基线 DeepSeek-V3.2(DeepSeek-AI, 2025)相比,DeepSeek-V4 系列仍在效率上表现出显著优势。它们在推理 FLOPs 与 KV cache 大小上的对比见图 1 右侧。

输入:学习率 η,动量 μ,权重衰减 λ,更新重缩放因子 γ
1: 对每个训练步 t:
2: 对每个逻辑上独立的权重 W ∈ R^(n×m):
3: G_t = ∇_W L_t(W_(t-1)) # 计算梯度
4: M_t = μ M_(t-1) + G_t # 累积动量缓冲区
5: O'_t = HybridNewtonSchulz(μ M_t + G_t) # Nesterov 技巧与 hybrid Newton-Schulz
6: O_t = O'_t · sqrt(max(n, m)) · γ # 重缩放更新的 RMS
7: W_t = W_(t-1) · (1 - ηλ) - η O_t # 执行权重衰减与参数更新
8: end for
9: end for
2.4. Muon 优化器
由于具有更快收敛与更高训练稳定性,我们在 DeepSeek-V4 系列的大多数模块中采用 Muon(Jordan et al., 2024;Liu et al., 2025)优化器。我们的 Muon 优化完整算法如算法 1 所总结。
基本配置
我们仍对 embedding 模块、prediction head 模块、mHC 模块中的静态偏置与门控因子,以及所有 RMSNorm 模块的权重使用 AdamW(Loshchilov and Hutter, 2017)优化器。其余所有模块均使用 Muon 更新。遵循 Liu et al.(2025),我们也对 Muon 参数施加权重衰减、使用 Nesterov(Jordan et al., 2024;Nesterov, 1983)技巧,并对更新矩阵的 Root Mean Square(RMS)进行重缩放,以复用我们的 AdamW 超参数。与他们不同的是,我们使用 hybrid Newton-Schulz iterations 进行正交化。
Hybrid Newton-Schulz 迭代
对于给定矩阵 M,设其 Singular Value Decomposition(SVD)为 M = UΣV^T。Newton-Schulz 迭代的目标是近似将 M 正交化为 UV^T。通常,首先会将 M 归一化为 M_0 = M / ||M||_F,以确保其最大奇异值不超过 1。随后,每次 Newton-Schulz 迭代执行如下操作:
M_k = a M_(k-1) + b (M_(k-1) M_(k-1)^T) M_(k-1)
+ c (M_(k-1) M_(k-1)^T)^2 M_(k-1) (28)
我们的 hybrid Newton-Schulz 在两个不同阶段中总共执行 10 次迭代。在前 8 步中,我们使用系数 (a, b, c) = (3.4445, -4.7750, 2.0315) 以实现快速收敛,使奇异值接近 1。在最后 2 步中,我们切换为系数 (a, b, c) = (2, -1.5, 0.5),从而将奇异值稳定在精确的 1。
避免 Attention Logits 爆炸
DeepSeek-V4 系列的注意力架构允许我们直接对 attention queries 与 KV 条目施加 RMSNorm,这能够有效防止 attention logits 爆炸。因此,我们在 Muon 优化器中不使用 QK-Clip 技术(Liu et al., 2025)。
3. 通用基础设施
3.1. Expert Parallelism 中细粒度通信-计算重叠
Mixture-of-Experts(MoE)可以通过 Expert Parallelism(EP)加速。然而,EP 需要复杂的跨节点通信,并对互连带宽和时延提出很高要求。为了缓解 EP 中的通信瓶颈,并在更低互连带宽要求下获得更高的端到端性能,我们提出了一种细粒度 EP 方案,将通信与计算融合为单一的流水化 kernel,以实现通信-计算重叠。
通信时延可以被隐藏
我们的 EP 方案的关键洞察在于:在 MoE 层中,通信时延可以被有效隐藏在计算之下。如图 5 所示,在 DeepSeek-V4 系列中,每个 MoE 层主要可以分解为四个阶段:两个受通信限制的阶段 Dispatch 和 Combine,以及两个受计算限制的阶段 Linear-1 和 Linear-2。我们的 profiling 表明,在单个 MoE 层中,总通信时间小于总计算时间。因此,在将通信与计算融合进统一流水线之后,计算仍然是主要瓶颈,这意味着系统可以容忍更低的互连带宽,而不会降低端到端性能。
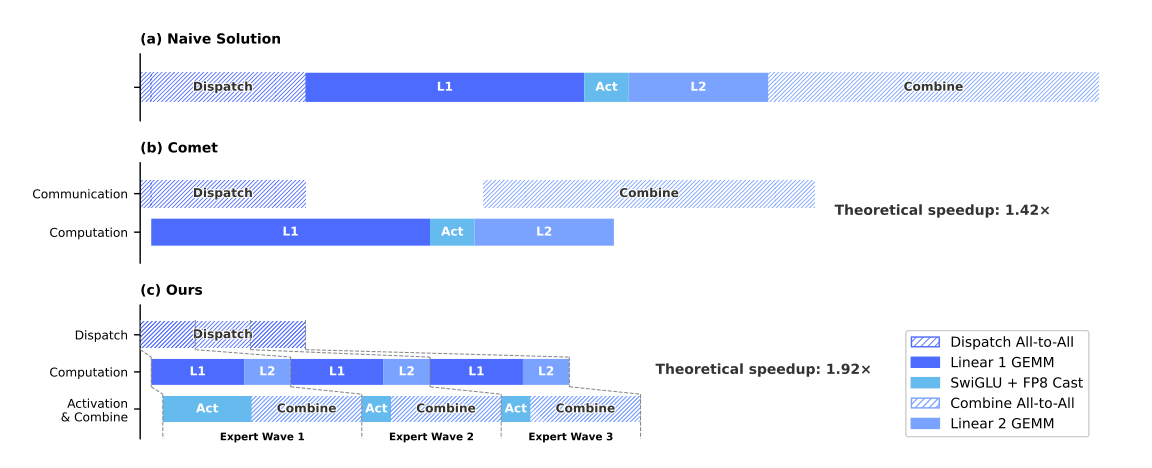
细粒度 EP 方案
为了进一步降低互连带宽要求并放大重叠收益,我们引入了一种更细粒度的 expert 划分方案。受许多相关工作(Aimuyo et al., 2025;Zhang et al., 2025b)启发,我们将 experts 划分并调度为多个 waves。每个 wave 由一小部分 experts 组成。只要某个 wave 中的所有 experts 完成通信,计算就可以立刻开始,而无需等待其他 experts。在稳态下,当前 wave 的计算、下一个 wave 的 token 传输,以及已完成 experts 的结果发送会并发进行,如图 5 所示。这在 experts 之间形成了细粒度流水线,使得计算与通信在整个 wave 过程中都保持连续。基于 wave 的调度还会加速极端场景下的性能,例如 Reinforcement Learning(RL)rollout,因为该场景通常会遇到具有长尾特征的小 batch。
性能与开源 Mega-Kernel
我们在 NVIDIA GPUs 与 HUAWEI Ascend NPUs 平台上都验证了这一细粒度 EP 方案。与强大的非融合基线相比,它在一般推理工作负载上可获得 1.50∼1.73× 加速,在 RL rollouts 与高速 agent 服务等时延敏感场景中最高可达 1.96×。我们已经将基于 CUDA 的 mega-kernel 实现以 MegaMoE 的名字开源,作为 DeepGEMM 的一个组件:
https://github.com/deepseek-ai/DeepGEMM/pull/304
观察与建议
我们分享来自 kernel 开发的观察与经验,并向硬件厂商提出一些建议,希望帮助实现更高效的硬件设计以及更好的软硬件协同设计:
- 计算-通信比。完全的通信-计算重叠取决于计算-通信比,而不只取决于带宽本身。将峰值计算吞吐记为
C、互连带宽记为B,当C/B ≤ V_comp / V_comm时,通信可以被完全隐藏,其中V_comp表示计算量,V_comm表示通信量。对于 DeepSeek-V4-Pro,每个 token-expert 对需要6hdFLOPs(SwiGLU 的 gate、up、down projections),但只需要3h字节的通信量(FP8 Dispatch + BF16 Combine),因此可化简为:
C / B ≤ 2d = 6144 FLOPs/Byte
也就是说,每 1 GBps 的互连带宽足以隐藏 6.1 TFLOP/s 计算所对应的通信。一旦带宽达到这一阈值,它就不再是瓶颈,再继续为更高带宽投入额外硅面积的回报会递减。我们鼓励未来硬件设计瞄准这种平衡点,而不是无条件地扩张带宽。
- 功耗预算。极致的 kernel 融合会同时让计算、内存和网络都处于高负载状态,使得功耗降频成为关键性能限制因素。我们建议未来硬件设计为这种全并发工作负载预留足够的功耗余量。
- 通信原语。我们采用基于 pull 的方式,即每个 GPU 主动从远端 GPU 读取数据,从而避免细粒度 push 所带来的高通知时延。若未来硬件能够提供更低时延的跨 GPU 信号机制,那么 push 将变得可行,并支持更自然的通信模式。
- 激活函数。我们建议用一种低成本逐元素激活函数替换 SwiGLU,该函数不包含指数或除法操作。这会直接减轻 post-GEMM 处理开销,并且在相同参数预算下,去掉 gate projection 还可以增大中间维度
d,从而进一步放宽带宽要求。
3.2. 使用 TileLang 进行灵活且高效的 Kernel 开发
在实践中,我们精细复杂的模型架构本会产生数百个细粒度 Torch ATen operators。我们采用 TileLang(Wang et al., 2026)开发了一组融合 kernels,用以替换其中绝大多数,从而以最小代价获得最佳性能。它还让我们能够在验证阶段快速原型化诸如注意力变体之类的 operators。这些 kernels 在模型架构开发、大规模训练以及最终推理服务的生产部署中都扮演关键角色。作为一种 Domain-Specific Language(DSL),TileLang 平衡了开发效率与运行时效率,使快速开发与在同一代码库中进行深度、迭代式优化同时成为可能。此外,我们还与 TileLang 社区密切合作,以推动更敏捷、更高效、更稳定的 kernel 开发工作流。
用 Host Codegen 降低调用开销
随着加速器性能持续增长,CPU 侧编排开销变得越来越突出。对于小而高度优化的 kernels,这种固定的 host 开销很容易限制利用率与吞吐。造成这类开销的一个常见来源是 host 侧逻辑——例如运行时契约检查——通常为了灵活性而用 Python 编写,因此会带来每次调用的固定成本。
我们通过 Host Codegen 来缓解这一开销,即将大部分 host 侧逻辑移入生成的 host 代码中。具体来说,我们首先在 IR(Intermediate Representation)层面协同生成 device kernel 与轻量级 host launcher,并嵌入从语言前端解析得到的必要元数据——如数据类型、rank/shape 约束以及 stride/layout 假设。随后,该 launcher 会被 lower 为基于 TVM-FFI(Chen et al., 2018)框架的 host 源代码,其紧凑的调用约定与 zero-copy tensor 互操作共同将 host 侧开销降到最低。在运行时,这段生成的 host 代码负责执行验证与参数打包,从而把所有逐调用检查都移出了 Python 执行路径。我们的测量表明,CPU 侧验证开销从每次调用几十到数百微秒下降到不足一微秒。
借助 SMT 求解器的形式化整数分析
TileLang kernels 涉及复杂的 tensor 索引算术,因此需要强大的形式化整数分析能力。在诸如 layout inference、memory hazard detection 和 bound analysis 等编译阶段,编译器必须验证整数表达式是否满足特定性质,以便启用相应优化。因此,更强的形式化分析能力能够解锁更高级、更复杂的优化机会。
为此,我们将 Z3 SMT solver(De Moura and Bjørner, 2008)集成到 TileLang 的代数系统中,为 tensor programs 中的大多数整数表达式提供形式化分析能力。我们通过把 TileLang 的整数表达式翻译为 Z3 的 quantifier-free non-linear integer arithmetic(QF_NIA),在计算开销与形式表达能力之间取得平衡。基于 Integer Linear Programming(ILP)求解器,QF_NIA 可以无缝处理 kernels 中常见的标准线性整数表达式。此外,它本身的非线性推理能力还能有效应对诸如变量 tensor 形状上的向量化之类的高级挑战。在合理资源限制下,Z3 在将编译时间开销控制在数秒的同时,提升了整体优化性能。这一影响在 vectorization、barrier insertion 与 code simplification 等多个编译阶段中都十分显著。
数值精度与逐比特可复现性
在生产环境中,数值正确性与可复现性和原始吞吐同样关键。因此,我们默认优先保证精度:在编译器层面禁用 fast-math 优化,而可能影响精度的近似只通过显式、可选加入的前端 operators 提供(例如 T.__exp、T.__log 和 T.__sin)。相反,当需要严格的 IEEE-754 语义时,TileLang 提供带显式舍入模式的 IEEE 兼容 intrinsic(例如 T.ieee_fsqrt、T.ieee_fdiv 和 T.ieee_add),使开发者能够精确指定数值行为。
我们还以逐比特可复现性为目标,将 kernels 与手写 CUDA 基线进行对齐验证。我们让 TileLang 的代数化简与 lowering 规则与主流 CUDA 工具链(例如 NVCC)保持一致,以避免引入意外的 bit-level 差异。Layout 标注(例如 T.annotate_layout)进一步允许用户固定依赖 layout 的 lowering 决策,使求值和累加顺序与参考 CUDA 实现保持一致,从而在需要时实现逐比特相同的输出。我们的评测表明,这些面向精度与可复现性的设计选择并未牺牲性能:在保守默认设置下,TileLang kernels 依然具备竞争力,同时还暴露出若干开关,可在需要更高速度时有选择地放宽数值约束。
3.3. 高性能、Batch-Invariant 与 Deterministic 的 Kernel 库
为了实现高效训练与推理,我们开发了一整套高性能计算 kernels。除了基本功能和最大化硬件利用率之外,另一个关键设计目标是确保预训练、后训练与推理流水线之间的训练可复现性与逐比特对齐。因此,我们实现了端到端、逐比特 batch-invariant 且 deterministic 的 kernels,而性能额外开销极小。这些 kernels 有助于调试、稳定性分析以及一致的后训练行为。
Batch Invariance
Batch invariance 指的是:任意给定 token 的输出不论其在 batch 中处于什么位置,都保持逐比特完全一致。为了实现 batch invariance,主要挑战如下:
- 注意力。为了实现 batch invariance,我们不能使用 split-KV 方法(Dao et al., 2023),该方法会把单个序列的注意力计算分布到多个 Stream Multiprocessors(SMs)上,以平衡 SM 的负载。然而,放弃这一技术会导致严重的 wave-quantization 问题,这会对 GPU 利用率产生不利影响。为此,我们为 batch-invariant decoding 开发了双 kernel 策略。第一个 kernel 在单个 SM 内计算整个序列的注意力输出,确保已完全占满 waves 时的高吞吐。第二个 kernel 为了尽量降低最后一个未完全填满 wave 的时延、从而缓解 wave-quantization,会为单个序列使用多个 SM。为了保证这两个 kernels 的逐比特一致性,我们精心设计了第二个 kernel 的计算路径,确保其累加顺序与第一个 kernel 相同。此外,第二个 kernel 还在 thread-block clusters 中利用 distributed shared memory,实现跨 SM 的高速数据交换。这个双 kernel 方法有效将 batch-invariant decoding 的额外开销限制到几乎可以忽略。
- 矩阵乘法。传统 cuBLAS 库(NVIDIA Corporation, 2024)无法实现 batch invariance。因此,我们用 DeepGEMM(Zhao et al., 2025)在端到端范围内替代它。进一步地,当 batch size 很小时,常规实现通常会使用 split-k(Osama et al., 2023)技术来提升性能。但 split-k 不能保证 batch invariance,而这正是 DeepSeek-V4 的关键特性。因此,我们在大多数场景中放弃 split-k,虽然这可能引起性能下降。为了解决这一点,我们引入了一组优化,使我们的矩阵乘法实现可以在大多数主要场景中达到甚至超过标准 split-k 的性能。
Determinism
Deterministic training 对调试硬件或软件问题非常有帮助。此外,当训练中出现诸如 loss spike 之类的异常时,determinism 使研究人员更容易定位数值原因,并进一步改进模型设计。训练中的非确定性通常来源于非确定性的累加顺序,往往由 atomic addition 指令的使用引起。这个问题主要出现在 backward pass 中,尤其体现在以下部分:
- Attention Backward。在稀疏注意力反向传播的常规实现中,我们使用
atomicAdd来累加 KV tokens 的梯度。由于浮点加法不满足结合律,这会引入非确定性。为解决这一问题,我们为每个 SM 分配独立的累加缓冲区,然后对所有缓冲区执行一次全局确定性求和。 - MoE Backward。当来自不同 ranks 的多个 SM 并发向接收端 rank 上的同一缓冲区写入数据时,写入位置的协商也会引入非确定性。为此,我们在单个 rank 内设计了 token order 预处理机制,并配合多 rank 之间的缓冲区隔离。该策略同时保证了 expert parallelism 发送结果和 MoE backward 累加顺序的确定性。
- mHC 中的矩阵乘法。mHC 包含一个输出维度只有 24 的矩阵乘法。在非常小的 batch size 下,我们被迫使用 split-k(Osama et al., 2023)算法,而其朴素实现会导致非确定性。为克服这一问题,我们分别输出每个 split 部分,并在后续 kernel 中执行确定性归约,从而同时保持性能与确定性。
3.4. FP4 Quantization-Aware Training
