前沿科学:评估 AI 执行专家级科学任务的能力
FRONTIER SCIENCE: EVALUATING AI’S ABILITY TO PERFORM EXPERT‑LEVEL SCIENTIFIC TASKS
摘要
我们提出 FrontierScience:一个用于评估 AI 在专家级科学推理方面能力的基准。FrontierScience 包含两条赛道:
- Olympiad(奥赛):收录国际科学奥林匹克题目(难度对标 IPhO、IChO、IBO),以短答题形式考察受限场景下的精确解题能力。
- Research(研究):收录博士水平的开放式问题,代表科学研究中会遇到的子任务,考察更开放的推理、判断与对真实研究目标的支撑能力。
总体而言,FrontierScience 由数百道题目构成(其中 160 题组成开源 gold set),覆盖物理、化学、生物多个子领域,从量子电动力学到合成有机化学。近期模型进展已几乎“吃满”现有科学基准——它们往往依赖选择题式知识问答或已公开发表的信息。相比之下,Olympiad 赛道的所有题目均由国际奥赛奖牌得主与国家队教练原创撰写,以确保难度、原创性与事实性;Research 赛道的所有题目则由具有博士学位的科学家(博士生、博士后或教授)撰写并验证。
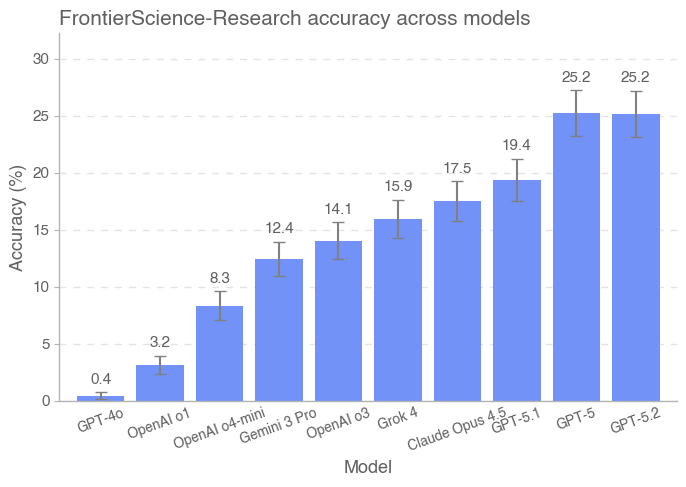
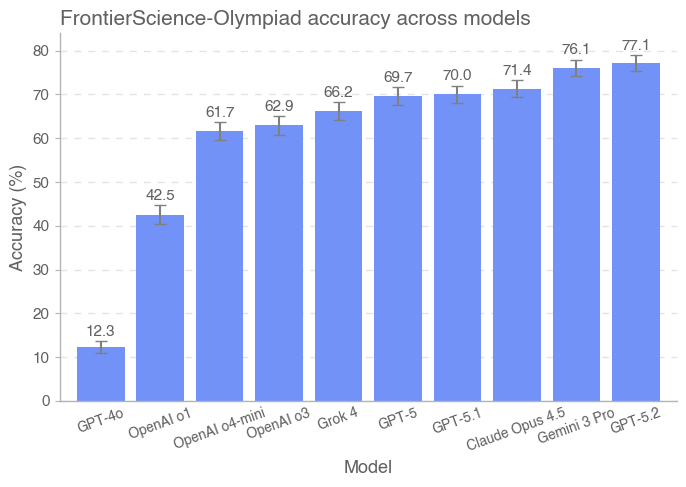
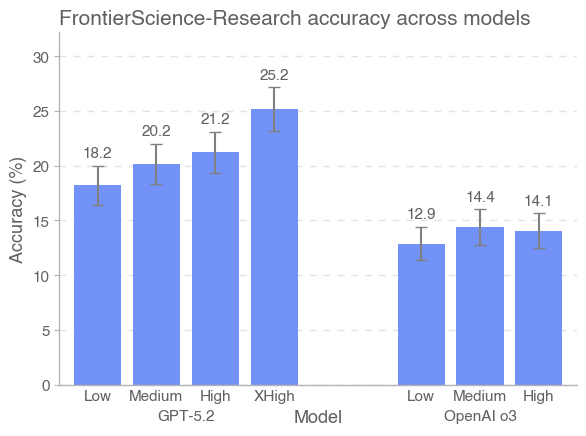
针对 Research,我们还引入一种细粒度的评分细则(rubric)架构,用于评估模型在解决研究任务过程中的各项能力,而不仅仅是判定单一最终答案。对多种前沿模型的初步评测表明,GPT‑5.2 在 FrontierScience 上总体表现最佳:Olympiad 集得分 77%,Research 集得分 25%。
1. 引言
语言模型在科学领域的推理能力已经取得显著进展。2023 年 11 月发布的 GPQA——一个由博士专家撰写、以“Google‑Proof”为目标的多项选择科学基准——中,GPT‑4 的得分为 39%,低于专家基线 70%(Rein 等,2023)。两年后,GPT‑5.2 在该基准上得分达到 92%(OpenAI,2025)。
随着模型推理与知识能力持续扩展,尚未饱和的基准将对衡量与预测模型加速科学研究的能力至关重要。既有基准已能随着模型改进追踪有用的科学能力(Rein 等,2023;He 等,2024;Lu 等,2022;Hendrycks 等,2021)。然而,模型推理能力在近期快速提升,要求新一代科学基准跟上进展节奏。
为了评估真实世界的科学能力,我们提出 FrontierScience:由数百道题目组成,具备高难度、可验证、且原创的特点。FrontierScience 题目由物理、化学、生物等领域专家撰写与验证,包含两个层级:
- FrontierScience‑Olympiad:由国际奥赛奖牌得主设计的科学奥赛风格问题,以短答形式评估科学推理。
