使用大语言模型从零开始辅助撰写类维基百科文章(STORM)
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
摘要
我们研究如何使用大语言模型从零开始撰写有依据(grounded)且结构清晰的长篇文章,使其在广度与深度上可与维基百科页面相当。这一相对欠探索的问题在“写作前”(pre-writing)阶段提出了新的挑战,包括如何检索与研究主题,以及在正式写作之前如何准备文章大纲。
我们提出 STORM(Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking),一个面向写作前阶段的写作系统。STORM 将写作前阶段建模为:(1) 在研究给定主题时发现多样化视角;(2) 模拟对话:由携带不同视角的写作者向基于可信互联网来源的主题专家提出问题;(3) 对收集到的信息进行整理归纳,从而生成文章大纲。
在评估方面,我们构建 FreshWiki 数据集,收录近期高质量的维基百科文章,并制定大纲评测指标以评价写作前阶段。我们进一步邀请经验丰富的维基百科编辑给出专家反馈。与一种以大纲驱动的检索增强基线生成的文章相比,编辑们认为 STORM 生成的文章在组织性上有 25% 的绝对提升,在覆盖广度上提升 10%。专家反馈也揭示了生成“有依据”的长文档的新挑战,例如来源偏见的迁移,以及将不相关事实过度关联的问题。
1. 引言
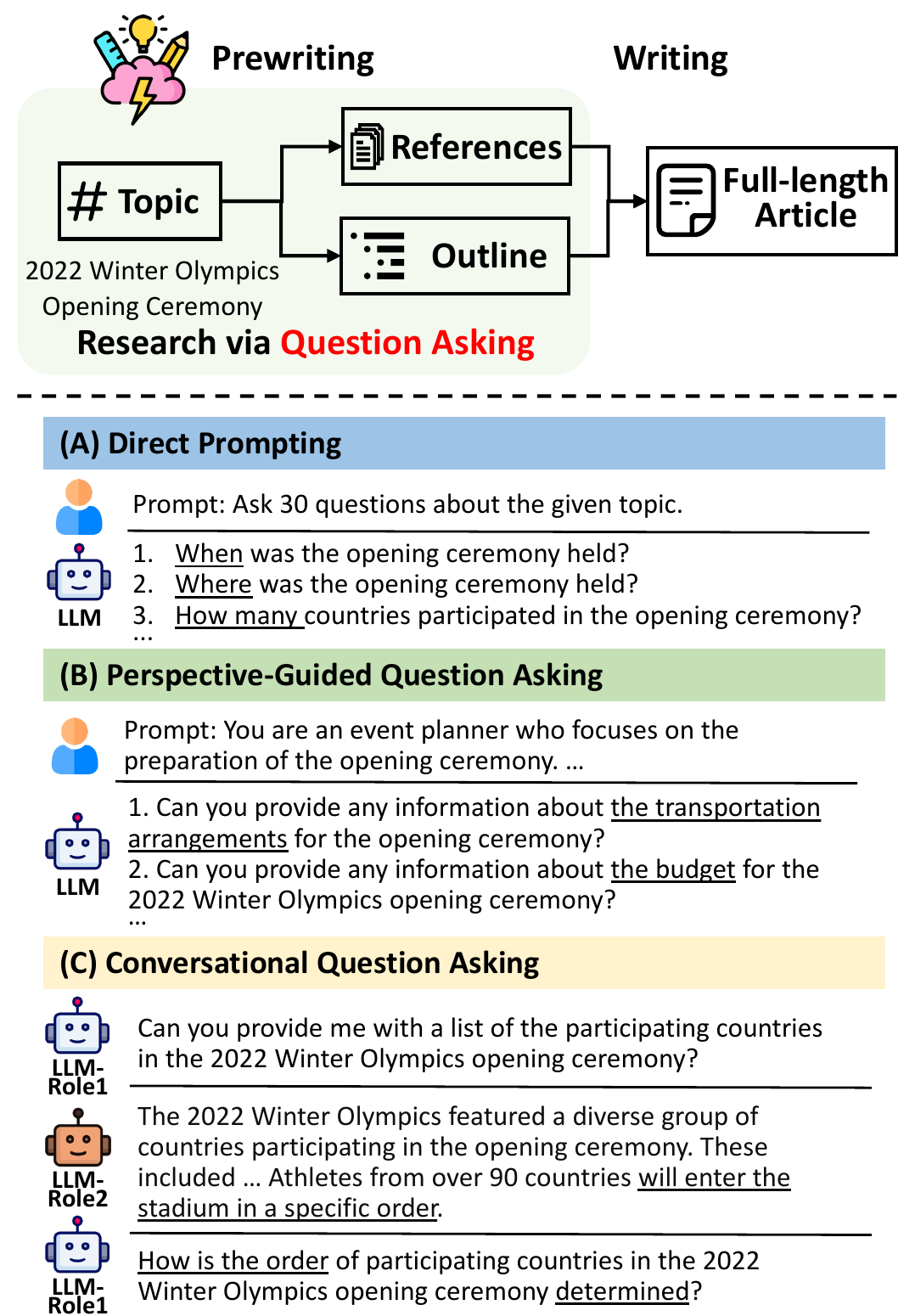
大语言模型(LLM)已经展现出令人印象深刻的写作能力[60,39,58,13],但我们仍不清楚如何利用它们来撰写像完整维基百科页面那样“有依据”(grounded)的长篇文章。此类说明性写作(expository writing)旨在以组织化的方式向读者介绍某一主题[57,4],在正式动笔之前通常就需要在写作前(pre-writing)阶段进行充分的研究与规划[48]。
然而,既有的维基百科文章生成研究通常绕开了写作前阶段[5,34,31,11]:例如,[31] 预设参考文档已事先提供,而 [11] 假设文章大纲可用并把重点放在扩写各个小节。这些假设在一般情况下并不成立,因为收集参考资料并构建大纲需要较强的信息素养能力[9],包括识别、评估与组织外部来源——即便对有经验的写作者而言也并不容易。将这一过程自动化能够帮助个体开启对某个主题的深入学习,并显著减少说明性写作所需的昂贵专家工时。
我们通过聚焦“从零开始”生成类维基百科文章来系统性地研究这些挑战。我们将问题分解为两个子任务:其一是开展研究以生成大纲(即多层级章节列表)并收集一组参考文档;其二是在给定大纲与参考文档的前提下生成完整文章。这样的任务分解与人类写作过程相一致:人类写作通常包含写作前、起草与修订等阶段[48,35]。
由于预训练语言模型本身蕴含大量知识,一种直接方式是依赖其参数化知识来生成大纲甚至整篇文章(Direct Gen)。但这种方式往往缺乏细节且更易产生幻觉[59],尤其在长尾主题上问题更突出[21]。这凸显了利用外部来源的重要性,而当前常见策略是检索增强生成(RAG)——这又回到了写作前阶段的“研究”问题:大量信息无法仅靠简单的主题检索就被充分检索出来。
人类学习理论强调,在信息获取过程中“提出有效问题”具有关键作用[56,7]。尽管指令微调模型可以被直接提示来生成问题[37],但我们发现它们往往只会提出“什么/何时/何地”这类基础问题(图 1(A)),通常只能覆盖主题的表层事实。为赋予 LLM 更强的研究能力,我们提出 STORM(通过检索与多视角提问综合主题大纲):Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking。