为了在部署时实现推理加速和内存节省,我们在后训练阶段引入 Quantization-Aware Training(QAT)(Jacob et al., 2018),使模型能够适应由量化带来的精度退化。我们将 FP4(MXFP4)量化(Rouhani et al., 2023)应用到两个部分:(1)MoE expert weights,它们是 GPU 内存占用的主要来源之一(OpenAI, 2025);(2)CSA 的 indexer 中的 Query-Key(QK)路径,其中 QK activations 完全以 FP4 缓存、加载和相乘,从而在长上下文场景下加速注意力分数计算。此外,在这一 QAT 过程中,我们还把 index scores I_:,: 从 FP32 进一步量化到 BF16。该优化为 top-k selector 带来 2× 加速,同时仍保持 99.7% 的 KV 条目召回率。
对于 MoE expert weights,遵循 QAT 的常见做法,优化器维护的 FP32 master weights 会先被量化为 FP4,再反量化回 FP8 进行计算。值得注意的是,我们的 FP4 到 FP8 反量化是无损的。这是因为 FP8(E4M3)相比 FP4(E2M1)多出 2 个 exponent bits,因此具有更大的动态范围。于是,只要每个 FP8 量化块(128 × 128 tiles)内各 FP4 子块(1 × 32 tiles)的最大与最小 scale factors 之比不超过某个阈值,那么细粒度尺度信息就能被 FP8 扩展后的动态范围完全吸收。我们通过经验验证确认当前权重满足这一条件。这让整个 QAT 流水线能够在无需任何修改的情况下完全复用现有 FP8 训练框架。在 backward pass 中,梯度相对于 forward pass 中同样的 FP8 权重计算,并直接传播回 FP32 master weights,这等价于在量化操作上施加 Straight-Through Estimator(STE)。这也避免了重新量化转置权重的需要。
在 RL 训练的推理与 rollout 阶段,由于不涉及 backward pass,我们直接使用真实的 FP4 量化权重,而不是模拟量化。这确保采样期间的模型行为与在线部署完全一致,同时还能减少 kernel 的内存加载以获得实际加速,并显著降低内存消耗。我们对 CSA 的 indexer 中 QK path 的处理方式也类似。
3.5. 训练框架
我们的训练框架建立在为 DeepSeek-V3(DeepSeek-AI, 2024)开发的可扩展且高效的基础设施之上。在训练 DeepSeek-V4 时,我们继承了这一坚实基础,同时引入了若干关键创新,以适配其新的架构组件——尤其是 Muon 优化器、mHC 和混合注意力机制——并保持高训练效率与稳定性。
3.5.1. Muon 的高效实现
Muon 优化器在计算参数更新时需要完整梯度矩阵,这与 Zero Redundancy Optimizer(ZeRO)(Rajbhandari et al., 2020)结合时构成挑战。传统 ZeRO 是为 AdamW 这类逐元素优化器设计的,在其中,单个参数矩阵可以跨多个 ranks 进行分片和更新。为解决这一冲突,我们为 Muon 设计了一种混合式 ZeRO bucket 分配策略。
对于稠密参数,我们限制 ZeRO 并行度的最大规模,并使用 knapsack 算法将参数矩阵分配到这些 ranks 上,确保每个 rank 管理的负载大体平衡。每个 rank 上的 bucket 会被填充到与各 ranks 中最大 bucket 相同的大小,以便高效执行 reduce-scatter 操作。在我们的设置下,这种填充通常只带来不到 10% 的内存开销,因为每个 rank 管理的参数矩阵不超过五个。当数据并行总体规模超过 ZeRO 的这一上限时,我们会在额外的数据并行组中冗余计算 Muon 更新,以计算换取更低的总 bucket 内存。
对于 MoE 参数,我们独立地优化每个 expert。我们先展平所有层中所有 experts 的 SwiGLU(Shazeer, 2020)down projection 矩阵,然后展平 up projection 矩阵和 gate 矩阵。随后,我们对展平后的向量进行填充,确保它可以在所有 ranks 之间均匀分配,并且不会切分任何逻辑上独立的矩阵。由于 experts 数量很大,我们不会对 MoE 参数施加 ZeRO 并行度上限,而填充开销也可以忽略。
此外,在每个 rank 上,形状相同且相邻的参数会被自动合并,从而使 Newton-Schulz 迭代可以批量执行,以获得更高硬件利用率。进一步地,我们观察到,Muon 中的 Newton-Schulz 迭代在用 BF16 矩阵乘法计算时依然稳定。利用这一点,我们进一步以 stochastic rounding 的方式,将需要在数据并行 ranks 之间同步的 MoE 梯度量化到 BF16 精度,使通信量减半。为避免低精度加法器引入的累加误差,我们用两阶段方法替代常规的树形或环形 reduce-scatter collective。首先,通过一次 all-to-all 操作在各 ranks 之间交换本地梯度,然后每个 rank 在本地使用 FP32 进行求和。这一设计保持了数值稳健性。
3.5.2. mHC 的低成本、内存高效实现
相比传统残差连接,引入 mHC 会增加激活内存消耗以及 pipeline stages 之间的通信量。为缓解这些成本,我们实现了若干优化策略。
首先,我们为训练与推理都精心设计并实现了 mHC 的融合 kernels。第二,我们引入了一种重计算策略,对中间 tensors 进行有选择的 checkpoint。具体来说,我们会重算层间的大多数 hidden states 以及所有归一化后的层输入,同时避免重算计算密集的操作。这在节省内存与额外计算开销之间取得了平衡。第三,我们调整了 DualPipe 1F1B 重叠方案,以适应增加的 pipeline 通信,并支持 mHC 中部分操作的并发执行。
综合来看,这些优化将 mHC 的 wall-time 额外开销限制到了重叠 1F1B pipeline stage 的 6.7%。关于工程优化的更多细节,可参见专门的 mHC 论文(Xie et al., 2026)。
3.5.3. 面向长上下文注意力的 Contextual Parallelism
传统 Context Parallelism(CP)沿序列维划分,每个 rank 维护连续的 s 个 token。这给我们的压缩注意力机制(即 CSA 与 HCA)带来两个挑战。一方面,训练样本由多个序列打包而成,而每个序列都会独立按 m(或 m')倍进行压缩,末尾不足 m 的 token 会被丢弃。因此,压缩后的 KV 长度通常小于 s/m,并且在不同 ranks 之间会有所不同。另一方面,压缩要求连续的 m 个 KV 条目,这可能会跨越两个相邻 CP ranks 的边界。
为解决这些挑战,我们设计了两阶段通信方案。在第一阶段,每个 rank i 将其最后 m 个未压缩 KV 条目发送给 rank i+1。然后,rank i+1 会把其中部分收到的条目与本地的 s 个未压缩 KV 条目一起压缩,产生固定长度 s/m + 1 的压缩条目,其中包含一些 padding 条目。在第二阶段,对所有 CP ranks 执行 all-gather 操作,以收集各自本地压缩得到的 KV 条目。之后,一个融合的 select-and-pad operator 会将它们重组为总长度为 cp_size · s/m 的完整压缩 KV 条目集合,所有 padding 条目都被放在末尾。对于 HCA 与 CSA 中的 indexer,每个 query token 可见的压缩 KV 条目范围可以按规则预计算。对于 CSA 中的稀疏注意力,top-k selector 会显式指定每个 query 可见压缩 KV 条目的索引。
3.5.4. 具有灵活激活 Checkpointing 的扩展自动微分
传统 activation checkpointing 的实现以整个模块为粒度,决定是否在 backward pass 中保留其输出激活或重新计算它们。这种粗粒度常常导致在重计算代价与激活内存占用之间做出次优权衡。另一种方法是手工实现整层的前向与反向逻辑,并显式管理 tensor checkpointing 状态。虽然这能实现细粒度控制,但会失去 automatic differentiation 框架的便利,大幅增加开发复杂度。
为了在不牺牲编程效率的情况下实现细粒度控制,我们实现了一种支持 automatic differentiation 的 tensor-level activation checkpointing 机制。使用该机制时,开发者只需实现 forward pass,并对单个 tensors 选择性标注,以便自动进行 checkpointing 与重计算。我们的框架利用 TorchFX(Reed et al., 2022)跟踪完整计算图。对于每个被标注的 tensor,它会执行一次向后遍历,以识别重计算该 tensor 所需的最小子图。我们将这些最小子图定义为 recomputation graphs,并在相应梯度计算之前将其插入 backward 逻辑中。
与手写实现相比,这一设计在训练时不会引入额外开销。该框架中的重计算通过直接释放被标注 tensor 的 GPU 内存,并复用重计算后 tensor 的存储指针来实现,不涉及任何 GPU 内存拷贝。此外,由于图跟踪是在模型的具体执行过程中进行的,我们可以跟踪每个 tensor 底层的存储指针,因此能够对共享存储的 tensors(例如 reshape 操作的输入与输出)自动去重重计算。这让开发者在标注重计算时无需推理底层内存细节。
3.6. 推理框架
我们的推理框架大体继承自 DeepSeek-V3,但在 KV Cache 管理方面有所不同。
3.6.1. KV Cache 结构与管理
为了高效管理 DeepSeek-V4 中由混合注意力机制带来的异构 KV caches,我们设计了定制化的 KV cache layout。该布局如图 6 所示,下面我们将详细说明。
DeepSeek-V4 中的异构 KV 条目
DeepSeek-V4 系列的混合注意力机制引入了多种类型的 KV 条目,它们具有不同的 Key-Value(KV)cache 大小和更新规则。用于稀疏选择的 lightning indexer 给 KV cache 引入了额外维度,其 embedding size 与主注意力中使用的维度不同。CSA 和 HCA 中采用的压缩技术分别把序列长度压缩到原来的 1/m 与 1/m',从而降低整体 KV cache 大小。结果是,不同层上的 KV cache 大小会有所不同。此外,Sliding Window Attention(SWA)层也具有不同的 KV cache 大小,以及独立的 cache hit 和 eviction 策略。在压缩分支中,每 m 个 token 会生成一个 KV 条目。当剩余 token 数不足以完成压缩时,所有待处理 token 及其对应 hidden states 都必须保留在缓冲区中,直到压缩操作可以执行。这些缓冲 token 代表了由位置上下文决定的序列状态,因此也需要纳入 KV cache 框架进行管理。
管理混合注意力 KV Cache 的挑战
混合注意力机制违背了 PagedAttention 及其变体背后的基本假设。尽管近期的混合 KV cache 管理算法(例如 Jenga(Zhang et al., 2025a)、Hymba(Dong et al., 2025))面向通用混合注意力模型或特定结构,但有两个主要障碍阻止我们在 PagedAttention 框架下统一所有层的 KV caches:
- 多样的 cache 策略,例如 Sliding Window Attention 所使用的策略。
- 高性能注意力 kernels 所施加的约束,包括对齐要求。
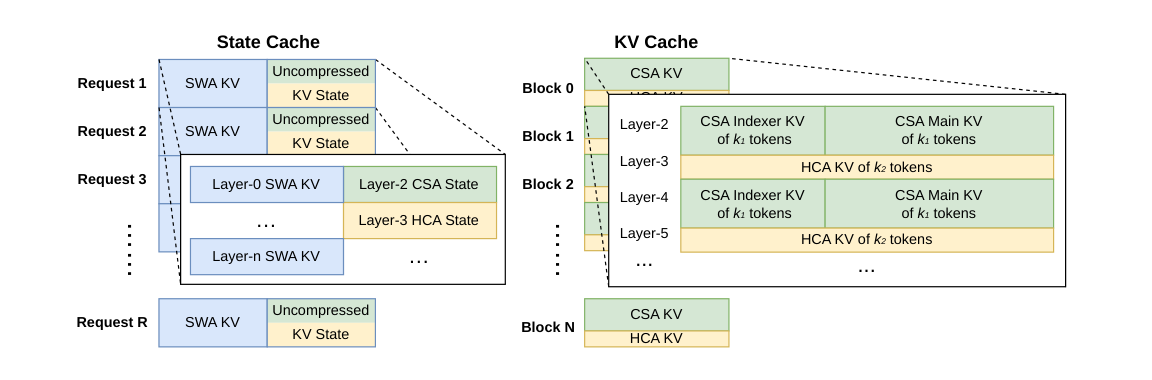
为了实现 DeepSeek-V4 的高效 KV cache 管理,我们设计了相应策略来克服上述两个挑战。
用于 SWA 与未压缩尾部 token 的 State Cache
为解决第一个障碍,我们采用了替代性的 cache 管理机制。由于 SWA 的设计目标就是在有限 KV cache 大小下提升性能,因此将它与压缩分支中的未压缩尾部 token 一同视作 state-space model 是合理的。相应的 KV cache 于是可以被看作仅依赖当前位置的、与具体序列相关的状态。因此,我们预分配了一个固定且有限大小的 state cache 池,并将其动态分配给每个序列。
稀疏注意力 Kernel 协同设计
对于第二个障碍,传统高性能注意力 kernels 通常假设每个 block 具有固定数量 B 的 token,以便优化性能;这在 CSA 中对应 B·m 个原始 token,在 HCA 中对应 B·m' 个原始 token。通过使用高性能稀疏注意力 kernel,不同层可以在不损失性能的情况下容纳可变的每块 token 数。要做到这一点,需要对 KV cache 布局和稀疏注意力 kernel 进行协同设计。例如,为了对齐 cache lines 而对 blocks 进行 padding 可以提升性能。因此,对于压缩率为 m 的 CSA 和压缩率为 m' 的 HCA,每个 block 所覆盖的原始 token 数都可以取 lcm(m, m')(这两个压缩率的最小公倍数)的任意倍数。
3.6.2. 磁盘上的 KV Cache 存储
在服务 DeepSeek-V4 时,我们利用一种 on-disk KV cache storage 机制,以消除共享前缀请求的重复 prefilling。对于 CSA/HCA 中的压缩 KV 条目,以及 Sliding Window Attention(SWA)中的未压缩 KV 条目,我们分别设计了不同的存储管理方案。
对于 CSA 和 HCA,我们只需把所有压缩 KV 条目存储到磁盘中。当某个请求命中已存储前缀时,我们读取并复用与该前缀对应的压缩 KV 条目,一直复用到最后一个完整压缩块。特别地,对于尾部未完整压缩块中的前缀 token,我们仍然需要重新计算它们,以恢复未压缩 KV 条目,因为 CSA 和 HCA 的未压缩 KV 条目不会被存储。
对于 SWA KV 条目,由于它们没有被压缩且存在于每一层,其体积约为压缩后的 CSA/HCA KV 条目的 8 倍。为高效处理这些体积很大的 SWA KV 条目,我们提出并实现了三种不同策略来管理磁盘上的 SWA KV 条目,每种策略在存储开销与计算冗余之间提供不同权衡:
- Full SWA Caching。该策略存储所有 token 的完整 SWA KV 条目,从而保证计算上的零冗余。在该策略下,当命中某个前缀时,只需读取该前缀中最后
n_win个 token 的磁盘缓存,就可以重建命中前缀的 SWA KV 条目。尽管计算冗余为零,但这一策略对现代基于 SSD 的存储系统并不高效——每个命中请求实际上只会访问存储的 SWA KV cache 的很小一部分,这会导致写密集且不均衡的访问模式。 - Periodic Checkpointing。该策略对每
p个 token 中最后n_win个 token 的 SWA KV 条目进行 checkpoint,其中p是可调参数。对于命中前缀,我们会加载最近一次 checkpoint 的状态,然后重新计算剩余尾部 token。通过调节p,该策略可以按需在存储与计算之间进行权衡。 - Zero SWA Caching。该策略完全不存储任何 SWA KV 条目。对于命中前缀,我们需要执行更多重计算以恢复 SWA KV 条目。具体来说,在每个注意力层中,每个 token 的 SWA KV 条目只依赖于上一层中最近
n_win个 token 的 SWA KV 条目。因此,利用已缓存的 CSA 与 HCA KV 条目,对一个L层模型而言,只需重新计算最后n_win · L个 token,就足以恢复最后n_win个 SWA KV 条目。
根据具体部署场景,我们选择最合适的策略,以达到期望的存储与计算权衡。
4. 预训练
4.1. 数据构建
在 DeepSeek-V3 的预训练数据之上,我们致力于构建一个更加多样、质量更高、有效上下文更长的训练语料。我们持续迭代数据构建流水线。对于 web 来源数据,我们实现了过滤策略,以去除批量自动生成内容和模板化内容,从而降低模型坍塌的风险(Zhu et al., 2024)。数学与编程语料仍然是训练数据的核心组成部分,我们还在中期训练阶段引入 agentic data,以进一步增强 DeepSeek-V4 系列的代码能力。对于多语言数据,我们为 DeepSeek-V4 构建了更大的语料,从而提升其对不同文化中长尾知识的捕获能力。对于 DeepSeek-V4,我们尤其重视长文档数据整理,优先纳入 scientific papers、technical reports 以及其他体现独特学术价值的材料。综合以上,我们的预训练语料包含超过 32T token,涵盖数学内容、代码、网页、长文档以及其他高质量类别。
对于预训练数据,我们大体沿用了 DeepSeek-V3 的相同预处理策略。在 tokenizer 方面,我们在 DeepSeek-V3 tokenizer 的基础上引入了少量用于上下文构造的特殊 token,并继续将词表大小保持为 128K。我们还继承了 DeepSeek-V3 的 token-splitting(DeepSeek-AI, 2024)和 Fill-in-Middle(FIM)(DeepSeek-AI, 2024)策略。受 Ding et al.(2024)启发,我们将不同来源的文档打包成合适的序列,以尽量减少样本截断。与 DeepSeek-V3 不同的是,我们在预训练中采用 sample-level attention masking。
4.2. 预训练设定
4.2.1. 模型设定
DeepSeek-V4-Flash