- FrontierScience‑Research:由博士科学家(博士生、教授或博士后研究员)设计的研究子问题,模拟开展原创研究时会遇到的子任务。
我们构建这一双层评测集来衡量两类能力:Olympiad 集旨在评估受限设定下的精确解题能力,其解答被设计为可用单个数值或代数表达式(物理与化学)或可进行模糊字符串匹配的答案(生物)自动评测。Research 集则评估更开放的推理、判断,以及支撑真实研究目标的能力;每个 Research 题目都配有专家设计的 10 分评分细则。二者结合,相比以往基准能更全面诊断模型在专家级科学推理上的优势与短板。

在对多种前沿模型的初步评测中,GPT‑5.2 在 FrontierScience 上整体表现最好:Olympiad 集得分 77%,Research 集得分 25%。Gemini 3 Pro 在 Olympiad 上与 GPT‑5.2 接近(76%),而 GPT‑5 在 Research 上与 GPT‑5.2 持平(25%)。总体上,我们发现前沿 AI 系统在解决专家级推理问题方面进展迅速,尤其是在自包含的奥赛题上;但在研究风格任务上仍远未饱和。
2. 基准构建
2.1 数据收集流程
FrontierScience‑Olympiad 题目由 42 位前国际奥赛奖牌得主或国家队教练共同创建,覆盖物理、化学或生物领域;他们合计获得 108 枚奥赛奖牌(45 金、37 银、26 铜)。所有奖牌得主至少(并且常常在多个)下列奥赛中获奖:国际物理奥林匹克(IPhO)、国际化学奥林匹克(IChO)、国际天文与天体物理奥林匹克(IOAA)、欧洲物理奥林匹克(EuPhO)、国际门捷列夫化学奥林匹克(IMChO)。
FrontierScience‑Research 题目由 45 位合格科学家与领域专家共同创建。这些科学家通常来自全球知名机构,身份包括博士后研究员、教授或博士生。定性而言,每个任务被设计为一名博士研究者在研究过程中可能需要解决的子问题,并且通常需要至少 3–5 小时才能完成。
科学家的专长覆盖广泛学科,包括但不限于:量子力学、天体物理、理论与实验物理、生物物理、纳米技术;生物领域中的分子生物学、进化与发育生物学、药理学、基因组学、免疫学与神经科学;以及化学领域中的生物化学、物理与有机化学、材料与计算化学、催化与光化学。专家们都在其领域持续从事研究,对研究方法具有深度熟悉。
每位科学家都为其对应赛道撰写原创题目,并遵循以下指南:
| 维度 | Olympiad(奥赛) | Research(研究) |
|---|---|---|
| 原创性 |
|
|
| 难度 |
|
|
| 可验证性 |
|
|
对于每个 Research 与 Olympiad 题目,科学家会提供一份可获得满分的详细解题方案,以及相关元数据(子领域、难度级别与灵感来源)。随后,每个贡献题目都会由至少一位同行领域专家进行评审(Research 题目至少两轮评审),评估题目各组成部分是否符合上述指南。题目可以受到已知问题启发或引用既有工作,但指南要求任务对评测而言仍应保持新颖。