STORM 的设计基于两条假设:(1) 多样化视角会引出不同的问题;(2) 形成深入问题需要迭代式研究。基于此,STORM 采用一个新的多阶段流程:它首先通过检索并分析相近主题的维基百科文章来发现多种视角,然后为 LLM 赋予特定视角以进行提问(图 1(B))。接着,为了诱发追问并实现迭代研究(图 1(C)),STORM 模拟多轮对话,并将回答建立在来自互联网的可信信息之上。最后,结合 LLM 的内部知识与多视角对话中收集的信息,STORM 生成一个可逐节扩写的文章大纲,从而写出完整的类维基百科文章。
我们使用 FreshWiki 数据集(见第 2.1 节)评估 STORM。FreshWiki 收录近期高质量维基百科文章,以避免在预训练中产生数据泄漏。本文资源与代码已开源发布:https://github.com/stanford-oval/storm。为便于研究写作前阶段,我们定义了用于对比人类文章的大纲质量指标。
我们进一步邀请经验丰富的维基百科编辑进行专家评估。编辑们认为,STORM 相比以大纲驱动的 RAG 基线表现更好,尤其体现在文章的覆盖广度与组织结构上。专家反馈也指出未来研究应解决的挑战,包括:(1) 互联网来源的偏见会影响生成文章;(2) LLM 会捏造不相关事实之间的联系。这些挑战为“有依据”的写作系统提出了新的前沿问题。
我们的主要贡献如下:
- 为评估 LLM 系统从零生成长篇、可溯源文章的能力,尤其是写作前阶段的挑战,我们构建 FreshWiki 数据集,并建立大纲与最终文章质量的评估标准。
- 我们提出 STORM,一个可自动化写作前阶段的新系统。STORM 通过让 LLM 提出更具洞见的问题,并从互联网上检索可信信息来研究主题并生成大纲。
- 自动评估与人工评估均验证了该方法的有效性;专家反馈进一步揭示了生成有依据长文的新挑战。
2. FreshWiki
我们研究从零开始生成类维基百科文章,重点关注写作前(pre-writing)阶段[48]:该阶段包含收集并整理相关信息(“研究”)等高要求子任务。这也刻画了人类写作路径,并促使一些教育者将“撰写维基百科文章”视为一种学术训练的教学练习[55]。
| 工作 | 领域 | 范围 | 给定大纲? | 给定参考资料? |
|---|---|---|---|---|
| Balepur 等(2023)[4] | 单一 | 单段 | / | 是 |
| Qian 等(2023)[43] | 全领域 | 单段 | / | 否 |
| Fan & Gardent(2022)[11] | 单一 | 全文 | 是 | 否 |
| J. 等(2018)[31] | 全领域 | 单段 | / | 是 |
| Sauper & Barzilay(2009)[49] | 两个 | 全文 | 否 | 否 |
| 本文(STORM) | 全领域 | 全文 | 否 | 否 |
表 1:现有文献中不同维基百科生成设定的对比。生成单段文本通常不需要文章大纲。
表 1 将我们的工作与既往维基百科生成基准进行对比。既有工作通常关注更短片段(例如单段)、更窄范围(例如特定领域或两个领域),或在已提供明确大纲/参考文档的设定下进行评估。一个典型例子是 WikiSum[31]:它把维基百科文章生成视为多文档摘要任务,并以参考文档为条件。