我们将 Transformer 层数设为 43,hidden dimension d 设为 4096。对于前两层,我们使用纯 sliding window attention。对于后续层,我们交错使用 CSA 与 HCA。对于 CSA,我们将压缩率 m 设为 4,indexer query heads 数量 n_h^I 设为 64,indexer head dimension c_I 设为 128,用于 sparse attention 选择的 KV 条目数(即 attention top-k)设为 512。对于 HCA,我们将压缩率 m' 设为 128。对于 CSA 与 HCA,我们都将 query heads 数量 n_h 设为 64,head dimension c 设为 512,query compression dimension d_c 设为 1024。输出投影分组数 g 设为 8,每个中间注意力输出的维度 d_g 设为 1024。对于额外的 sliding window attention 分支,窗口大小 n_win 设为 128。我们在所有 Transformer blocks 中都使用 MoE 层,但前 3 个 MoE 层使用 Hash routing 策略。每个 MoE 层由 1 个 shared expert 和 256 个 routed experts 组成,每个 expert 的中间 hidden dimension 为 2048。在这些 routed experts 中,每个 token 会激活 6 个 experts。multi-token prediction depth 设为 1。对于 mHC,扩展因子 n_hc 设为 4,Sinkhorn-Knopp 迭代次数 t_max 设为 20。在这一配置下,DeepSeek-V4-Flash 总参数量为 284B,其中每个 token 激活 13B 参数。
DeepSeek-V4-Pro
我们将 Transformer 层数设为 61,hidden dimension d 设为 7168。对于前两层,我们使用 HCA。对于后续层,我们交错使用 CSA 与 HCA。对于 CSA,我们将压缩率 m 设为 4,indexer query heads 数量 n_h^I 设为 64,indexer head dimension c_I 设为 128,用于 sparse attention 选择的 KV 条目数(即 attention top-k)设为 1024。对于 HCA,我们将压缩率 m' 设为 128。对于 CSA 与 HCA,我们都将 query heads 数量 n_h 设为 128,head dimension c 设为 512,query compression dimension d_c 设为 1536。输出投影分组数 g 设为 16,每个中间注意力输出维度 d_g 设为 1024。对于额外的 sliding window attention 分支,窗口大小 n_win 设为 128。我们在所有 Transformer blocks 中都使用 MoE 层,但前 3 个 MoE 层使用 Hash routing 策略。每个 MoE 层由 1 个 shared expert 和 384 个 routed experts 组成,每个 expert 的中间 hidden dimension 为 3072。在这些 routed experts 中,每个 token 会激活 6 个 experts。multi-token prediction depth 设为 1。对于 mHC,扩展因子 n_hc 设为 4,Sinkhorn-Knopp 迭代次数 t_max 设为 20。在这一配置下,DeepSeek-V4-Pro 总参数量为 1.6T,其中每个 token 激活 49B 参数。
4.2.2. 训练设定
DeepSeek-V4-Flash
我们对大多数参数使用 Muon 优化器(Jordan et al., 2024;Liu et al., 2025),但对 embedding 模块、prediction head 模块和所有 RMSNorm 模块的权重使用 AdamW 优化器(Loshchilov and Hutter, 2017)。对于 AdamW,我们将其超参数设为 β1 = 0.9、β2 = 0.95、ε = 10^-20、weight_decay = 0.1。对于 Muon,我们将动量设为 0.95,权重衰减设为 0.1,并将每个更新矩阵的 RMS 重缩放到 0.18,以便复用 AdamW 的学习率。我们在 32T token 上训练 DeepSeek-V4-Flash,并且与 DeepSeek-V3 一样,也采用 batch size scheduling 策略,将 batch size(以 token 计)从一个较小值逐步提升到 75.5M,并在大部分训练过程中保持在 75.5M。学习率在前 2000 步中线性 warmup,在大部分训练过程中保持为 2.7 × 10^-4。在训练接近结束时,我们再按照 cosine schedule 将学习率衰减到 2.7 × 10^-5。训练从 4K 的序列长度开始,然后我们逐步将训练序列长度扩展到 16K、64K 和 1M。对于 sparse attention 的设置,我们先在前 1T token 训练中用 dense attention 对模型进行 warmup,然后在序列长度到达 64K 时引入 sparse attention,并在剩余训练过程中保持 sparse attention。引入注意力稀疏性时,我们先安排一个短阶段对 CSA 中的 lightning indexer 进行 warmup,然后在大部分训练过程中使用 sparse attention 训练模型。对于 auxiliary-loss-free load balancing,我们将 bias update speed 设为 0.001。对于 balance loss,我们将其 loss weight 设为 0.0001,以避免单个序列内部出现极端不均衡。MTP loss weight 在大多数训练过程中设为 0.3,而在学习率开始衰减时设为 0.1。
DeepSeek-V4-Pro
除了某些超参数取值不同外,DeepSeek-V4-Pro 的训练设置与 DeepSeek-V4-Flash 基本一致。我们对大多数参数使用 Muon 优化器,但对 embedding 模块、prediction head 模块和所有 RMSNorm 模块权重使用 AdamW 优化器。AdamW 和 Muon 的超参数与 DeepSeek-V4-Flash 相同。我们在 33T token 上训练 DeepSeek-V4-Pro,并同样采用 batch size scheduling 策略,其最大 batch size 为 94.4M token。学习率调度策略与 DeepSeek-V4-Flash 基本相同,但峰值学习率设为 2.0 × 10^-4,最终学习率设为 2.0 × 10^-5。训练也从 4K 序列长度开始,再逐步扩展到 16K、64K 和 1M。相比 DeepSeek-V4-Flash,DeepSeek-V4-Pro 先使用更长阶段的 dense attention;之后引入 sparse attention 的策略与 DeepSeek-V4-Flash 相同,遵循两阶段训练方法。对于 auxiliary-loss-free load balancing,我们将 bias update speed 设为 0.001。对于 balance loss,我们将其 loss weight 设为 0.0001,以避免单个序列内部出现极端不均衡。MTP loss weight 在大多数训练过程中设为 0.3,在学习率开始衰减时设为 0.1。
4.2.3. 缓解训练不稳定性
训练万亿参数级 MoE 模型会带来显著的稳定性挑战,DeepSeek-V4 系列也不例外。我们在训练过程中遇到了明显的不稳定问题。虽然简单回滚可以暂时恢复训练状态,但它并不是长期解决方案,因为它不能阻止 loss spikes 的再次出现。经验上,我们发现 spikes 的出现始终与 MoE 层中的异常值有关,而 routing 机制本身似乎会加剧这些异常值的形成。因此,我们试图从两个维度来处理这一问题:打破由 routing 诱发的恶性循环,以及直接抑制异常值。幸运的是,我们找到了两种能够有效维持训练稳定性的实用技术。虽然我们目前对其底层机制还缺乏完整理论理解,但我们仍公开分享这些技术,以促进社区进一步探索。
Anticipatory Routing
我们发现,将 backbone network 与 routing network 的同步更新解耦,能够显著提升训练稳定性。因此,在步骤 t,我们使用当前网络参数 θ_t 进行特征计算,但 routing indices 则使用历史网络参数 θ_(t-Δt) 计算并应用。实践中,为了避免两次加载模型参数所造成的开销,我们会在 t-Δt 步提前取出 t 步所需数据。我们会“预先”计算并缓存稍后在 t 步使用的 routing indices,这也是我们将这一方法命名为 Anticipatory Routing 的原因。我们还在基础设施层面进行了大量优化。第一,由于预计算 routing indices 只需要在数据上执行一次前向传播,我们精心编排了 pipeline 执行,并让计算与 Expert Parallelism(EP)通信重叠,成功将 Anticipatory Routing 额外带来的 wall-clock time 开销限制在约 20%。第二,我们引入了自动检测机制:当发生 loss spike 时,系统会触发一次短回滚,并仅在此时启用 Anticipatory Routing;运行一段时间后,系统再恢复到标准训练模式。最终,这种动态应用方式使我们几乎不增加总体训练开销,就能规避 loss spikes,同时不损害模型性能。
SwiGLU Clamping
在先前文献中(Bello et al., 2017;Riviere et al., 2024),clamping 已被显式用于约束数值范围,从而增强训练稳定性。在我们的实际训练中,我们经验性地发现,采用 SwiGLU clamping(OpenAI, 2025)能够有效消除异常值,并显著帮助稳定训练过程,同时不损害性能。在 DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 的整个训练过程中,我们将 SwiGLU 的线性分量夹紧到 [-10, 10] 区间,同时将 gate 分量的上界限制为 10。
4.3. 评测
4.3.1. 评测基准
对于基础模型的评测,我们考虑四个关键维度的基准:世界知识、语言理解与推理、代码与数学,以及长上下文处理。
世界知识基准包括 AGIEval(Zhong et al., 2023)、C-Eval(Huang et al., 2023)、CMMLU(Li et al., 2023)、MMLU(Hendrycks et al., 2020)、MMLU-Redux(Gema et al., 2024)、MMLU-Pro(Wang et al., 2024b)、MMMLU(OpenAI, 2024a)、MultiLoKo(Hupkes and Bogoychev, 2025)、Simple-QA verified(Haas et al., 2025)、SuperGPQA(Du et al., 2025)、FACTS Parametric(Cheng et al., 2025)以及 TriviaQA(Joshi et al., 2017)。
语言理解与推理基准包括 BigBench Hard(BBH)(Suzgun et al., 2022)、DROP(Dua et al., 2019)、HellaSwag(Zellers et al., 2019)、CLUEWSC(Xu et al., 2020)以及 WinoGrande(Sakaguchi et al., 2019)。
代码与数学基准包括 BigCodeBench(Zhuo et al., 2025)、HumanEval(Chen et al., 2021)、GSM8K(Cobbe et al., 2021)、MATH(Hendrycks et al., 2021)、MGSM(Shi et al., 2023)以及 CMath(Wei et al., 2023)。
长上下文基准包括 LongBench-V2(Bai et al., 2025b)。
4.3.2. 评测结果
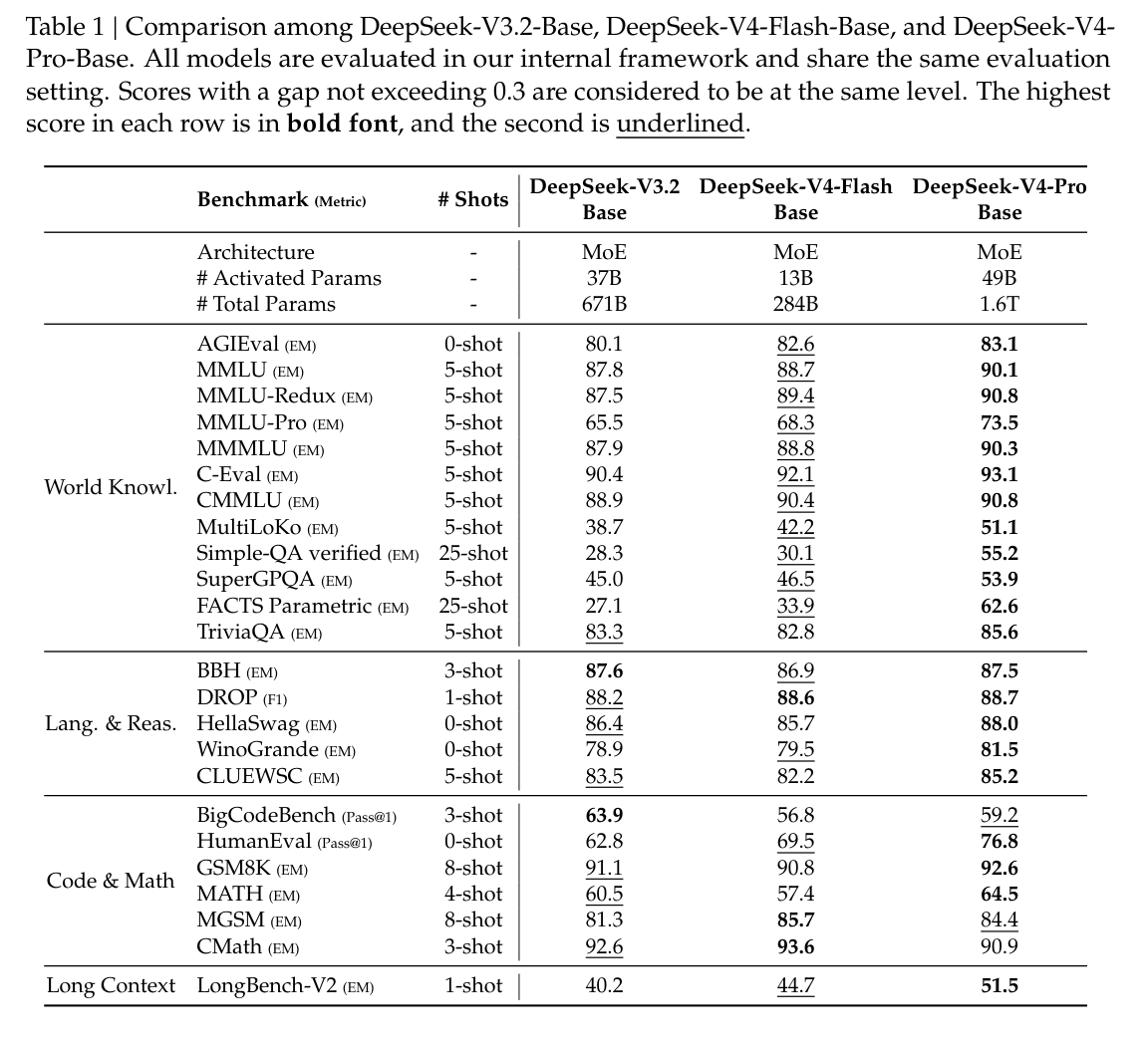
在表 1 中,我们对 DeepSeek-V3.2、DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 的基础模型进行了详细比较,所有模型都在统一的内部框架下、以严格一致的设置进行评测。
将 DeepSeek-V4-Flash-Base 与 DeepSeek-V3.2-Base 对比,可以看到一个很有说服力的效率故事。尽管其激活参数量与总参数量都显著更小,DeepSeek-V4-Flash-Base 却在广泛基准上超过了 DeepSeek-V3.2-Base。这一优势在世界知识任务和具有挑战性的长上下文场景中尤其明显。这些结果表明,DeepSeek-V4-Flash-Base 在架构改进、数据质量提升和训练优化上的收益,使其即使在更紧凑的参数预算下也能取得更优表现,在大多数评测中有效超过更大的 DeepSeek-V3.2-Base。
此外,DeepSeek-V4-Pro-Base 进一步展示出决定性的能力跃升,几乎全面压制 DeepSeek-V3.2-Base 和 DeepSeek-V4-Flash-Base。随着几乎所有类别上的提升,DeepSeek-V4-Pro-Base 在最具挑战性的基准上达到了 DeepSeek 基础模型中的新高点。在知识密集型评测中,它取得了显著增益,同时在长上下文理解上也有大幅推进。在大多数推理与代码基准上,DeepSeek-V4-Pro-Base 也超过了前两个模型。这种全面提升确认了 DeepSeek-V4-Pro-Base 是 DeepSeek 系列中最强的基础模型,在知识、推理、代码与长上下文能力谱系上都超过其前代模型。
5. 后训练
5.1. 后训练流水线
在预训练之后,我们进行了后训练阶段,以得到 DeepSeek-V4 系列的最终模型。尽管训练流水线总体上与 DeepSeek-V3.2 相似,但我们做了一个关键的方法学替换:将混合 Reinforcement Learning(RL)阶段完全替换为 On-Policy Distillation(OPD)。
5.1.1. 专家模型训练
领域专家的开发是在适配 DeepSeek-V3.2 训练流水线的基础上完成的。具体而言,每个模型会依次经过初始 fine-tuning 阶段,以及随后在领域专用 prompts 与奖励信号引导下进行的 Reinforcement Learning(RL)。在 RL 阶段,我们实现了 Group Relative Policy Optimization(GRPO)算法,其超参数与我们此前研究(DeepSeek-AI, 2025;DeepSeek-AI, 2025)中的设置基本保持一致。
推理努力
众所周知,模型在推理任务上的表现,从根本上受其投入的计算努力所支配。因此,我们在不同的 RL 配置下训练了不同的专家模型,以便开发适配不同推理能力的模型。如表 2 所示,DeepSeek-V4-Pro 与 DeepSeek-V4-Flash 都支持三种特定的推理努力模式。对每一种模式,我们在 RL 训练中都使用不同的长度惩罚和上下文窗口,从而得到不同的推理输出 token 长度。为了整合这些不同推理模式,我们使用由 <think> 和 </think> token 划定的专门响应格式。此外,对于 “Think Max” 模式,我们会在 system prompt 开头插入特定指令来引导模型的推理过程,如表 3 所示。
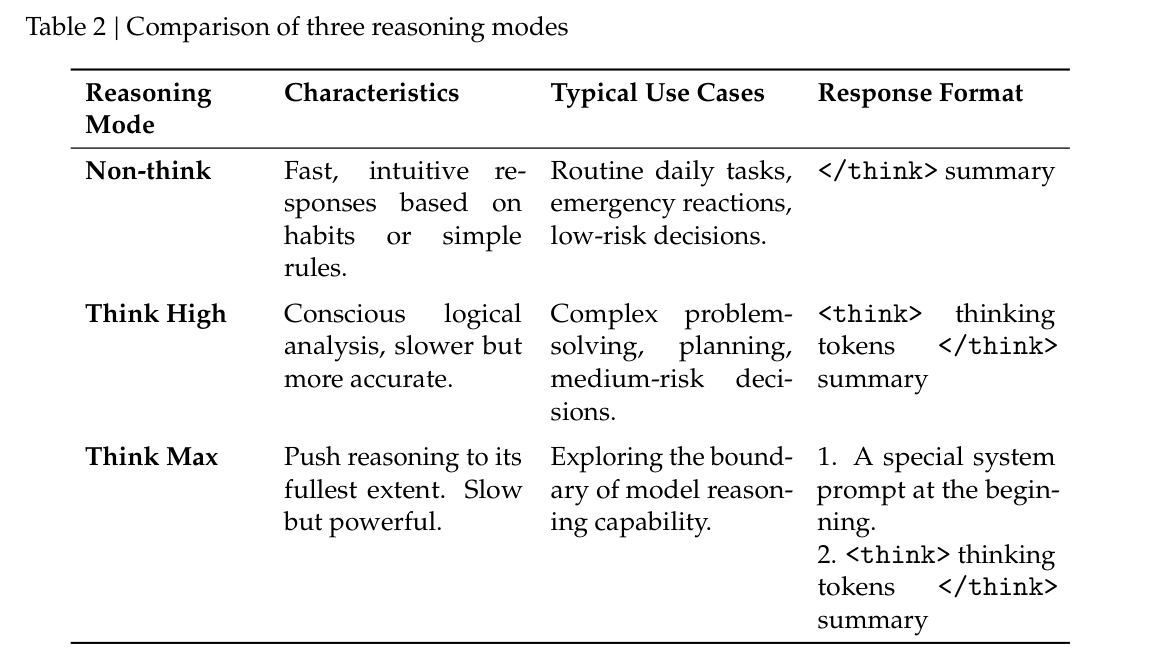
- Non-think:基于习惯或简单规则给出快速、直觉式响应。典型用途包括日常常规任务、紧急反应和低风险决策。响应格式为
</think> summary。 - Think High:进行有意识的逻辑分析,较慢但更准确。典型用途包括复杂问题求解、规划以及中等风险决策。响应格式为
<think> thinking tokens </think> summary。 - Think Max:将推理推进到最大限度,速度较慢但能力更强。典型用途包括探索模型推理能力的边界。响应格式包括:(1)在开头插入专门的 system prompt;(2)
<think> thinking tokens </think> summary。
Generative Reward Model
通常,容易验证的任务可以通过简单的 rule-based verifiers 或测试用例进行有效优化。相比之下,难以验证的任务传统上依赖 Reinforcement Learning from Human Feedback(RLHF),后者需要大量人工标注来训练一个标量奖励模型。然而,在 DeepSeek-V4 系列的后训练阶段,我们不再使用这类传统的标量奖励模型。相反,为了处理难以验证的任务,我们整理了 rubric-guided RL data,并使用 Generative Reward Model(GRM)来评估 policy trajectories。关键在于,我们直接对 GRM 本身进行 RL 优化。在这一范式中,actor network 原生地充当 GRM,因此可以同时优化模型的评估(judging)能力与其常规生成能力。通过统一这两个角色,模型内部的推理能力会天然融合到其评估过程中,从而产生高度稳健的评分。此外,这种方法只需极少量且多样化的人类标注就能取得更优表现,因为模型会利用自身逻辑在复杂任务之间泛化。

Reasoning Effort: Absolute maximum with no shortcuts permitted.