2.2 验证流程
所有提交的题目都要经历迭代式评审。独立领域专家会逐题阅读题目、答案(Olympiad 为短答案;Research 为评分细则)以及解题说明,并验证题目正确且满足全部指南。题目创建过程中还包含对 OpenAI 内部模型的“反向筛选”(例如:丢弃那些模型能做对的题目),因此我们预计公开评测集会相对更偏向对这些模型不利(相较于其他模型)。
若题目作者与评审者之间出现分歧,双方要么达成一致,要么丢弃该题。只有在两位专家一致认可后,题目才会被提交并加入数据集。随后,各领域专家还会对提交集做最终复核,确保所有题目都与指南一致。
对于 Olympiad 集,所有题目至少经过一次独立评审,随后再由专家进行整体复核。对于 Research 集,所有题目至少经过两次独立评审,随后再由专家进行元评审(meta review)。我们提高了 Research 的评审覆盖度,因为其问题更开放、评分细则是一种更新且更不精确的评分架构。
在 500+ 道 Olympiad 题与 200+ 道 Research 题中,我们与专家进行元评审,筛选出开源 gold set:100 道 Olympiad 题与 60 道 Research 题。其余题目将保留为未公开的保留集,用于跟踪公开集的潜在污染。
2.3 基于评分细则的评测
Olympiad 集的答案可用数值、表达式或模糊字符串匹配进行判分,这提升了可验证性;但这种可验证性常常以牺牲题目的表达力与开放性为代价。对于 Research 集,我们引入一种实验性的、基于评分细则的评测架构,以支持更开放任务的打分。
每道题包含一个由多个相互独立、可客观评估条目组成的评分细则,总分为 10 分。每个条目包含一个具体的通过/失败条件描述(例如“写出如下方程 X”)以及对应分值。评分细则不仅评估最终答案的正确性,也评估中间推理步骤是否正确,从而支持更细粒度的性能诊断与失败分析。获得 10 分中的 7 分被视为可接受解答并标记为成功。由于这种设计是实验性的,我们预计 Research 集的噪声上限会低于 Olympiad 集。
评分细则的可加性还支持未来的其他评测方式,例如报告平均得分、或调整“成功”的阈值。每道题还配有由领域专家撰写的解释性解题路径。为在无需人类专家阅卷的情况下运行评测,我们使用判分模型:给定模型尝试答案与评分细则,输出得分。我们在附录 B 中提供了本文评测所用的判分提示词,并使用高推理努力(high reasoning effort)的 GPT‑5 作为判分模型。
2.4 基准构成
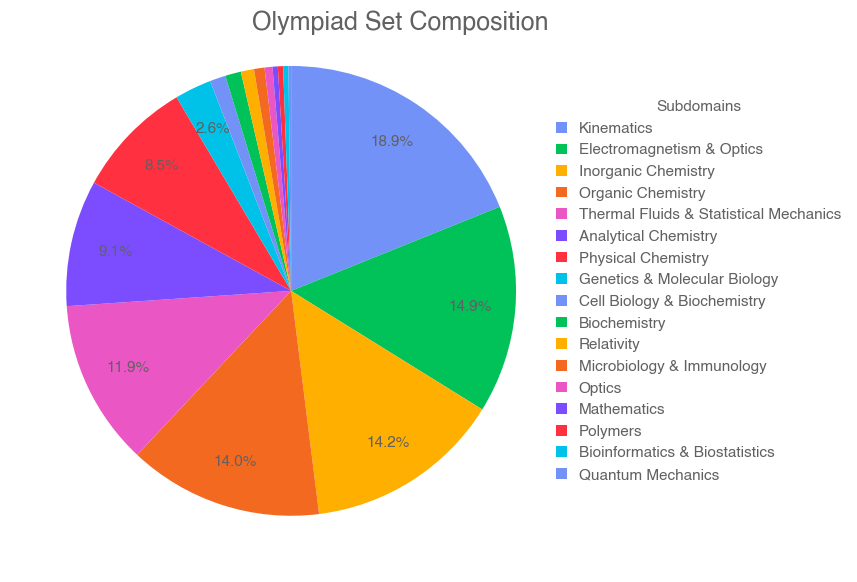
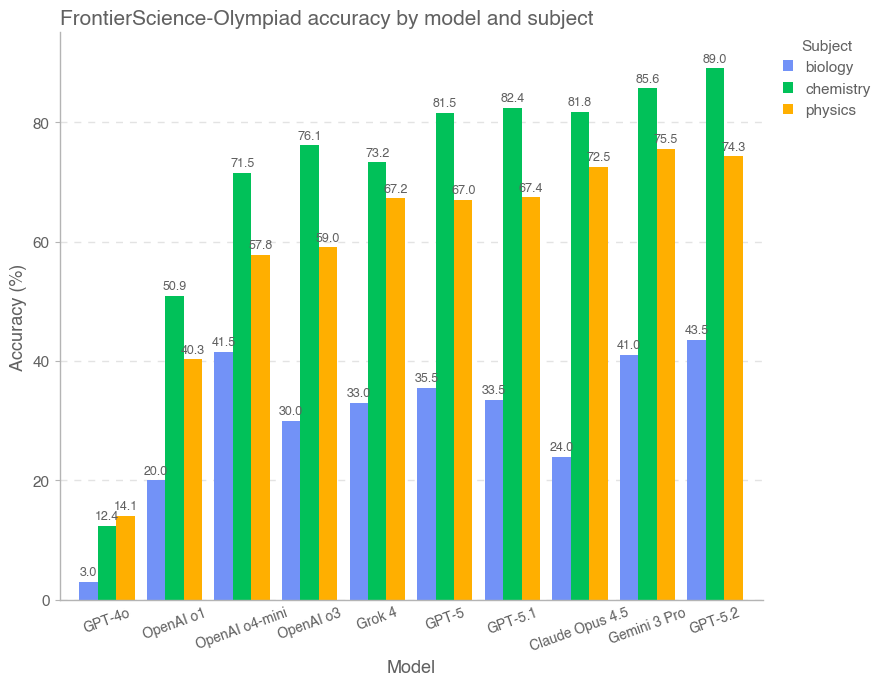
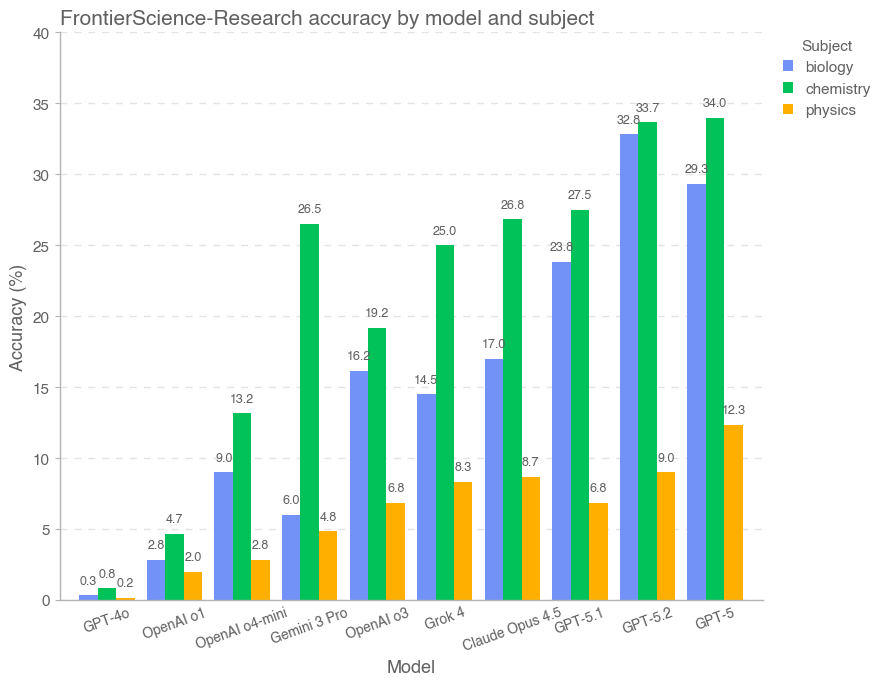
FrontierScience 覆盖广泛的科学问题类型(见图 5)。Olympiad 集扎根于国际科学奥赛常见主题,并且相比生物更偏向物理与化学,因为更容易构造能归约为可验证表达式与数值的题目。Research 集则扎根于贡献者的研究专长;开源 gold set 的 60 道题在物理、化学、生物三个领域均分。
3. 实验
3.1 主要结果
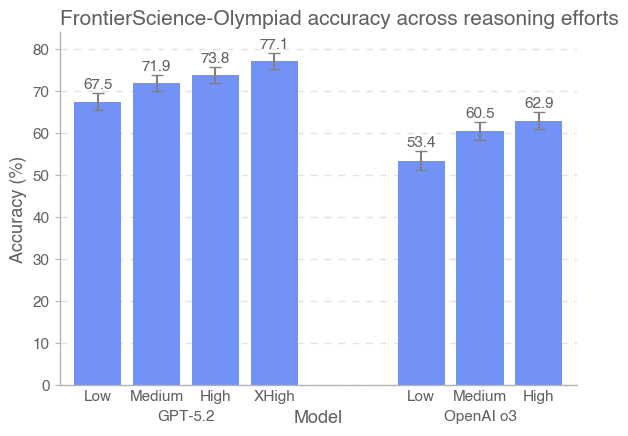
我们在 FrontierScience‑Olympiad 与 FrontierScience‑Research 上评测了多种前沿模型:GPT‑4o、OpenAI o4‑mini、OpenAI o3、GPT‑5.2、Claude Opus 4.5、Gemini 3 Pro、Grok 4、GPT‑5.1 与 GPT‑5。除 GPT‑5.2 采用“xhigh”推理努力外,其余推理模型均在“high”推理努力下评测;同时不使用浏览(browsing)。

初步评测结果显示,GPT‑5.2 在 FrontierScience 上总体表现最佳:Olympiad 集得分 77%,Research 集得分 25%。出人意料的是,GPT‑5 在 Research 集上优于 GPT‑5.1,并与 GPT‑5.2 并列。总体而言,我们在解决专家级问题方面看到了显著进步,同时仍保留大量提升空间——尤其是在开放式的研究风格任务上。
对于两个集合,我们都使用 GPT‑5(推理努力为“high”)作为判分模型。对 Olympiad 集,我们向判分模型提供模型尝试答案与标准答案,并要求其判断表达式、数值或短语是否等价。对 Research 集,我们向判分模型提供模型尝试答案与评分细则,并要求其返回一个反映获得评分条目数的单一分值(见附录 B)。
按学科划分时,模型在各学科分布上的表现整体相近。对 Olympiad 集,化学最好,其次物理,再次生物;对 Research 集,化学最好,其次生物,再次物理。分析模型输出记录(transcripts)表明,模型通常会在推理/逻辑错误、对小众概念理解失败、计算错误以及事实性不准确等方面受阻。
4. 讨论
虽然 FrontierScience 有助于理解 AI 的科学研究能力,但仍存在多项局限:
- 受限的问题设定:科学研究的重要组成部分是提出新的研究方向、假设与想法。FrontierScience 由带有受限题干的问题组成,更侧重评估完成研究任务所需的推理,而较少涉及“创意生成”。尽管 Research 集旨在衡量更开放的推理能力,但这种“可自动评分的问答式评测”天生存在局限。
- 评分细则的可靠性:我们通过严格的指南、验证流程与与人类评分一致性来提升 Research 集评分细则的可靠性。然而,相比“单个表达式/数值等价检查”,评分细则仍更不客观,并依赖判分模型的能力。
- 模态限制:题目被设计为纯文本,不包含图像或视频输出。超越文本的多模态交互更能代表真实科学研究;尤其是现实研究常涉及与现实系统的交互(例如湿实验),而本评测不覆盖这一点。
- 人类基线:我们尚未对该数据集进行人类基线评测,这留待未来工作。由于题目扎根于专家的真实研究领域,一个关键问题是如何开展人类基线:题目高度专业化,可能需要找到该细分领域的专家来完成题目并形成共识基线。