You MUST be very thorough in your thinking and comprehensively decompose the
problem to resolve the root cause, rigorously stress-testing your logic against all potential
paths, edge cases, and adversarial scenarios.
Explicitly write out your entire deliberation process, documenting every intermediate
step, considered alternative, and rejected hypothesis to ensure absolutely no assumption
is left unchecked.
其直译如下:
推理努力:绝对最大,不允许任何捷径。
你必须在思考时极其彻底,并全面拆解问题,以解决根本原因;必须针对所有可能路径、边界情况和对抗性场景,对你的逻辑进行严格压力测试。
明确写出你的完整思考过程,记录每一个中间步骤、考虑过的备选方案以及被否决的假设,以确保绝对没有任何未经检验的假设被遗漏。
Tool-Call Schema 与特殊 Token
与前一版本一致,我们使用专门的 <think></think> 标签来界定推理路径。在 DeepSeek-V4 系列中,我们引入了一种新的 tool-call schema,它使用特殊 token |DSML|,并采用基于 XML 的工具调用格式,如表 4 所示。我们的实验表明,XML 格式能够有效缓解 escaping 失败并减少 tool-call 错误,为模型与工具交互提供更稳健的接口。
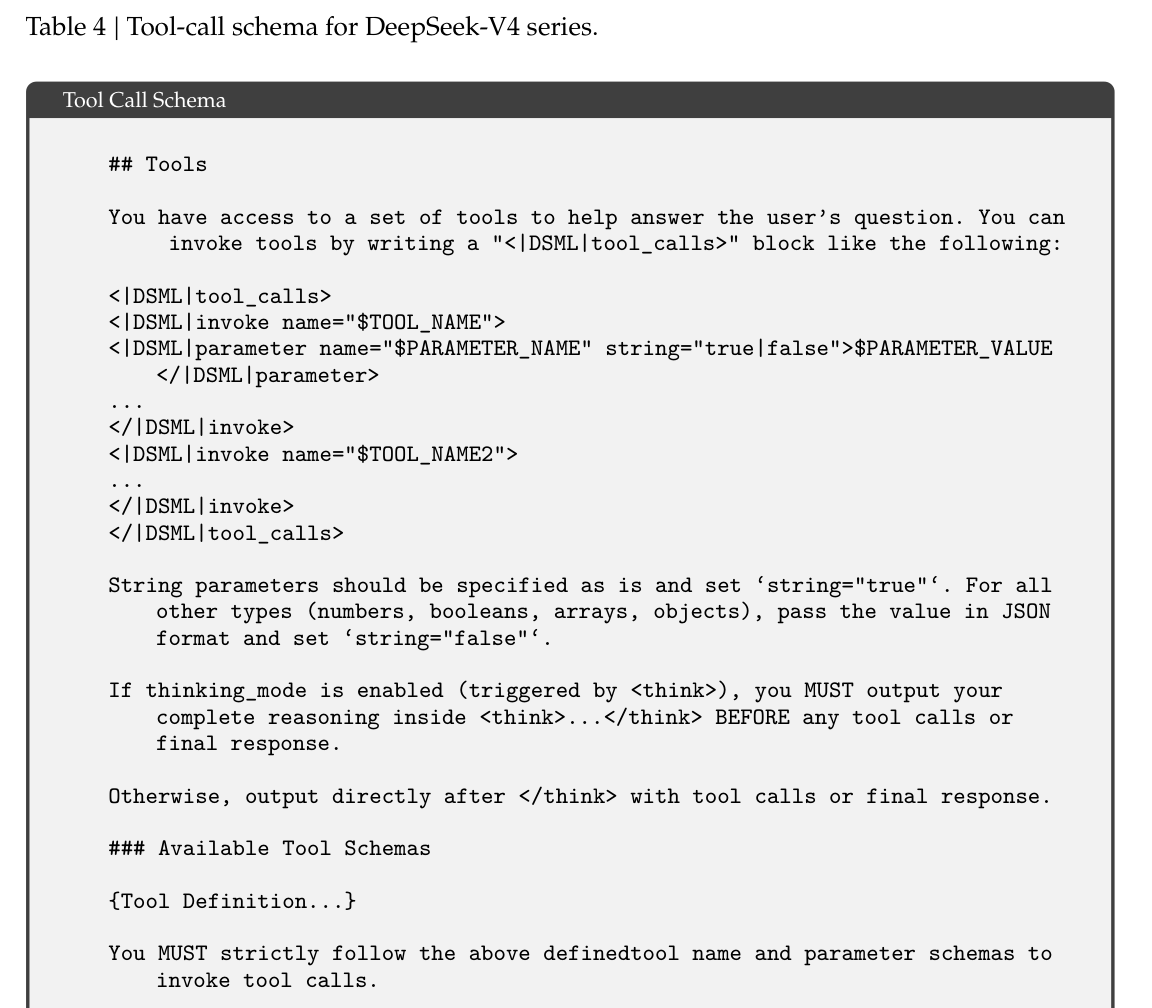
其核心格式如下:
## Tools
You have access to a set of tools to help answer the user’s question. You can
invoke tools by writing a "<|DSML|tool_calls>" block like the following:
<|DSML|tool_calls>
<|DSML|invoke name="$TOOL_NAME">
<|DSML|parameter name="$PARAMETER_NAME" string="true|false">$PARAMETER_VALUE
</|DSML|parameter>
...
</|DSML|invoke>
<|DSML|invoke name="$TOOL_NAME2">
...
</|DSML|invoke>
</|DSML|tool_calls>
其余约束包括:
- 字符串参数应按原样指定,并设置
string="true"。 - 所有其他类型(数字、布尔值、数组、对象)都应以 JSON 格式传值,并设置
string="false"。 - 如果启用了
thinking_mode(由<think>触发),那么在任何 tool calls 或最终响应之前,必须先在<think>...</think>内输出完整推理。 - 否则,应在
</think>之后直接输出 tool calls 或最终响应。 - 必须严格遵循上面定义的 tool name 与 parameter schemas 来调用工具。
交错思考
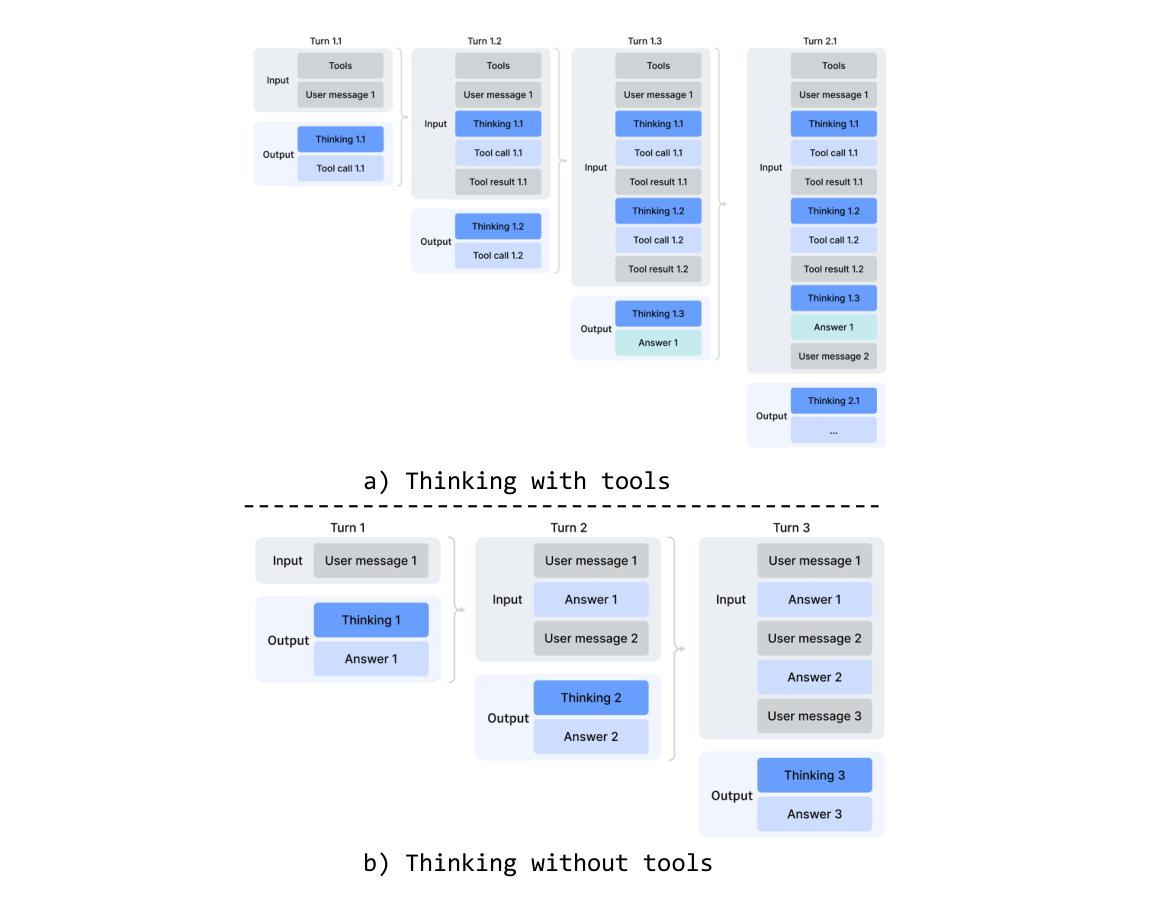
DeepSeek-V3.2 引入了一种上下文管理策略:它会在工具结果往返轮次之间保留推理痕迹,但在新用户消息到来时将其丢弃。虽然这种方式是有效的,但在复杂 agentic 工作流中仍会造成不必要的 token 浪费——每次新的用户轮次都会清空所有已累积的推理内容,迫使模型从头重建其问题求解状态。借助 DeepSeek-V4 系列扩展到 1M-token 的上下文窗口,我们进一步改进了这一机制,以最大化交错思考在 agent 环境中的有效性:
- 工具调用场景。如图 7(a) 所示,所有推理内容在整个对话过程中都被完整保留。不同于 DeepSeek-V3.2 会在每个新的用户轮次到来时丢弃 thinking traces,DeepSeek-V4 系列会跨所有轮次保留完整推理历史,包括跨越用户消息边界的保留。这使模型能够在长时程 agent 任务中维持连贯、累积的 chain of thought。
- 一般对话场景。如图 7(b) 所示,原有策略被保留:一旦新的用户消息到来,就丢弃前几轮的推理内容,从而在持久推理痕迹收益有限的设置下保持上下文简洁。
与 DeepSeek-V3.2 一样,那些通过用户消息模拟工具交互的 agent 框架(例如 Terminus)可能不会触发工具调用上下文路径,因此可能无法从增强后的推理持久化中获益。对于这类架构,我们仍然推荐使用 non-think 模型。
Quick Instruction
在 chatbot 场景中,在生成响应之前必须先执行一些辅助任务(例如判断是否触发 web search、intent recognition 等)。传统上,这些任务由单独的小模型处理,而由于它无法复用现有 KV cache,因此会产生冗余 prefilling。为克服这一局限,我们引入了 Quick Instruction。我们直接将一组专用特殊 token 追加到输入序列中,每个 token 对应一个特定辅助任务。通过直接复用已经计算好的 KV cache,这一机制完全避免了冗余 prefilling,并允许某些任务——如生成搜索查询,以及判定 authority 与 domain——并行执行。因此,这种方法显著减少了用户感知到的 time-to-first-token(TTFT),并消除了维护和迭代额外小模型的工程开销。支持的 Quick Instruction tokens 如表 5 所示。

<|action|>:判断用户提示是否需要 web search,还是可以直接回答。格式:...<|User|>{prompt}<|Assistant|><think><|action|><|title|>:在 assistant 首次响应后生成简洁的对话标题。格式:...<|Assistant|>{response}<|end_of_sentence|><|title|><|query|>:为用户提示生成搜索查询。格式:...<|User|>{prompt}<|query|><|authority|>:对用户提示对来源权威性的需求进行分类。格式:...<|User|>{prompt}<|authority|><|domain|>:识别用户提示所属领域。格式:...<|User|>{prompt}<|domain|><|extracted_url|>与<|read_url|>:判断用户提示中的每个 URL 是否应被抓取和读取。格式:...<|User|>{prompt}<|extracted_url|>{url}<|read_url|>
5.1.2. On-Policy Distillation
在通过专门 fine-tuning 和 reinforcement learning 训练出多个领域专家之后,我们采用多教师 On-Policy Distillation(OPD)作为将专家能力合并到最终模型中的主要技术。OPD 已成为一种高效的后训练范式,可将领域专家的知识与能力迁移到单一统一模型中。其方式是让 student 在自身生成的 trajectories 上学习 teacher models 的输出分布。形式上,给定一组 N 个专家模型 {π_E1, π_E2, ..., π_EN},OPD 的目标函数定义为:
L_OPD(θ) = Σ_i w_i · D_KL(π_θ || π_Ei) (29)
在这一形式中,w_i 表示分配给每个专家的权重,通常由该专家的相对重要性决定。为了计算反向 KL 损失 D_KL(π_θ || π_Ei),需要从 student π_θ 中采样训练 trajectories,以维持 on-policy learning。其底层逻辑确保统一策略 π_θ 会针对当前任务上下文有选择地向相关专家学习(例如在数学推理任务中对齐数学专家,在编程任务中对齐代码专家)。通过这一机制,物理上彼此独立的专家权重中的知识,会通过 logits 级别对齐被整合到统一参数空间中,从实践上绕过传统权重合并或混合 RL 技术中常见的性能退化。在该阶段,我们使用了十多个覆盖不同领域的教师模型来蒸馏单一 student 模型。
在处理上述 OPD 目标时,先前工作通常会把全词表 KL 损失简化为每个 token 位置上的 token-level KL 估计,并通过在 policy loss 计算中用 sg log(π_E(y_t|x,y_<t) / π_θ(y_t|x,y_<t))(sg 表示 stop gradient)替代每个 token 的 advantage estimate,以复用 RL 框架。尽管这种做法资源开销较低,但会导致梯度估计方差较高,并常常引起训练不稳定。因此,我们在 OPD 中采用全词表 logit distillation。在计算 reverse KL loss 时保留完整的 logit 分布,可以得到更稳定的梯度估计,并确保对 teacher 知识的忠实蒸馏。下一小节中,我们将说明使全词表 OPD 能够在大规模下可行的工程工作。
5.2. RL 与 OPD 基础设施
我们的后训练基础设施建立在为 DeepSeek-V3.2 开发的可扩展框架之上。具体来说,我们集成了第 3.5 节所述的同一套分布式训练栈,以及此前引入的用于高效 auto-regressive sampling 的 rollout engine。在此基础上,我们在本工作中引入以下几项主要增强。这些设计使得我们能够高效执行涉及十多个不同 teacher models 的超长上下文 RL 与 OPD 合并任务,从而显著加快模型发布的迭代周期。
5.2.1. FP4 量化集成
我们采用 FP4(MXFP4)量化来同时加速 rollouts 和所有仅推理前向过程,包括 teacher 模型与 reference 模型的前向过程,从而降低内存流量和采样时延。如第 3.4 节所述,在 rollout 与推理阶段,我们直接使用原生 FP4 权重。对于训练步骤,则通过无损的 FP4 到 FP8 反量化来模拟 FP4 量化,从而可以无缝复用现有 FP8 mixed-precision 框架及其 FP32 master weights,并且无需修改 backward pipeline。
5.2.2. 面向全词表 OPD 的高效 Teacher 调度
我们的框架支持全词表 On-Policy Distillation(OPD),并且 teacher 数量在效果上不受上限限制,每个 teacher 都可能拥有万亿级参数。为此,所有 teacher weights 都会被卸载到集中式分布式存储中,并在 teacher forward pass 期间按需加载,同时采用类似 ZeRO 的参数分片,以缓解 I/O 和 DRAM 压力。进一步地,当词表大小 |V| > 100k 时,即便把 logits 回写到磁盘上,为所有 teachers 物化 logits 也是不可承受的。我们对此的解决办法是在 forward pass 期间只把最后一层的 teacher hidden states 缓存在一个集中式 buffer 中。到训练时,再取回这些缓存状态,并通过相应的 prediction head 模块在线重建完整 logits。该设计的重计算开销几乎可以忽略,同时彻底绕过了显式物化 logits 所带来的内存负担。为了缓解 teacher prediction head 的 GPU 内存占用,我们在数据分发时按 teacher index 排序训练样本。这保证每个不同的 teacher head 在每个 mini-batch 中只需要加载一次,并且任意时刻设备内存中最多只有一个 teacher head。所有参数与 hidden state 的加载和卸载操作都在后台异步进行,不会阻塞关键路径上的计算。最后,teacher 与 student logits 之间的精确 KL divergence 通过专门的 TileLang kernel 计算,以加速计算并减少动态内存分配。
5.2.3. 可抢占且容错的 Rollout 服务
为了在支持高优先级任务快速调度硬件资源的同时最大化 GPU 资源利用率,我们的 GPU 集群采用了集群范围内的抢占式任务调度器,因此任何正在运行的任务都可能在任何时候被抢占。同时,在大规模 GPU 集群中,硬件故障也很常见。为此,我们实现了一个面向 RL/OPD rollout 的可抢占且容错的 LLM generation 服务。
具体来说,我们为每个生成请求实现了 token 粒度的 Write-Ahead Log(WAL)。每当某个请求生成出一个新 token,我们都会立刻将其追加到该请求的 WAL 中。在发生抢占时,我们暂停推理引擎,并保存尚未完成请求的 KV cache。恢复运行时,我们使用持久化的 WAL 和保存下来的 KV cache 继续 decoding。即便发生致命硬件错误,我们也能借助 WAL 中持久化的 tokens 重新运行 prefill 阶段,从而重建 KV cache。
需要强调的是,从头重新生成未完成请求在数学上是不正确的,因为这会引入长度偏差。由于较短响应更容易在中断中幸存,如果每次中断后都从头重生,那么模型在中断发生时就会更倾向于输出较短序列。若推理栈是 batch-invariant 且 deterministic,那么也可以通过使用一致的随机种子来重新生成,避免这一正确性问题。但这种做法仍需额外重新执行 decoding 阶段,因此效率远低于我们的 token-granular WAL 方法。
5.2.4. 面向百万 Token 上下文的 RL 框架扩展
我们针对一百万 token 序列的高效 RL 与 OPD 引入了定向优化。在 rollout 阶段,我们采用了第 5.2.3 节详细描述的可抢占且容错的 rollout 服务。对于推理与训练阶段,我们把 rollout data format 分解为轻量级 metadata 和重型的逐 token 字段。在数据分发期间,可以加载整份 rollout 数据的 metadata,以执行全局打乱与打包布局计算。重型逐 token 字段则通过共享内存数据加载器进行加载,以消除节点内数据冗余,并在以 mini-batch 为粒度消费后立即释放,从而显著降低 CPU 与 GPU 内存压力。设备上保留的 mini-batches 数量会依据工作负载动态确定,以在计算吞吐与 I/O 重叠之间取得高效权衡。
5.2.5. 面向 Agentic AI 的 Sandbox 基础设施
为了满足 agentic AI 在后训练与评测期间多样化的执行需求,我们构建了生产级 sandbox 平台 DeepSeek Elastic Compute(DSec)。DSec 由三个 Rust 组件组成——API gateway(Apiserver)、每主机 agent(Edge)以及 cluster monitor(Watcher)——它们通过自定义 RPC 协议互连,并构建在 3FS 分布式文件系统(DeepSeek-AI, 2025)之上,可进行横向扩展。在生产中,单个 DSec 集群可以管理数十万个并发 sandbox 实例。
DSec 的设计动机来自四点观察:(1)agentic 工作负载高度异质,从轻量函数调用到完整的软件工程流水线都涵盖其中,并具有多样的 OS 与安全需求;(2)环境镜像数量多、体积大,但必须快速加载并支持迭代式定制;(3)高密度部署要求高效利用 CPU 与内存;(4)sandbox 生命周期必须与 GPU 训练调度协同,包括抢占与基于 checkpoint 的恢复。基于这些观察,我们在下文分别介绍 DSec 的四项核心设计。
单一统一接口背后的四种执行基底
DSec 暴露单一 Python SDK(libdsec),抽象出四种执行基底。Function Call 会将无状态调用分发到预热容器池,从而消除冷启动开销。Container 完全兼容 Docker,并利用 EROFS(Gao et al., 2019)按需加载,实现高效镜像组装。microVM 基于 Firecracker(Agache et al., 2020)构建,为对安全敏感、需要高密度部署的场景提供 VM 级隔离。fullVM 基于 QEMU(Bellard, 2005)构建,支持任意 guest operating systems。四者共享统一的 API 表面——命令执行、文件传输与 TTY 访问——切换执行基底只需更改一个参数。
分层存储带来的快速镜像加载
DSec 通过分层、按需加载的方式,在快速启动和不断增长的大量环境镜像之间取得平衡。对于 containers,基础镜像与文件系统 commits 被存储为基于 3FS 的只读 EROFS 层,并直接挂载到 overlay 的 lowerdirs 中。挂载时,我们会将文件元数据保留在本地磁盘上;与此同时,数据块则在请求发生时从 3FS 拉取。对于 microVMs,DSec 使用 overlaybd(Li et al., 2020)磁盘格式:只读基础层驻留于 3FS,以支持跨实例共享;写入则进入本地 copy-on-write 层。这类快照可以形成链式结构,从而支持高效版本管理与毫秒级恢复。
海量并发下的密度优化
为了让每个集群承载数十万个 sandboxes,DSec 重点解决两个资源瓶颈。第一,它减少虚拟化环境中的重复 page-cache 占用,并应用 memory reclamation,以支持安全的 overcommitment。第二,它缓解 container runtime 中的 spinlock contention,从而降低每个 sandbox 的 CPU 开销,并显著提升单机打包密度。
Trajectory Logging 与安全的抢占恢复
DSec 为每个 sandbox 维护全局有序的 trajectory log,持久记录每一条命令调用及其结果。这个 trajectory 有三个用途:(1)客户端 fast-forwarding——当训练任务被抢占时,sandbox 资源仍然保留;恢复后,DSec 会为此前已完成的命令回放缓存结果,从而加速任务恢复,同时避免对非幂等操作重复执行而导致错误;(2)细粒度来源追踪——每一次状态变化的来源及其对应结果都可以追溯;(3)deterministic replay——任何历史会话都可以通过其 trajectory 被忠实复现。
5.3. 标准基准评测
5.3.1. 评测设定
知识与推理
知识与推理数据集包括 MMLU-Pro(Wang et al., 2024b)、GPQA(Rein et al., 2023)、Human Last Exam(Phan et al., 2025)、Simple-QA Verified(Haas et al., 2025)、Chinese-SimpleQA(He et al., 2024)、LiveCodeBench-v6(Jain et al., 2024)、CodeForces(内部基准)、HMMT 2026 Feb、Apex(Balunović et al., 2025)、Apex Shortlist(Balunović et al., 2025)、IMOAnswerBench(Luong et al., 2025)以及 PutnamBench(Tsoukalas et al., 2024)。
对于代码,我们在 LiveCodeBench-v6 和一个内部 Codeforces 基准上评测 DeepSeek-V4 系列。对于 Codeforces,我们收集了 14 场 Codeforces Division 1 比赛,共 114 道题(2025 年 5 月至 2025 年 11 月)。Elo rating 的计算方式如下。对于每场比赛,我们为每道题生成 32 个候选解。对于每道题,我们独立地从这 32 个解中不放回抽样 10 个,并按随机顺序排列,构成提交序列。每次提交都由领域专家构建的测试集进行判定。已解决题目的得分采用 OpenAI(2025)的罚时方案:模型获得的分数,等于在相同题目上以相同失败次数解出的真人选手得分中位数。这样可得到每个抽样提交序列对应的总比赛分数,再进一步转换为比赛排名,随后按标准 Codeforces 评分系统换算为估计 rating。比赛级期望 rating 定义为:在每题 10 次提交的所有可能随机抽样和排列上,对该估计 rating 取期望。模型的总体 rating 是这 14 场比赛中各场比赛级期望 rating 的平均值。
对于推理与知识任务,我们将 temperature 设为 1.0,并将 Non-think、High 与 Max 模式的上下文窗口分别设为 8K、128K 与 384K token。对于数学任务(例如 HMMT、IMOAnswerBench、Apex 与 HLE),我们使用如下模板进行评测:
{question}
Please reason step by step, and put your final answer within \boxed{}.
对于数学任务上的 DeepSeek-V4-Pro-Max,我们使用如下模板以诱导更深推理:
Solve the following problem. The problem may ask you to
prove a statement, or ask for an answer. If finding an answer is required,
you should come up with the answer, and your final solution should also be
a rigorous proof of that answer being valid.
{question}
对于形式化数学任务,我们在 agentic 设置中于 Lean v4.28.0-rc1(Moura and Ullrich, 2021)上进行评测,允许访问 Lean compiler 与 semantic tactic search engine,在最大推理努力下最多运行 500 次工具调用。此外,我们还评测了一个更高算力开销的流水线:先生成候选自然语言解答,并通过 self-verification(Shao et al., 2025)进行筛选,再把保留下来的解答作为指导提供给 formal agent,以证明相应 Lean 命题。该设计利用非形式化推理来改善探索,同时通过形式验证保持严格正确性。只有当严格 verifier Comparator 在两种设置下都接受某份提交时,该提交才被计为正确。
由于 K2.6 与 GLM-5.1 的 API 太繁忙,无法对我们的查询返回响应,我们在其部分条目中留空。
一百万 Token 上下文
由于 DeepSeek-V4 系列支持 1M-token 上下文,我们通过选择 OpenAI MRCR(OpenAI, 2024b)与 CorpusQA(Lu et al., 2026)作为基准,评测模型在长上下文场景下的表现。为了在所有模型之间标准化配置,我们重新评测了 Claude Opus 4.6 与 Gemini 3.1 Pro 在这些任务上的表现。我们没有评测 GPT-5.4,因为其 API 对我们的大量查询都未返回响应。
Agent
Agent 数据集包括 Terminal Bench 2.0(Merrill et al., 2026)、SWE-Verified(OpenAI, 2024e)、SWE Multilingual(Yang et al., 2025)、SWE-Pro(Deng et al., 2025)、BrowseComp(Wei et al., 2025)、MCPAtlas 的公开评测集(Bandi et al., 2026)、GDPval-AA(AA, 2025;Patwardhan et al., 2025)以及 Tool-Decathlon(Li et al., 2025)。
对于代码 agent 任务(SWE-Verified、Terminal-Bench、SWE-Pro、SWE Multilingual),我们使用内部开发的评测框架来评测 DeepSeek-V4 系列。该框架提供一组最小工具——bash 工具与文件编辑工具。最大交互步数设为 500,最大上下文长度设为 512K token。关于 Terminal-Bench 2.0,我们承认 GLM-5.1 所指出的环境相关问题。尽管如此,为了保持一致性,我们仍在原始 Terminal-Bench 2.0 数据集上报告性能。在 Terminal-Bench 2.0 Verified 子集上,DeepSeek-V4-Pro 的得分约为 72.0。
对于搜索 agent 任务(BrowseComp、HLE w/ tool),我们同样使用内部 harness,提供 websearch 与 Python 工具,并将最大交互步数设为 500、最大上下文长度设为 512K token。对于 BrowseComp,我们采用与 DeepSeek-V3.2(DeepSeek-AI, 2025)相同的 discard-all 上下文管理策略。
5.3.2. 评测结果
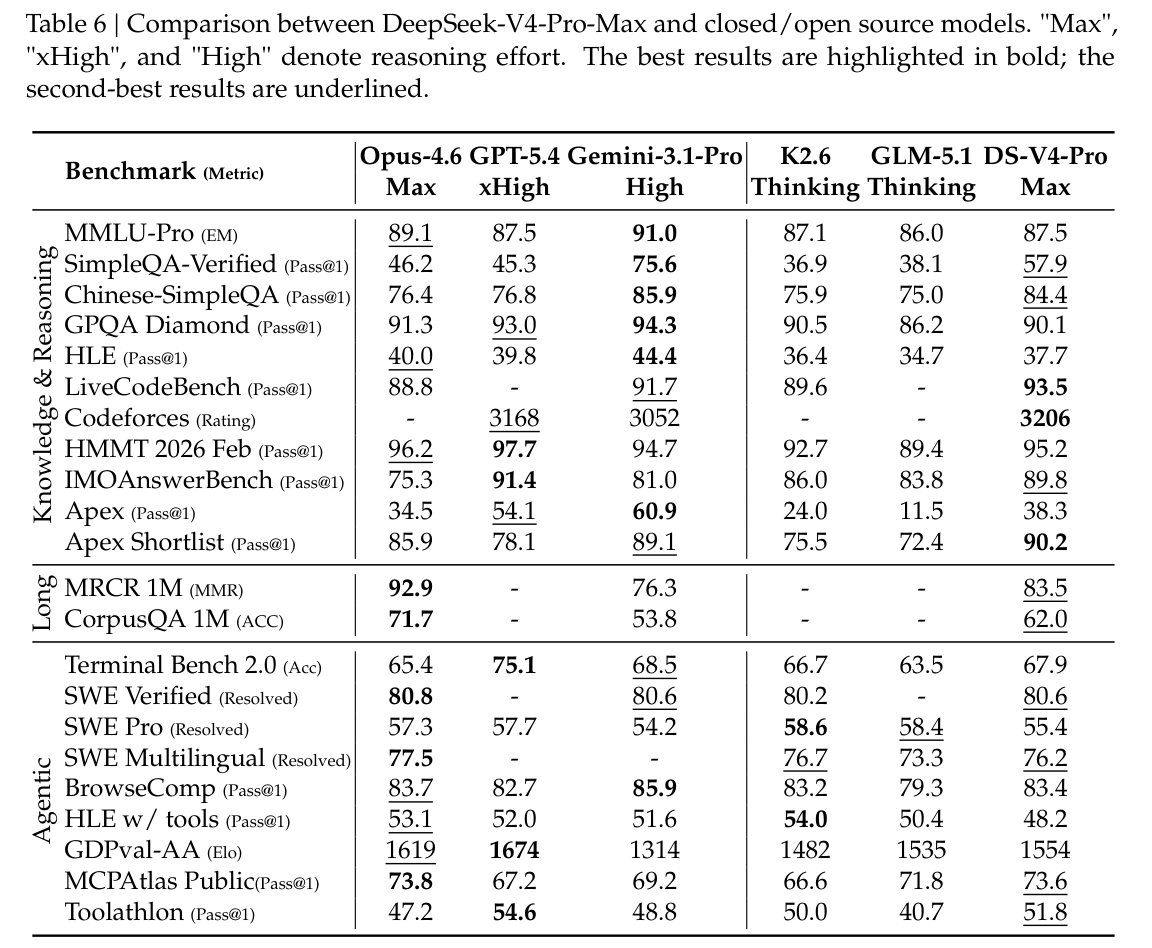
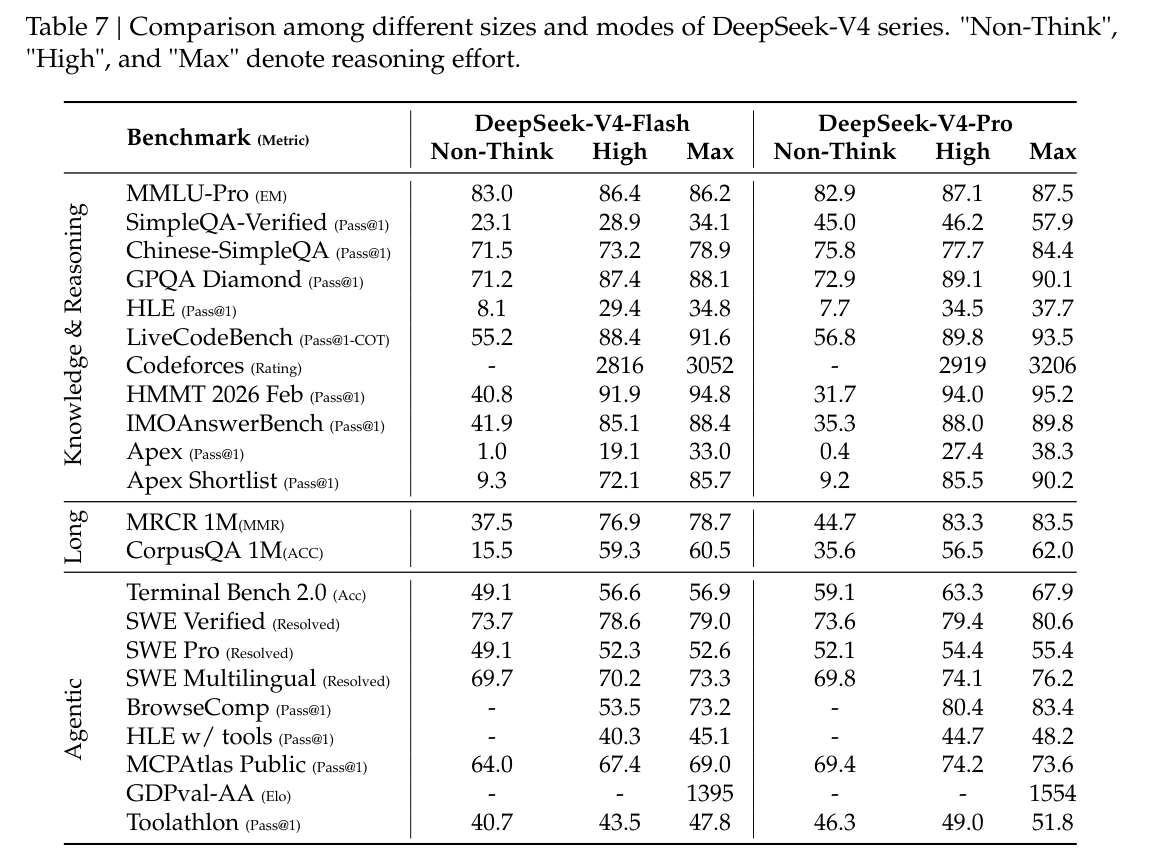
表 6 展示了 DeepSeek-V4-Pro-Max 与其他闭源/开源模型的对比。此外,我们还评测了 DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 的不同模式,并在表 7 中展示结果。
知识
在通用世界知识评测中,DeepSeek-V4-Pro-Max——即 DeepSeek-V4-Pro 的最大推理努力模式——在开源大语言模型中建立了新的 state-of-the-art。正如 SimpleQA-Verified 所示,DeepSeek-V4-Pro-Max 以 20 个绝对百分点的优势显著超过所有现有开源基线。尽管如此,它目前仍落后于领先的专有模型 Gemini-3.1-Pro。在教育知识与推理领域,DeepSeek-V4-Pro-Max 在 MMLU-Pro、GPQA 和 HLE 基准上略微超过 Kimi 与 GLM,尽管仍落后于领先的专有模型。总体而言,DeepSeek-V4-Pro-Max 标志着开源模型世界知识能力提升过程中的一个重要里程碑。
此外,DeepSeek-V4-Flash 与 DeepSeek-V4-Pro 在知识类任务上存在显著性能差距;这是预期之中的,因为更大的参数规模有助于在预训练中保留更多知识。值得注意的是,这两个模型在获得更高推理努力时,在知识基准上都表现出更好的结果。
推理
DeepSeek-V4-Pro-Max 在各项推理基准上超过所有先前开放模型,并且在许多指标上达到了 state-of-the-art 级别的闭源模型水平;与此同时,更小的 DeepSeek-V4-Flash-Max 也在代码与数学推理任务上超过了此前最强的开源模型 K2.6-Thinking。此外,DeepSeek-V4-Pro 与 DeepSeek-V4-Flash 在编程竞赛中表现出色。根据我们的评测,它们的表现可与 GPT-5.4 相比,这使其成为首个在该任务上追平闭源模型的开放模型。在 Codeforces 排行榜上,DeepSeek-V4-Pro-Max 目前位列所有人类参赛者中的第 23 名。DeepSeek-V4 还在形式化数学任务上,在 agentic 与高算力两种设置下都表现出强劲能力。在 agentic 设置下,它达到了 state-of-the-art 水平,如图 8 所示,超过了 Seed Prover(Chen et al., 2025)等先前模型。在更高算力的流水线下,性能进一步提升,超过 Aristotle(Achim et al., 2025)等系统,并在该设置下达到已知最佳结果水平。

Agent
DeepSeek-V4 系列在 agent 评测中表现强劲。对于代码 agent 任务,DeepSeek-V4-Pro 的结果可与 K2.6 和 GLM-5.1 相比,不过这些开源模型整体上仍落后于闭源对应模型。DeepSeek-V4-Flash 在代码任务上的表现不如 DeepSeek-V4-Pro,尤其是在 Terminal Bench 2.0 上。类似趋势也出现在其他 agent 评测中。值得注意的是,DeepSeek-V4-Pro 在 MCPAtlas 与 Toolathlon——这两个包含广泛工具与 MCP 服务的评测集——上表现良好,这说明我们的模型具有优秀的泛化能力,而不是仅仅在内部框架上表现较好。
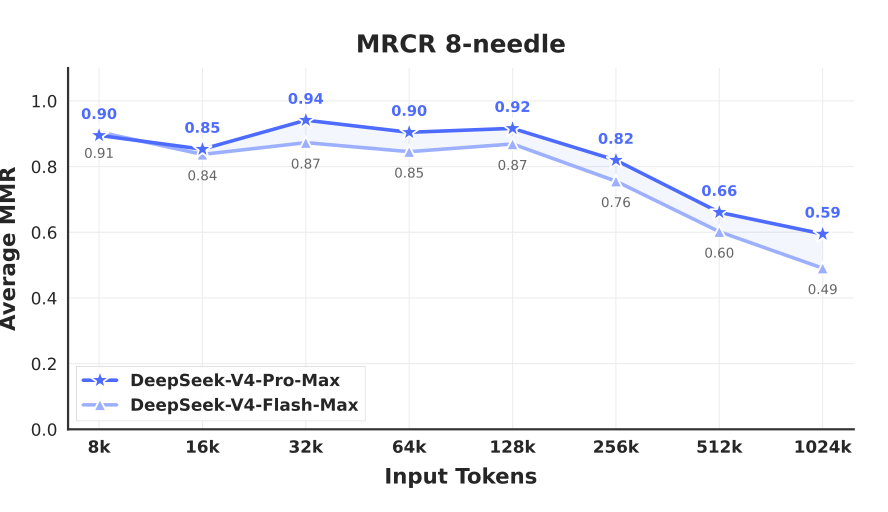
一百万 Token 上下文
DeepSeek-V4-Pro 在衡量上下文内检索能力的 MRCR 任务上优于 Gemini-3.1-Pro,但仍落后于 Claude Opus 4.6。如图 9 所示,在 128K 上下文窗口内,检索性能保持得非常稳定。虽然超过 128K 之后性能开始出现下降,但在 1M token 下,模型的检索能力相较于专有与开源对应模型仍然相当强。不同于 MRCR,CorpusQA 更接近真实场景。评测结果也表明,DeepSeek-V4-Pro 优于 Gemini-3.1-Pro。