要持续构建长周期、直接相关的评测体系,研究性与实践性评测都很重要。科学推理对 AI 的有益影响至关重要;我们希望未来能持续发展更健壮、更贴近实际的基准,以推动科学进步的加速。
6. 致谢
我们衷心感谢外部合作伙伴与专家评测者的宝贵贡献,包括他们投入的时间、领域专长与深思熟虑的反馈。
我们感谢 Addea Gupta、Alex Karpenko、Andy Applebaum、Bowen Jiang、David Robinson、Elizabeth Proehl、Evan Mays、Grace Kim、Ilge Akkaya、Jerry Tworek、Joy Jiao、Kevin Liu、Leon Maksin、Leyton Ho、Michele Wang、Michele Wang、Nat McAleese、Nikolai Eroshenko、Olivia Watkins、Patrick Chao、Phillip Guo、Phoebe Thacker、Rahul Arora、Ryan Kaufman、Samuel Miserendino、Sebastian Bubeck、Simón Fishman、Stephen McAleer、Ven Chandrasekaran 的讨论、反馈与支持。
参考文献
- Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero‑Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. HealthBench: Evaluating large language models towards improved human health, 2025. URL: https://arxiv.org/abs/2505.08775.
- Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. LLM‑Rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 13806–13834. ACL, 2024. doi: 10.18653/v1/2024.acl-long.745.
- Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. OlympiadBench: A challenging benchmark for promoting AGI with olympiad‑level bilingual multimodal scientific problems. arXiv:2402.14008, 2024.
- Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021.
- Jon M. Laurent, Joseph D. Janizek, Michael Ruzo, Michaela M. Hinks, Michael J. Hammerling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D. White, and Samuel G. Rodriques. LAB‑Bench: Measuring capabilities of language models for biology research, 2024. URL: https://arxiv.org/abs/2407.10362.
- Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, and Kai‑Wei Chang. Learn to Explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neural Information Processing Systems, 2022.
- Adrian Mirza, Nawaf Alampara, Sreekanth Kunchapu, Martiño Ríos‑García, Benedict Emoekabu, Aswanth Krishnan, Tanya Gupta, Mara Schilling‑Wilhelmi, Macjonathan Okereke, Anagha Aneesh, Amir Mohammad Elahi, Mehrdad Asgari, Juliane Eberhardt, Hani M. Elbeheiry, María Victoria Gil, Maximilian Greiner, Caroline T. Holick, Christina Glaubitz, Tim Hoffmann, Abdelrahman Ibrahim, Lea C. Klepsch, Yannik Köster, Fabian Alexander Kreth, Jakob Meyer, Santiago Miret, Jan Matthias Peschel, Michael Ringleb, Nicole Roesner, Johanna Schreiber, Ulrich S. Schubert, Leanne M. Stafast, Dinga Wonanke, Michael Pieler, Philippe Schwaller, and Kevin Maik Jablonka. Are large language models superhuman chemists?, 2024. URL: https://arxiv.org/abs/2404.01475.
- OpenAI. Introducing GPT‑5.2, 2025. URL: https://openai.com/index/introducing-gpt-5-2/. Accessed: 2025‑12‑15.