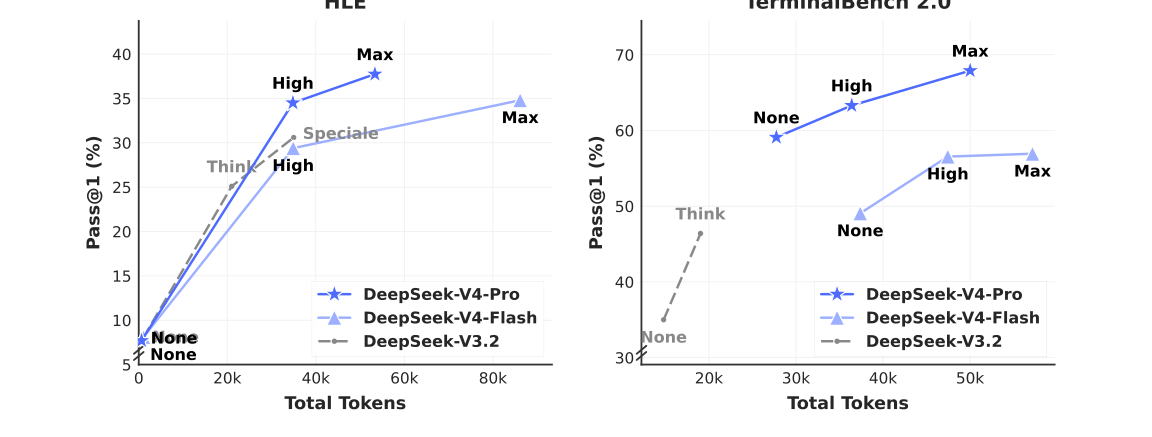
推理努力
如表 7 所示,Max 模式在 RL 中采用更长上下文和更低长度惩罚,因此在最具挑战性的任务上优于 High 模式。图 10 比较了 DeepSeek-V4-Pro、DeepSeek-V4-Flash 和 DeepSeek-V3.2 在代表性推理与 agentic 任务上的性能与成本。通过扩展 test-time compute,DeepSeek-V4 系列相较前代模型获得了显著提升。此外,在 HLE 这类推理任务上,DeepSeek-V4-Pro 展现出比 DeepSeek-V3.2 更高的 token 效率。
5.4. 真实世界任务上的表现
标准化基准往往难以捕捉多样化真实任务的复杂性,从而在测试结果与真实用户体验之间形成鸿沟。为弥补这一点,我们开发了内部专有指标,将真实使用模式置于传统基准之上优先考虑。这种做法确保我们的优化能够转化为切实收益。我们的评测框架专门面向 DeepSeek API 与 Chatbot 的主要使用场景,以便让模型表现更贴合实际需求。
5.4.1. 中文写作
DeepSeek 的一个主要使用场景是中文写作。我们对功能性写作与创意写作进行了严格评测。表 12 展示了 DeepSeek-V4-Pro 与 Gemini-3.1-Pro 在功能性写作任务上的两两比较。这些任务由常见日常写作查询组成,其 prompts 通常简短直接。我们选择 Gemini-3.1-Pro 作为基线,因为它在我们的中文写作评测中是表现最好的外部模型。结果表明,DeepSeek-V4-Pro 以 62.7% 对 34.1% 的总体胜率超过该基线;其主要原因在于,Gemini 在中文写作场景中有时会让自身风格偏好压过用户的明确要求。
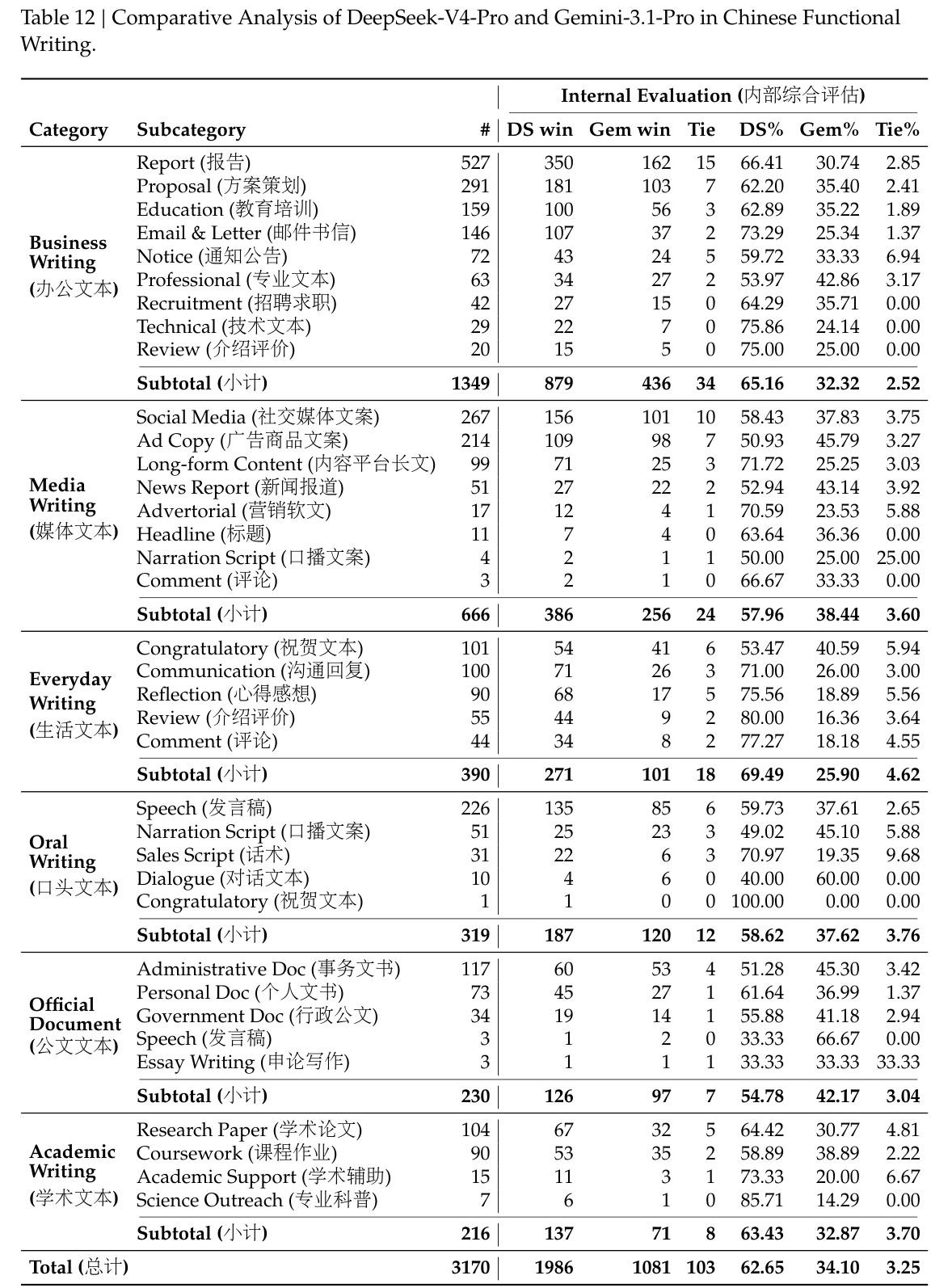
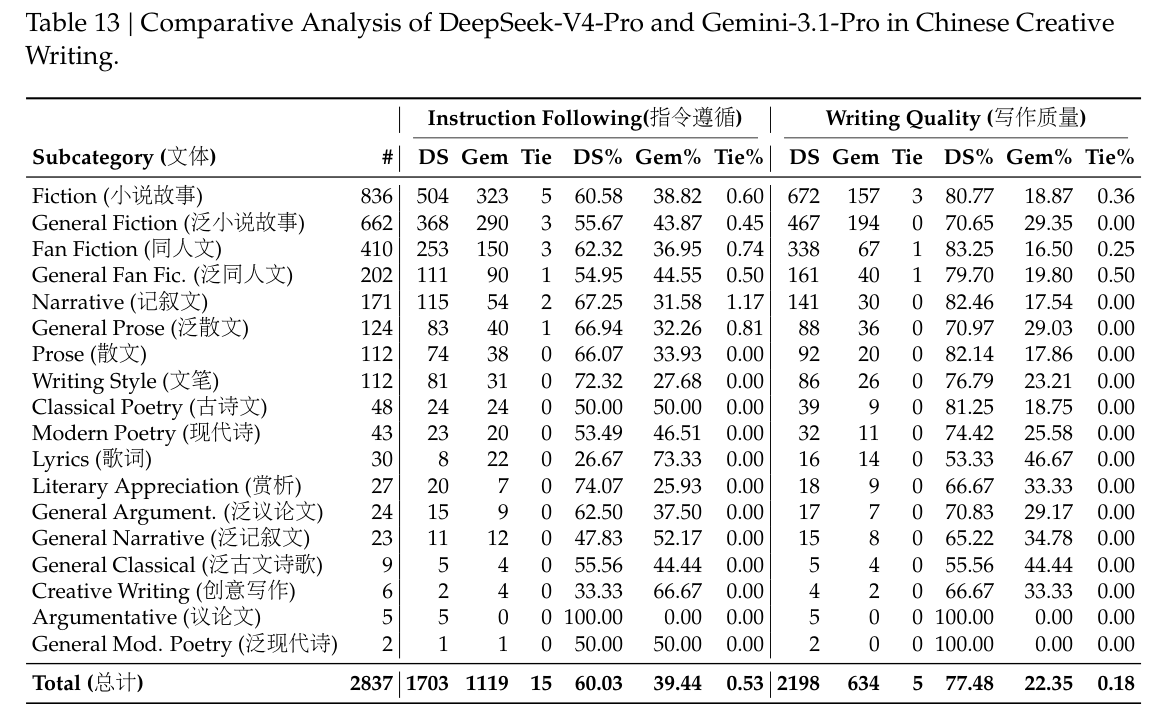
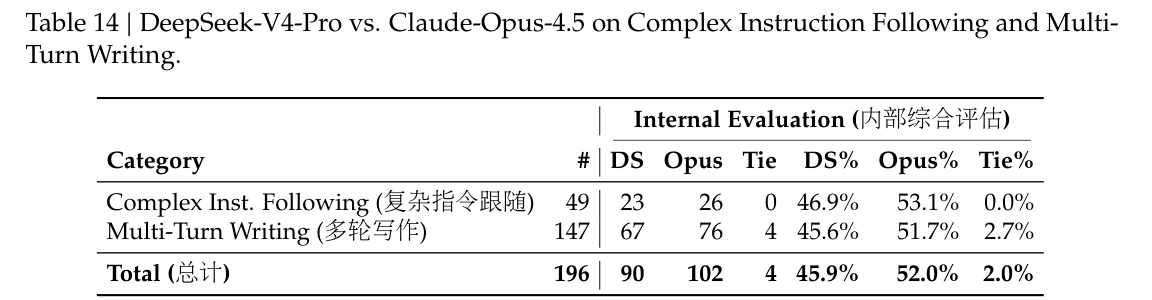
表 13 展示了创意写作的比较结果,该评测沿两个轴线进行:instruction following 与 writing quality。与 Gemini-3.1-Pro 相比,DeepSeek-V4-Pro 在 instruction following 上的胜率达到 60.0%,在 writing quality 上达到 77.5%,这表明其在 instruction following 上略有提升,而在 writing quality 上获得了显著提升。尽管在总体用户案例分析中,DeepSeek-V4-Pro 给出了更优结果,但若只评测最具挑战性的 prompts——特别是那些包含高复杂度约束或多轮场景的 prompts——则 Claude Opus 4.5 仍相较 DeepSeek-V4-Pro 保持性能优势。如表 14 所示,Claude Opus 4.5 的胜率为 52.0%,而 DeepSeek-V4-Pro 为 45.9%。
5.4.2. 搜索
搜索增强问答是 DeepSeek chatbot 的一项核心能力。在 DeepSeek web 与 app 上,“non-think” 模式使用 Retrieval-Augmented Search(RAG),而 “thinking” 模式使用 agentic search。
Retrieval Augmented Search
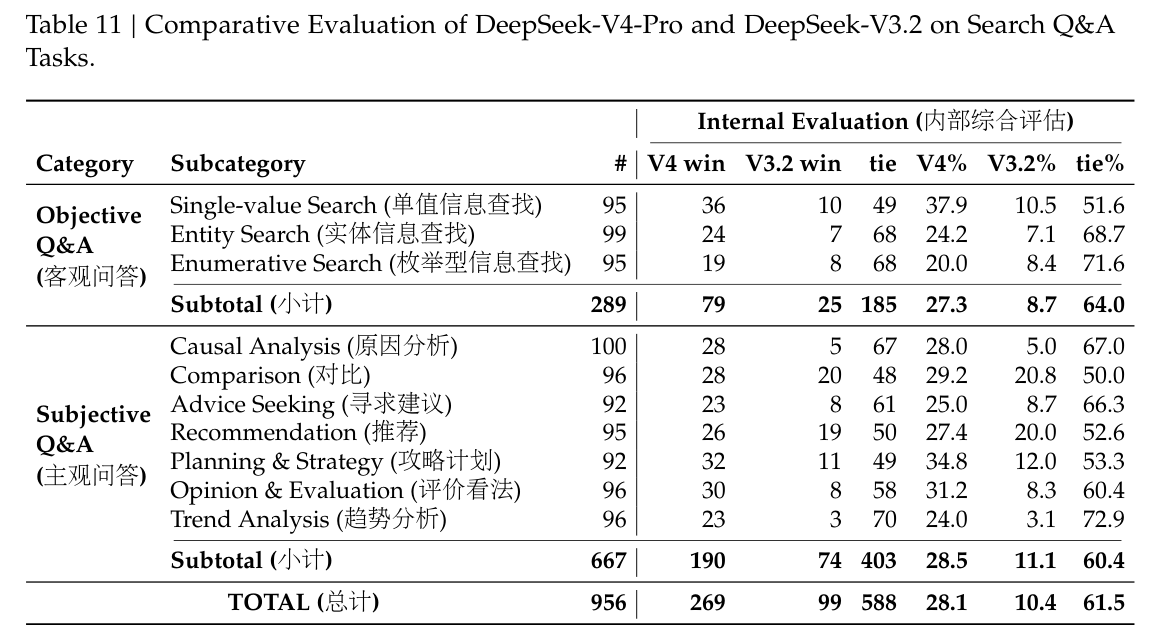
我们对 DeepSeek-V4-Pro 与 DeepSeek-V3.2 在客观和主观两类问答场景上做了两两比较评测。如表 11 所示,DeepSeek-V4-Pro 以显著优势超过 DeepSeek-V3.2,并在两类场景中都持续领先。其中最明显的提升出现在单值搜索和攻略/计划任务上,这表明 DeepSeek-V4-Pro 特别擅长从检索上下文中定位精确事实答案并综合生成结构化规划。不过,在 comparison 和 recommendation 任务上,DeepSeek-V3.2 仍保持相对竞争力,这说明在需要对搜索结果进行平衡、多视角推理的场景中,DeepSeek-V4-Pro 仍有改进空间。
Agentic Search
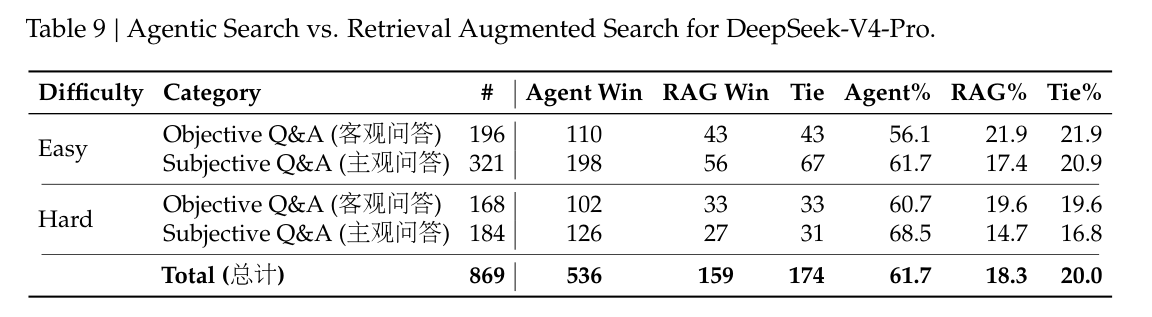
不同于标准 RAG,agentic search 允许模型针对每个查询迭代调用 search 与 fetch 工具,从而显著提升整体搜索表现。对于 DeepSeek-Chat 的 thinking 模式,我们优化了 agentic search 功能,以在预定义的 “thinking budget” 内最大化响应准确率。如表 9 所示,agentic search 始终优于 RAG,尤其是在复杂任务上。进一步地,它的成本仍然非常高效,agentic search 相比标准 RAG 只略微更昂贵(见表 10)。

5.4.3. 白领任务
为了严格评测模型在复杂企业生产力场景中的实用性,我们构建了一套包含 30 个高级中文专业任务的完整任务集。这些工作流有意覆盖高层次认知需求,包括深入信息分析、完整文档生成和细致文档编辑,并横跨 13 个关键行业(例如金融、教育、法律和科技)。评测是在一个内部 agent harness 中进行的,配备了 Bash 和 web search 等基础工具。
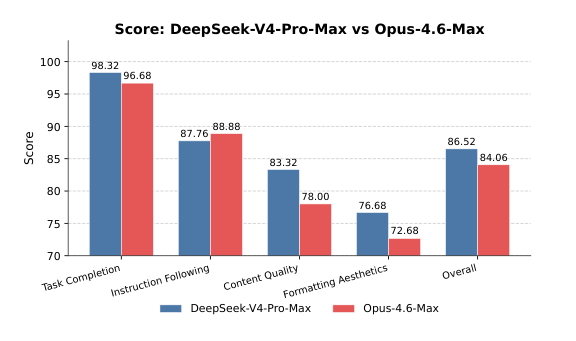
由于这些任务具有开放性,自动化指标通常难以捕捉高质量响应的细微差异。因此,我们进行了人工评测,以比较 DeepSeek-V4-Pro-Max 与 Opus-4.6-Max 的表现。标注者在不知道模型来源的情况下,从四个维度对模型输出进行评估:
- 任务完成度:核心问题是否被成功解决。
- 指令遵循:是否遵守特定约束与指令。
- 内容质量:事实准确性、逻辑连贯性与专业语气。
- 格式美观:版式可读性与视觉呈现。
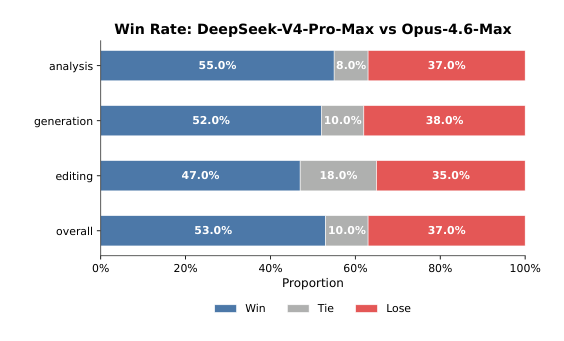
如图 11 所示,DeepSeek-V4-Pro-Max 在多样中文白领任务上超过 Opus-4.6-Max,取得了令人印象深刻的 63% non-loss rate,并在分析、生成和编辑任务上都体现出持续优势。图 12 给出的详细维度得分显示,该模型的主要优势在于任务完成度与内容质量。具体来说,DeepSeek-V4-Pro-Max 经常会主动预判用户的隐含意图,频繁提供补充洞见和自我校验步骤。它也擅长长文本生成,能够给出深入且连贯的叙述,而不是依赖 Opus-4.6-Max 经常给出的过于简单的项目符号列表。此外,该模型严格遵守正式专业规范,例如标准中文层级编号。不过,在指令遵循方面,它偶尔会忽略特定格式限制,略逊于 Opus。进一步地,该模型在把大段输入压缩成简洁摘要方面也相对较弱。最后,在 presentation slides 的整体视觉设计上,其格式美观仍有较大提升空间。图 13、14 和 15 展示了若干测试案例;由于部分输出非常长,因此只展示部分页面。


5.4.4. 代码 Agent
为了评测我们的代码 agent 能力,我们从真实内部研发工作负载中整理任务。我们从 50 多位内部工程师处收集了约 200 个具有挑战性的任务,涵盖特性开发、bug 修复、重构与诊断,并覆盖 PyTorch、CUDA、Rust 和 C++ 等多种技术栈。每个任务都附带其原始仓库、对应执行环境以及人工标注评分标准;经过严格质量筛选后,保留其中 30 个任务作为评测集。如表 8 所示,DeepSeek-V4-Pro 显著超过 Claude Sonnet 4.5,并接近 Claude Opus 4.5 的水平。

在一项面向 DeepSeek 开发者与研究人员(N = 85)的调查中——他们都具有在日常工作中使用 DeepSeek-V4-Pro 进行 agentic coding 的经验——我们询问他们:与其他前沿模型相比,DeepSeek-V4-Pro 是否已经可以作为默认和首选代码模型。52% 的受访者回答“是”,39% 倾向于“是”,不到 9% 回答“否”。受访者认为,DeepSeek-V4-Pro 在大多数任务上都能给出令人满意的结果,但也指出其仍会出现一些琐碎错误、对模糊 prompts 的误解,以及偶发的过度思考。
6. 结论、局限性与未来方向
在这项工作中,我们提出了 DeepSeek-V4 系列的预览版本,目标是打造能够打破超长上下文处理效率壁垒的下一代大语言模型。通过结合融合 CSA 与 HCA 的混合注意力架构,DeepSeek-V4 系列在长序列效率上实现了显著飞跃。这些架构创新,再加上广泛的基础设施优化,使得对百万 token 上下文的高效原生支持成为可能,并为未来的 test-time scaling、长时程任务以及在线学习等新兴范式奠定了必要基础。评测结果表明,DeepSeek-V4-Pro-Max——即 DeepSeek-V4-Pro 的最大推理努力模式——为开放模型重新定义了 state-of-the-art。它在知识基准上显著超过先前开源模型,在推理性能上接近最前沿的专有模型,并提供具有竞争力的 agent 能力。与此同时,DeepSeek-V4-Flash-Max 在保持高度成本高效架构的同时,取得了与领先闭源模型可比的推理表现。我们相信,DeepSeek-V4 系列为开放模型开启了百万长度上下文的新纪元,并为更好的效率、规模与智能铺平了道路。
为了追求极致长上下文效率,DeepSeek-V4 系列采用了大胆的架构设计。为了最小化风险,我们保留了许多已经初步验证的组件与技巧;这些设计虽然有效,但也使架构相对复杂。在未来迭代中,我们将进行更全面、更具原则性的研究,以把架构提炼为最核心的设计,在不牺牲性能的前提下使其更加优雅。与此同时,虽然 Anticipatory Routing 与 SwiGLU Clamping 已被证明能有效缓解训练不稳定性,但其底层原理仍然缺乏充分理解。我们将积极研究训练稳定性的基础问题,并强化内部指标监控,以实现一种更具原则性、预测性更强的大规模稳定训练方法。
此外,除 MoE 和 sparse attention 架构之外,我们也将主动探索新的模型稀疏维度——例如更稀疏的 embedding 模块(Cheng et al., 2026)——以在不损害能力的前提下进一步提高计算和内存效率。我们还将持续研究低时延架构与系统技术,使长上下文部署与交互拥有更快响应。进一步地,我们认识到长时程、多轮 agentic 任务的重要性与实际价值,并将继续在这一方向上迭代与探索。我们也在努力为模型引入 multimodal capabilities。最后,我们致力于开发更好的数据整理与合成策略,以在越来越广泛的场景与任务中持续提升模型智能、鲁棒性与实际可用性。
References(参考文献)
AA. Gdpval-aa leaderboard, 2025. URL https://artificialanalysis.ai/methodolog y/intelligence-benchmarking#gdpval-aa.
T. Achim, A. Best, A. Bietti, K. Der, M. Fédérico, S. Gukov, D. Halpern-Leistner, K. Henningsgard, Y. Kudryashov, A. Meiburg, et al. Aristotle: Imo-level automated theorem proving. arXiv preprint arXiv:2510.01346, 2025.
A. Agache, M. Brooker, A. Florescu, A. Iordache, A. Liguori, R. Neugebauer, P. Piwonka, and D.-M. Popa. Firecracker: lightweight virtualization for serverless applications. In Proceedings of the 17th Usenix Conference on Networked Systems Design and Implementation, NSDI’20, page 419–434, USA, 2020. USENIX Association. ISBN 9781939133137.
O. J. Aimuyo, B. Oh, and R. Singh. Flashmoe: Fast distributed moe in a single kernel. Advances in Neural Information Processing Systems, 2025. URL https://neurips.cc/virtual/2 025/poster/119124.
J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023.
J. Asher. LeanExplore: A search engine for Lean 4 declarations, 2025. URL https://arxiv.org/abs/2506.11085.
Y. Bai, Y. Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y. Chen, Y. Chen, Y. Chen, Z. Chen, J. Cui, H. Ding, M. Dong, A. Du, C. Du, D. Du, Y. Du, Y. Fan, Y. Feng, K. Fu, B. Gao, H. Gao, P. Gao, T. Gao, X. Gu, L. Guan, H. Guo, J. Guo, H. Hu, X. Hao, T. He, W. He, W. He, C. Hong, Y. Hu, Z. Hu, W. Huang, Z. Huang, Z. Huang, T. Jiang, Z. Jiang, X. Jin, Y. Kang, G. Lai, C. Li, F. Li, H. Li, M. Li, W. Li, Y. Li, Y. Li, Z. Li, Z. Li, H. Lin, X. Lin, Z. Lin, C. Liu, C. Liu, H. Liu, J. Liu, J. Liu, L. Liu, S. Liu, T. Y. Liu, T. Liu, W. Liu, Y. Liu, Y. Liu, Y. Liu, Y. Liu, Z. Liu, E. Lu, L. Lu, S. Ma, X. Ma, Y. Ma, S. Mao, J. Mei, X. Men, Y. Miao, S. Pan, Y. Peng, R. Qin, B. Qu, Z. Shang, L. Shi, S. Shi, F. Song, J. Su, Z. Su, X. Sun, F. Sung, H. Tang, J. Tao, Q. Teng, C. Wang, D. Wang, F. Wang, and H. Wang. Kimi K2: open agentic intelligence. CoRR, abs/2507.20534, 2025a. URL https://doi.org/10.48550/arXiv.2507.20534.
Y. Bai, S. Tu, J. Zhang, H. Peng, X. Wang, X. Lv, S. Cao, J. Xu, L. Hou, Y. Dong, et al. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3639–3664, 2025b.
M. Balunović, J. Dekoninck, I. Petrov, N. Jovanović, and M. Vechev. Matharena: Evaluating llms on uncontaminated math competitions. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmark, 2025.
C. Bandi, B. Hertzberg, G. Boo, T. Polakam, J. Da, S. Hassaan, M. Sharma, A. Park, E. Hernandez, D. Rambado, et al. Mcp-atlas: A large-scale benchmark for tool-use competency with real mcp servers. arXiv preprint arXiv:2602.00933, 2026.
F. Bellard. Qemu, a fast and portable dynamic translator. In Proceedings of the Annual Conference on USENIX Annual Technical Conference, ATEC ’05, page 41, USA, 2005. USENIX Association.
I. Bello, H. Pham, Q. V. Le, M. Norouzi, and S. Bengio. Neural combinatorial optimization with reinforcement learning, 2017. URL https://openreview.net/forum?id=rJY3vK9eg.
J. Chen, W. Chen, J. Du, J. Hu, Z. Jiang, A. Jie, X. Jin, X. Jin, C. Li, W. Shi, Z. Wang, M. Wang, C. Wei, S. Wei, H. Xin, F. Yang, W. Gao, Z. Yuan, T. Zhan, Z. Zheng, T. Zhou, and T. H. Zhu. Seed-prover 1.5: Mastering undergraduate-level theorem proving via learning from experience, 2025. URL https://arxiv.org/abs/2512.17260.
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba. Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021. URL https://arxiv.org/abs/2107.03374.
T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, H. Shen, M. Cowan, L. Wang, Y. Hu, L. Ceze, C. Guestrin, and A. Krishnamurthy. TVM: An automated End-to-End optimizing com- piler for deep learning. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 578–594, Carlsbad, CA, Oct. 2018. USENIX Association. ISBN 978-1-939133-08-3. URL https://www.usenix.org/conference/osdi18/prese ntation/chen.
A. Cheng, A. Jacovi, A. Globerson, B. Golan, C. Kwong, C. Alberti, C. Tao, E. Ben-David, G. S. Tomar, L. Haas, et al. The facts leaderboard: A comprehensive benchmark for large language model factuality. arXiv preprint arXiv:2512.10791, 2025.
X. Cheng, W. Zeng, D. Dai, Q. Chen, B. Wang, Z. Xie, K. Huang, X. Yu, Z. Hao, Y. Li, H. Zhang, H. Zhang, D. Zhao, and W. Liang. Conditional memory via scalable lookup: A new axis of sparsity for large language models. CoRR, abs/2601.07372, 2026. doi: 10.48550/ARXIV.2601. 07372. URL https://doi.org/10.48550/arXiv.2601.07372.
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
D. Dai, C. Deng, C. Zhao, R. X. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y. Wu, Z. Xie, Y. K. Li, P. Huang, F. Luo, C. Ruan, Z. Sui, and W. Liang. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. CoRR, abs/2401.06066, 2024. URL https://doi.org/10.48550/arXiv.2401.06066.
T. Dao, D. Haziza, F. Massa, and G. Sizov. Flash-decoding for long-context inference, 2023. URL https://pytorch.org/blog/flash-decoding/.
L. De Moura and N. Bjørner. Z3: an efficient smt solver. In Proceedings of the Theory and Practice of Software, 14th International Conference on Tools and Algorithms for the Construction and Analysis of Systems, TACAS’08/ETAPS’08, page 337–340, Berlin, Heidel- berg, 2008. Springer-Verlag. ISBN 3540787992.
DeepSeek-AI. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelli- gence. CoRR, abs/2406.11931, 2024. URL https://doi.org/10.48550/arXiv.2406.11 931.
DeepSeek-AI. Deepseek-v3 technical report. CoRR, abs/2412.19437, 2024. URL https://doi.org/10.48550/arXiv.2412.19437.
DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. CoRR, abs/2405.04434, 2024. URL https://doi.org/10.48550/arXiv.2405.04 434.
DeepSeek-AI. Fire-flyer file system, 2025. URL https://github.com/deepseek-ai/3FS.
DeepSeek-AI. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nat., 645(8081):633–638, 2025. URL https://doi.org/10.1038/s41586-025-09422-z.
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models, 2025. URL https://arxiv.org/abs/2512.02556.
X. Deng, J. Da, E. Pan, Y. Y. He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, K. Sampath, M. Krishnan, S. Kundurthy, S. Hendryx, Z. Wang, V. Bharadwaj, J. Holm, R. Aluri, C. B. C. Zhang, N. Jacobson, B. Liu, and B. Kenstler. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?, 2025. URL https://arxiv.org/abs/2509.16941.
H. Ding, Z. Wang, G. Paolini, V. Kumar, A. Deoras, D. Roth, and S. Soatto. Fewer truncations improve language modeling. arXiv preprint arXiv:2404.10830, 2024.
X. Dong, Y. Fu, S. Diao, W. Byeon, Z. CHEN, A. S. Mahabaleshwarkar, S.-Y. Liu, M. V. keirsbilck, M.-H. Chen, Y. Suhara, Y. C. Lin, J. Kautz, and P. Molchanov. Hymba: A hybrid-head archi- tecture for small language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=A1ztozypga.
X. Du, Y. Yao, K. Ma, B. Wang, T. Zheng, K. Zhu, M. Liu, Y. Liang, X. Jin, Z. Wei, et al. Supergpqa: Scaling llm evaluation across 285 graduate disciplines. arXiv preprint arXiv:2502.14739, 2025.
D. Dua, Y. Wang, P. Dasigi, G. Stanovsky, S. Singh, and M. Gardner. DROP: A reading compre- hension benchmark requiring discrete reasoning over paragraphs. In J. Burstein, C. Doran, and T. Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pages 2368– 2378. Association for Computational Linguistics, 2019. doi: 10.18653/V1/N19-1246. URL https://doi.org/10.18653/v1/n19-1246.
X. Gao, M. Dong, X. Miao, W. Du, C. Yu, and H. Chen. Erofs: a compression-friendly readonly file system for resource-scarce devices. In Proceedings of the 2019 USENIX Conference on Usenix Annual Technical Conference, USENIX ATC ’19, page 149–162, USA, 2019. USENIX Association. ISBN 9781939133038.
A. P. Gema, J. O. J. Leang, G. Hong, A. Devoto, A. C. M. Mancino, R. Saxena, X. He, Y. Zhao, X. Du, M. R. G. Madani, C. Barale, R. McHardy, J. Harris, J. Kaddour, E. van Krieken, and P. Minervini. Are we done with mmlu? CoRR, abs/2406.04127, 2024. URL https://doi.or g/10.48550/arXiv.2406.04127.
F. Gloeckle, B. Y. Idrissi, B. Rozière, D. Lopez-Paz, and G. Synnaeve. Better & faster large language models via multi-token prediction. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=pEWAcejiU2.