- Shi Qiu, Shaoyang Guo, Zhuo‑Yang Song, Yunbo Sun, Zeyu Cai, Jiashen Wei, Tianyu Luo, Yixuan Yin, Haoxu Zhang, Yi Hu, Chenyang Wang, Chencheng Tang, Haoling Chang, Qi Liu, Ziheng Zhou, Tianyu Zhang, Jingtian Zhang, Zhangyi Liu, Minghao Li, Yuku Zhang, Boxuan Jing, Xianqi Yin, Yutong Ren, Zizhuo Fu, Jiaming Ji, Weike Wang, Xudong Tian, Anqi Lv, Laifu Man, Jianxiang Li, Feiyu Tao, Qihua Sun, Zhou Liang, Yushu Mu, Zhongxuan Li, Jing‑Jun Zhang, Shutao Zhang, Xiaotian Li, Xingqi Xia, Jiawei Lin, Zheyu Shen, Jiahang Chen, Qiuhao Xiong, Binran Wang, Fengyuan Wang, Ziyang Ni, Bohan Zhang, Fan Cui, Changkun Shao, Qing‑Hong Cao, Mingxing Luo, Yaodong Yang, Muhan Zhang, and Hua Xing Zhu. PHYBench: Holistic evaluation of physical perception and reasoning in large language models, 2025. URL: https://arxiv.org/abs/2504.16074.
- David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate‑level google‑proof Q&A benchmark. arXiv:2311.12022, 2023.
- Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. PaperBench: Evaluating AI’s ability to replicate AI research, 2025. URL: https://arxiv.org/abs/2504.01848.
- Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R. Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. SciBench: Evaluating college‑level scientific problem‑solving abilities of large language models, 2024. URL: https://arxiv.org/abs/2307.10635.
- Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU‑Pro: A more robust and challenging multi‑task language understanding benchmark, 2024. URL: https://arxiv.org/abs/2406.01574.
- Minhui Zhu, Minyang Tian, Xiaocheng Yang, Tianci Zhou, Lifan Yuan, Penghao Zhu, Eli Chertkov, Shengyan Liu, Yufeng Du, Ziming Ji, Indranil Das, Junyi Cao, Jiabin Yu, Peixue Wu, Jinchen He, Yifan Su, Yikun Jiang, Yujie Zhang, Chang Liu, Ze‑Min Huang, Weizhen Jia, Yunkai Wang, Farshid Jafarpour, Yong Zhao, Xinan Chen, Jessie Shelton, Aaron W. Young, John Bartolotta, Wenchao Xu, Yue Sun, Anjun Chu, Victor Colussi, Chris Akers, Nathan Brooks, Wenbo Fu, Jinchao Zhao, Marvin Qi, Anqi Mu, Yubo Yang, Allen Zang, Yang Lyu, Peizhi Mai, Christopher Wilson, Xuefei Guo, Juntai Zhou, Daniel Inafuku, Chi Xue, Luyu Gao, Ze Yang, Yaïr Hein, Yonatan Kahn, Kevin Zhou, Di Luo, John Drew Wilson, Jarrod T. Reilly, Dmytro Bandak, Ofir Press, Liang Yang, Xueying Wang, Hao Tong, Nicolas Chia, Eliu Huerta, and Hao Peng. Probing the critical point (CritPt) of AI reasoning: A frontier physics research benchmark, 2025. URL: https://arxiv.org/abs/2509.26574.
附录
A. 完整示例研究问题
本节展示 Research 集的完整示例题(节选),用于说明题干、评分细则与评测结构。



B. 评测提示
为开展评测,我们使用基于 GPT‑5 思考、并设置为高推理努力的判分模型来评判回答。这里给出本文评测所使用的提示词原文,并提供中文译文。
FrontierScience‑Olympiad 判分提示(中文译文 + 英文原文)
中文译文
你正在给一份科学奥赛题的“尝试答案”打分。你将收到题目、尝试答案以及参考答案。
请将尝试答案与参考答案进行比对,确保其完整并与参考答案一致。请特别注意细节,严格但公正地评分。
参考答案可能是:一个数字或 LaTeX 格式的表达式、一个化学式、一个化合物名称,或指向特定名称/实体/方法的短语。
若尝试答案与参考答案完全一致,或在意义上等价(例如:等价的代数表达式;在 1 位小数舍入误差内的数值,例如 6.69 ≈ 6.7;考虑单位后的等价;化合物/化学式的等价名称等),则判为正确;否则判为错误。
***
题目:{problem}
***
参考答案:{reference answer}
***
尝试答案:{answer}
***
首先,请逐步思考尝试答案是否与参考答案匹配。
如果尝试答案正确,请在你回复的最后一行只写:VERDICT: CORRECT(不要包含其他文字或格式)。
如果不正确,请在最后一行只写:VERDICT: INCORRECT。英文原文
You are grading an attempted answer to a science olympiad problem. You will be given the
problem, attempted answer, and reference answer. Evaluate the solution against the provided
reference solution, ensuring it is complete and matches the reference solution. Pay close
attention to detail and grade it strictly, but fairly.