L. Haas, G. Yona, G. D’Antonio, S. Goldshtein, and D. Das. Simpleqa verified: A reliable factuality benchmark to measure parametric knowledge. arXiv preprint arXiv:2509.07968, 2025.
Y. He, S. Li, J. Liu, Y. Tan, W. Wang, H. Huang, X. Bu, H. Guo, C. Hu, B. Zheng, et al. Chi- nese simpleqa: A chinese factuality evaluation for large language models. arXiv preprint arXiv:2411.07140, 2024.
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Mea- suring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
Y. Huang, Y. Bai, Z. Zhu, J. Zhang, J. Zhang, T. Su, J. Liu, C. Lv, Y. Zhang, J. Lei, et al. C-Eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
D. Hupkes and N. Bogoychev. Multiloko: a multilingual local knowledge benchmark for llms spanning 31 languages. CoRR, abs/2504.10356, 2025. doi: 10.48550/ARXIV.2504.10356. URL https://doi.org/10.48550/arXiv.2504.10356.
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024.
K. Jordan, Y. Jin, V. Boza, J. You, F. Cesista, L. Newhouse, and J. Bernstein. Muon: An optimizer for hidden layers in neural networks. Cited on, page 10, 2024.
M. Joshi, E. Choi, D. Weld, and L. Zettlemoyer. TriviaQA: A large scale distantly supervised chal- lenge dataset for reading comprehension. In R. Barzilay and M.-Y. Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17-1147. URL https://aclanthology.org/P17-1147.
H. Li, Y. Yuan, R. Du, K. Ma, L. Liu, and W. Hsu. DADI: Block-Level image service for agile and elastic application deployment. In 2020 USENIX Annual Technical Conference (USENIX ATC 20), pages 727–740. USENIX Association, July 2020. ISBN 978-1-939133-14-4. URL https://www.usenix.org/conference/atc20/presentation/li-huiba.
H. Li, Y. Zhang, F. Koto, Y. Yang, H. Zhao, Y. Gong, N. Duan, and T. Baldwin. CMMLU: Measur- ing massive multitask language understanding in Chinese. arXiv preprint arXiv:2306.09212, 2023.
J. Li, W. Zhao, J. Zhao, W. Zeng, H. Wu, X. Wang, R. Ge, Y. Cao, Y. Huang, W. Liu, et al. The tool decathlon: Benchmarking language agents for diverse, realistic, and long-horizon task execution. arXiv preprint arXiv:2510.25726, 2025.
Y. Li, F. Wei, C. Zhang, and H. Zhang. EAGLE: speculative sampling requires rethinking feature uncertainty. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=1NdN7eXyb4.
J. Liu, J. Su, X. Yao, Z. Jiang, G. Lai, Y. Du, Y. Qin, W. Xu, E. Lu, J. Yan, Y. Chen, H. Zheng, Y. Liu, S. Liu, B. Yin, W. He, H. Zhu, Y. Wang, J. Wang, M. Dong, Z. Zhang, Y. Kang, H. Zhang, X. Xu, Y. Zhang, Y. Wu, X. Zhou, and Z. Yang. Muon is scalable for LLM training. CoRR, abs/2502.16982, 2025. URL https://doi.org/10.48550/arXiv.2502.16982.
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
K. Lu and T. M. Lab. On-policy distillation. Thinking Machines Lab: Connectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation.
Z. Lu, C. Li, Y. Shi, W. Shen, M. Yan, and F. Huang. Corpusqa: A 10 million token benchmark for corpus-level analysis and reasoning. arXiv preprint arXiv:2601.14952, 2026.
T. Luong, D. Hwang, H. H. Nguyen, G. Ghiasi, Y. Chervonyi, I. Seo, J. Kim, G. Bingham, J. Lee, S. Mishra, A. Zhai, C. H. Hu, H. Michalewski, J. Kim, J. Ahn, J. Bae, X. Song, T. H. Trinh, Q. V. Le, and J. Jung. Towards robust mathematical reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025. URL https://aclanthology.org/2025.emnlp-main.1794/.
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y. Shin, T. Walshe, E. K. Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces. arXiv preprint arXiv:2601.11868, 2026.
MiniMax. Meet minimax-m2, 2025. URL https://github.com/MiniMax-AI/MiniMax-M2.
L. d. Moura and S. Ullrich. The lean 4 theorem prover and programming language. In International Conference on Automated Deduction, pages 625–635. Springer, 2021.
Y. Nesterov. A method of solving a convex programming problem with convergence rate 𝑂 (1/𝑘2 ). Soviet Mathematics Doklady, 27:372–376, 1983.
NVIDIA Corporation. cublas documentation, 2024. URL https://docs.nvidia.com/cuda/cublas/. Version 12.4. Accessed: 2024-09-16.
OpenAI. Multilingual massive multitask language understanding (mmmlu), 2024a. URL https://huggingface.co/datasets/openai/MMMLU.
OpenAI. Openai mrcr: Long context multiple needle in a haystack benchmark, 2024b. URL https://huggingface.co/datasets/openai/mrcr.
OpenAI. Learning to reason with llms, 2024c. URL https://openai.com/index/learning-to-reason-with-llms.
OpenAI. Introducing SimpleQA, 2024d. URL https://openai.com/index/introducing-simpleqa/.
OpenAI. Introducing SWE-bench verified we’re releasing a human-validated subset of swe- bench that more, 2024e. URL https://openai.com/index/introducing-swe-bench-verified/.
OpenAI. gpt-oss-120b & gpt-oss-20b model card. CoRR, abs/2508.10925, 2025. doi: 10.48550/A RXIV.2508.10925. URL https://doi.org/10.48550/arXiv.2508.10925.
M. Osama, D. Merrill, C. Cecka, M. Garland, and J. D. Owens. Stream-k: Work-centric parallel decomposition for dense matrix-matrix multiplication on the gpu. In Proceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 429–431, 2023.
T. Patwardhan, R. Dias, E. Proehl, G. Kim, M. Wang, O. Watkins, S. P. Fishman, M. Aljubeh, P. Thacker, L. Fauconnet, et al. Gdpval: Evaluating ai model performance on real-world economically valuable tasks. arXiv preprint arXiv:2510.04374, 2025.
L. Phan, A. Gatti, Z. Han, N. Li, J. Hu, H. Zhang, C. B. C. Zhang, M. Shaaban, J. Ling, S. Shi, et al. Humanity’s last exam. arXiv preprint arXiv:2501.14249, 2025.
W. Qi, Y. Yan, Y. Gong, D. Liu, N. Duan, J. Chen, R. Zhang, and M. Zhou. Prophetnet: Predicting future n-gram for sequence-to-sequence pre-training. In T. Cohn, Y. He, and Y. Liu, edi- tors, Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020, volume EMNLP 2020 of Findings of ACL, pages 2401–2410. Associa- tion for Computational Linguistics, 2020. URL https://doi.org/10.18653/v1/2020.f indings-emnlp.217.
Qwen. Qwen3 technical report. CoRR, abs/2505.09388, 2025. doi: 10.48550/ARXIV.2505.09388. URL https://doi.org/10.48550/arXiv.2505.09388.
S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He. Zero: Memory optimizations toward training tril- lion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020.
J. K. Reed, Z. DeVito, H. He, A. Ussery, and J. Ansel. Torch.fx: Practical program capture and transformation for deep learning in python, 2022. URL https://arxiv.org/abs/2112.0 8429.
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman. GPQA: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023.
G. T. M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ram’e, J. Ferret, P. Liu, P. D. Tafti, A. Friesen, M. Casbon, S. Ramos, R. Kumar, C. L. Lan, S. Jerome, A. Tsitsulin, N. Vieillard, P. Stańczyk, S. Girgin, N. Momchev, M. Hoff- man, S. Thakoor, J.-B. Grill, B. Neyshabur, A. Walton, A. Severyn, A. Parrish, A. Ahmad, A. Hutchison, A. Abdagic, A. Carl, A. Shen, A. Brock, A. Coenen, A. Laforge, A. Paterson, B. Bastian, B. Piot, B. Wu, B. Royal, C. Chen, C. Kumar, C. Perry, C. A. Welty, C. A. Choquette- Choo, D. Sinopalnikov, D. Weinberger, D. Vijaykumar, D. Rogozi’nska, D. Herbison, E. Bandy, E. Wang, E. Noland, E. Moreira, E. Senter, E. Eltyshev, F. Visin, G. Rasskin, G. Wei, G. Cameron, G. Martins, H. Hashemi, H. Klimczak-Pluci’nska, H. Batra, H. Dhand, I. Nardini, J. Mein, J. Zhou, J. Svensson, J. Stanway, J. Chan, J. Zhou, J. Carrasqueira, J. Iljazi, J. Becker, J. Fernan- dez, J. R. van Amersfoort, J. Gordon, J. Lipschultz, J. Newlan, J. Ji, K. Mohamed, K. Badola, K. Black, K. Millican, K. McDonell, K. Nguyen, K. Sodhia, K. Greene, L. L. Sjoesund, L. Usui, L. Sifre, L. Heuermann, L. cia Lago, L. McNealus, L. B. Soares, L. Kilpatrick, L. Dixon, L. L. B. Martins, M. Reid, M. Singh, M. Iverson, M. Gorner, M. Velloso, M. Wirth, M. Davidow, M. Miller, M. Rahtz, M. Watson, M. Risdal, M. Kazemi, M. Moynihan, M. Zhang, M. Kahng, M. Park, M. Rahman, M. Khatwani, N. Dao, N. shad Bardoliwalla, N. Devanathan, N. Dumai, N. Chauhan, O. Wahltinez, P. Botarda, P. Barnes, P. Barham, P. Michel, P. chong Jin, P. Georgiev, P. Culliton, P. Kuppala, R. Comanescu, R. Merhej, R. Jana, R. A. Rokni, R. Agarwal, R. Mullins, S. Saadat, S. M. M. Carthy, S. Perrin, S. M. R. Arnold, S. bastian Krause, S. Dai, S. Garg, S. Sheth, S. Ronstrom, S. Chan, T. Jordan, T. Yu, T. Eccles, T. Hennigan, T. Kociský, T. Doshi, V. Jain, V. Yadav, V. Meshram, V. Dharmadhikari, W. Barkley, W. Wei, W. Ye, W. Han, W. Kwon, X. Xu, Z. Shen, Z. Gong, Z. Wei, V. Cotruta, P. Kirk, A. Rao, M. Giang, L. Peran, T. Warkentin, E. Collins, J. Barral, Z. Ghahramani, R. Hadsell, D. Sculley, J. Banks, A. Dragan, S. Petrov, O. Vinyals, J. Dean, D. Hassabis, K. Kavukcuoglu, C. Farabet, E. Buchatskaya, S. Borgeaud, N. Fiedel, A. Joulin, K. Kenealy, R. Dadashi, and A. Andreev. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024.
S. Roller, S. Sukhbaatar, A. Szlam, and J. Weston. Hash layers for large sparse models. In M. Ranzato, A. Beygelzimer, Y. N. Dauphin, P. Liang, and J. W. Vaughan, editors, Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 17555–17566, 2021. URL https://proceedings.neurips.cc/paper/2021/hash/92bf5e6240737 e0326ea59846a83e076-Abstract.html.
B. D. Rouhani, R. Zhao, A. More, M. Hall, A. Khodamoradi, S. Deng, D. Choudhary, M. Cornea, E. Dellinger, K. Denolf, S. Dusan, V. Elango, M. Golub, A. Heinecke, P. James-Roxby, D. Jani, G. Kolhe, M. Langhammer, A. Li, L. Melnick, M. Mesmakhosroshahi, A. Rodriguez, M. Schulte, R. Shafipour, L. Shao, M. Siu, P. Dubey, P. Micikevicius, M. Naumov, C. Verrilli, R. Wittig, D. Burger, and E. Chung. Microscaling data formats for deep learning, 2023.
K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y. Choi. Winogrande: An adversarial winograd schema challenge at scale, 2019.
Z. Shao, Y. Luo, C. Lu, Z. Z. Ren, J. Hu, T. Ye, Z. Gou, S. Ma, and X. Zhang. Deepseekmath-v2: Towards self-verifiable mathematical reasoning, 2025. URL https://arxiv.org/abs/25 11.22570.
N. Shazeer. Fast transformer decoding: One write-head is all you need. CoRR, abs/1911.02150, 2019. URL http://arxiv.org/abs/1911.02150.
N. Shazeer. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020.
F. Shi, M. Suzgun, M. Freitag, X. Wang, S. Srivats, S. Vosoughi, H. W. Chung, Y. Tay, S. Ruder, D. Zhou, D. Das, and J. Wei. Language models are multilingual chain-of-thought reasoners. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/forum?i d=fR3wGCk-IXp.
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024.
M. Suzgun, N. Scales, N. Schärli, S. Gehrmann, Y. Tay, H. W. Chung, A. Chowdhery, Q. V. Le, E. H. Chi, D. Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261, 2022.
G. Tsoukalas, J. Lee, J. Jennings, J. Xin, M. Ding, M. Jennings, A. Thakur, and S. Chaudhuri. Putnambench: Evaluating neural theorem-provers on the putnam mathematical competition, 2024. URL https://arxiv.org/abs/2407.11214.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
L. Wang, H. Gao, C. Zhao, X. Sun, and D. Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts. CoRR, abs/2408.15664, 2024a. URL https://doi.org/10.48550/arX iv.2408.15664.
L. Wang, Y. Cheng, Y. Shi, Z. Mo, Z. Tang, W. Xie, T. Wu, L. Ma, Y. Xia, J. Xue, et al. Tilelang: Bridge programmability and performance in modern neural kernels. In The Fourteenth International Conference on Learning Representations, 2026.
Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, T. Li, M. Ku, K. Wang, A. Zhuang, R. Fan, X. Yue, and W. Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. CoRR, abs/2406.01574, 2024b. URL https://doi.org/10.48550/arXiv.2406.01574.
J. Wei, Z. Sun, S. Papay, S. McKinney, J. Han, I. Fulford, H. W. Chung, A. T. Passos, W. Fedus, and A. Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents. arXiv preprint arXiv:2504.12516, 2025.
T. Wei, J. Luan, W. Liu, S. Dong, and B. Wang. Cmath: Can your language model pass chinese elementary school math test?, 2023.
G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview .net/forum?id=NG7sS51zVF.
Z. Xie, Y. Wei, H. Cao, C. Zhao, C. Deng, J. Li, D. Dai, H. Gao, J. Chang, K. Yu, L. Zhao, S. Zhou, Z. Xu, Z. Zhang, W. Zeng, S. Hu, Y. Wang, J. Yuan, L. Wang, and W. Liang. mhc: Manifold- constrained hyper-connections, 2026. URL https://arxiv.org/abs/2512.24880.
L. Xu, H. Hu, X. Zhang, L. Li, C. Cao, Y. Li, Y. Xu, K. Sun, D. Yu, C. Yu, Y. Tian, Q. Dong, W. Liu, B. Shi, Y. Cui, J. Li, J. Zeng, R. Wang, W. Xie, Y. Li, Y. Patterson, Z. Tian, Y. Zhang, H. Zhou, S. Liu, Z. Zhao, Q. Zhao, C. Yue, X. Zhang, Z. Yang, K. Richardson, and Z. Lan. CLUE: A chi- nese language understanding evaluation benchmark. In D. Scott, N. Bel, and C. Zong, editors, Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, pages 4762–4772. International Com- mittee on Computational Linguistics, 2020. doi: 10.18653/V1/2020.COLING-MAIN.419. URL https://doi.org/10.18653/v1/2020.coling-main.419.
J. Yang, K. Lieret, C. E. Jimenez, A. Wettig, K. Khandpur, Y. Zhang, B. Hui, O. Press, L. Schmidt, and D. Yang. Swe-smith: Scaling data for software engineering agents, 2025. URL https: //arxiv.org/abs/2504.21798.
R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. HellaSwag: Can a machine really finish your sentence? In A. Korhonen, D. R. Traum, and L. Màrquez, editors, Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 4791–4800. Association for Computational Linguistics, 2019. doi: 10.18653/v1/p19-1472. URL https://doi.org/10.18653/v1/p1 9-1472.
C. Zhang, K. Du, S. Liu, W. Kwon, X. Mo, Y. Wang, X. Liu, K. You, Z. Li, M. Long, J. Zhai, J. Gonzalez, and I. Stoica. Jenga: Effective memory management for serving llm with heterogeneity. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP ’25, page 446–461, New York, NY, USA, 2025a. Association for Computing Machinery. ISBN 9798400718700. doi: 10.1145/3731569.3764823. URL https://doi.org/10.1145/3731569.3764823.
S. Zhang, N. Zheng, H. Lin, Z. Jiang, W. Bao, C. Jiang, Q. Hou, W. Cui, S. Zheng, L.-W. Chang, Q. Chen, and X. Liu. Comet: Fine-grained computation-communication overlapping for mixture-of-experts. 2025b. URL https://arxiv.org/abs/2502.19811.
C. Zhao, L. Zhao, J. Li, Z. Xu, and C. Xu. Deepgemm: clean and efficient fp8 gemm kernels with fine-grained scaling. https://github.com/deepseek-ai/DeepGEMM, 2025.
W. Zhong, R. Cui, Y. Guo, Y. Liang, S. Lu, Y. Wang, A. Saied, W. Chen, and N. Duan. AGIEval: A human-centric benchmark for evaluating foundation models. CoRR, abs/2304.06364, 2023. doi: 10.48550/arXiv.2304.06364. URL https://doi.org/10.48550/arXiv.2304.06364.
D. Zhu, H. Huang, Z. Huang, Y. Zeng, Y. Mao, B. Wu, Q. Min, and X. Zhou. Hyper- connections. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/forum?id=9FqARW7dwB.
X. Zhu, D. Cheng, H. Li, K. Zhang, E. Hua, X. Lv, N. Ding, Z. Lin, Z. Zheng, and B. Zhou. How to synthesize text data without model collapse? arXiv preprint arXiv:2412.14689, 2024.
T. Y. Zhuo, M. C. Vu, J. Chim, H. Hu, W. Yu, R. Widyasari, I. N. B. Yusuf, H. Zhan, J. He, I. Paul, S. Brunner, C. Gong, J. Hoang, A. R. Zebaze, X. Hong, W. Li, J. Kaddour, M. Xu, Z. Zhang, P. Yadav, and et al. Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/forum?id=YrycTjllL0.
附录 B:评测细节