The reference answer is either a single number or expression in latex formatting, a chemical
formula, a compound name, or a phrase referring to a specific name, entity, or method.
Mark the attempted answer as correct if it fully matches the reference answer or is otherwise
equivalent (e.g., an equivalent algebraic expression, a numerical number within 1 decimal
place rounding of the reference answer (e.g., 6.69 ≈ 6.7), an equivalent name for a compound/formula,
equivalent when accounting for units, etc.). Mark it as incorrect if it is not equivalent to the reference answer.
***
The problem: {problem}
***
The reference answer: {reference answer}
***
The attempted answer: {answer}
***
First, think step-by-step about whether the attempted answer matches the reference answer.
If the attempted answer is correct, write "VERDICT: CORRECT" in the last line of your response,
with no other text or formatting. If it is incorrect, write "VERDICT: INCORRECT".FrontierScience‑Research 判分提示(中文译文 + 英文原文)
中文译文
你正在给一份科学考试打分。
你将收到题目、尝试答案,以及用于评分的评分细则(rubric)。评分细则总分为 10 分。
请仅依据评分细则评估尝试答案。请特别注意细节,严格但公正地评分。你不应作出任何超出评分细则之外的判断
(例如:即便你认为答案正确但评分细则本身有误,也应将评分细则视为金标准)。
请返回最终获得的绝对总分(可以是小数)。
***
题目:{problem}
***
评分细则:{rubric}
***
尝试答案:{answer}
***
首先,请逐条分析每个评分条目,并解释你的理由。
然后汇总得分,并在你回复的最后一行写:VERDICT: <total_points>(不要包含其他文字)。
例如:VERDICT: 2.5 或 VERDICT: 8。英文原文
You are grading a science exam.
You will be given the problem, attempted answer, and a rubric to grade the answer. The rubric
will total up to 10 points.
Evaluate the attemped answer against the provided rubric. Pay close attention to detail and
grade it strictly, but fairly. Only evaluate against the rubric, as you yourself should not make
any judgements (e.g., even if you think the answer is correct but rubric is wrong, you should
treat the rubric as the gold standard). Return the absolute total number of points earned (it can
be a decimal based on the rubric). ***
The problem: {problem}
***
The rubric: {rubric}
***
The attempted answer: {answer}
***
First, think step-by-step about each rubric item. Explain your reasoning for each rubric item.
Then, tally the points up and write VERDICT: <total_points> in the last line of your response,
no other text. For example, VERDICT: 2.5 or VERDICT: 8.
C. 题目要求
下列为给题目作者的要求摘要,分别适用于 Research 与 Olympiad 两条赛道。
Research 题目指南
- 题目清晰:必须显式定义所需的背景信息、变量、符号与假设;模型应获得与领域专家解题所需的同等输入。若因信息缺失导致模型失败,应调整描述或任务措辞。
- 原创性:若题目受到公开来源(如研究论文)启发,题目与/或答案数值应做实质性修改。
- 评分一致性:评分条目必须彼此独立且可客观评估;每个条目应肯定式、清晰且明确陈述得分条件,避免含糊;给出具体通过/失败条件(如“写出如下方程 X”);定义所有变量与缩写;确保人类与模型判分差异总体不超过 0.5 分。
- 难度:题目应足够有挑战性,通常需要 3–5 小时撰写,以充分测试推理深度;题目应测试问题求解能力,而非文风、搜索或时效性(知识截止)。
Olympiad 题目指南
- 正确性(确保题目正确且完整):提供全部假设并定义所有变量;使用正确的物理/方程;确保题目不会产生多种解释。
- 可验证性(确保题目可验证):提供最终答案中使用到的全部变量;明确方向/正负号等信息;LaTeX 表达清晰且不含 Unicode 字符,确保函数格式正确(常见错误是写
sin而非\sin);为被求解量定义变量名;答案必须是单个数值或代数表达式;若最终答案使用单位,需明确指定单位与符号(例如“用 m 表示米”)。