我们的设定强调长篇、可溯源写作系统在“研究与整理内容”上的能力。具体而言,给定主题 $t$,任务是找到一组参考资料 $\mathcal{R}$,并生成完整文章 $\mathcal{S}=s_1s_2...s_n$,其中每个句子 $s_i$ 都引用 $\mathcal{R}$ 中的若干文档。(在实践中,$\mathcal{S}$ 还包含章节与子章节标题等组织性元素,这些不需要引用。)
2.1 FreshWiki 数据集
从零创建一篇新的类维基百科文章不仅要求写作流畅,还需要良好的研究能力。由于现代 LLM 通常在维基百科文本上进行训练,我们通过显式寻找近期维基百科文章来缓解数据泄漏:这些文章在我们测试的 LLM 训练截断日期之后被创建(或被大量编辑)。当未来出现新的 LLM 时,这一流程也可在新的时间点重复执行。
为满足日期标准,我们以 2022 年 2 月至 2023 年 9 月每个月的“编辑次数最多的前 100 个页面”为候选集合,而非直接使用页面创建日期作为截断,因为多数维基百科文章在初建时是“短小条目(stub)”或质量较低。上述“编辑最多页面”数据来自 Wikimedia 指标接口:https://wikimedia.org/api/rest_v1/metrics/edited-pages/top-by-edits/en.wikipedia/all-editor-types/content/ {year}/{month}/all-days。
为确保参考文章质量,我们进一步筛选,仅保留由 ORES 评估为 B 级及以上质量的条目(https://www.mediawiki.org/wiki/ORES)。根据维基百科统计,仅约 3% 的现有页面满足这一质量标准。由于 LLM 已经能够生成相当不错的输出,我们认为后续研究应以高质量人类文章作为参照更为重要。
我们还排除列表型条目(https://en.wikipedia.org/wiki/Wikipedia:Stand-alone_lists)以及没有子章节的条目。尽管高质量维基百科文章通常包含结构化数据(例如表格)并且具有多模态特征,本工作为简化任务,只在构建数据集时考虑纯文本部分。更多数据集细节见附录 A。
2.2 大纲创建与评估
长篇文章既难生成也难评估[59,26]。在人类教育者教授学术写作时,有时会在“大纲阶段”对学生进行监督[10],因为一份详尽的大纲往往意味着对主题的全面理解,并能为写作全文提供稳固基础[8]。受此启发,我们将 $\mathcal{S}$ 的生成分为两个阶段:在写作前阶段,系统需要创建大纲 $\mathcal{O}$(定义为多层级章节标题列表;由于语言模型处理与生成序列,我们可通过在标题前添加 “#”、“##”、“###” 等符号对 $\mathcal{O}$ 进行线性化);在写作阶段,系统使用主题 $t$、参考资料 $\mathcal{R}$ 与大纲 $\mathcal{O}$ 生成完整文章 $\mathcal{S}$。
为评估大纲覆盖度,我们提出两个指标:标题软召回率(heading soft recall)与 标题实体召回率(heading entity recall)。这两个指标比较人类文章(作为真值)与生成大纲 $\mathcal{O}$ 的多层级标题集合。考虑到标题不必逐字完全匹配,我们使用 Sentence-BERT 嵌入的余弦相似度来计算标题软召回率(细节见附录 C.1)[14,47]。
我们还计算标题实体召回率:将其定义为“人类文章标题中出现的命名实体被 $\mathcal{O}$ 覆盖的比例”。命名实体通过 FLAIR 命名实体识别(NER)抽取[2]。
3. 方法
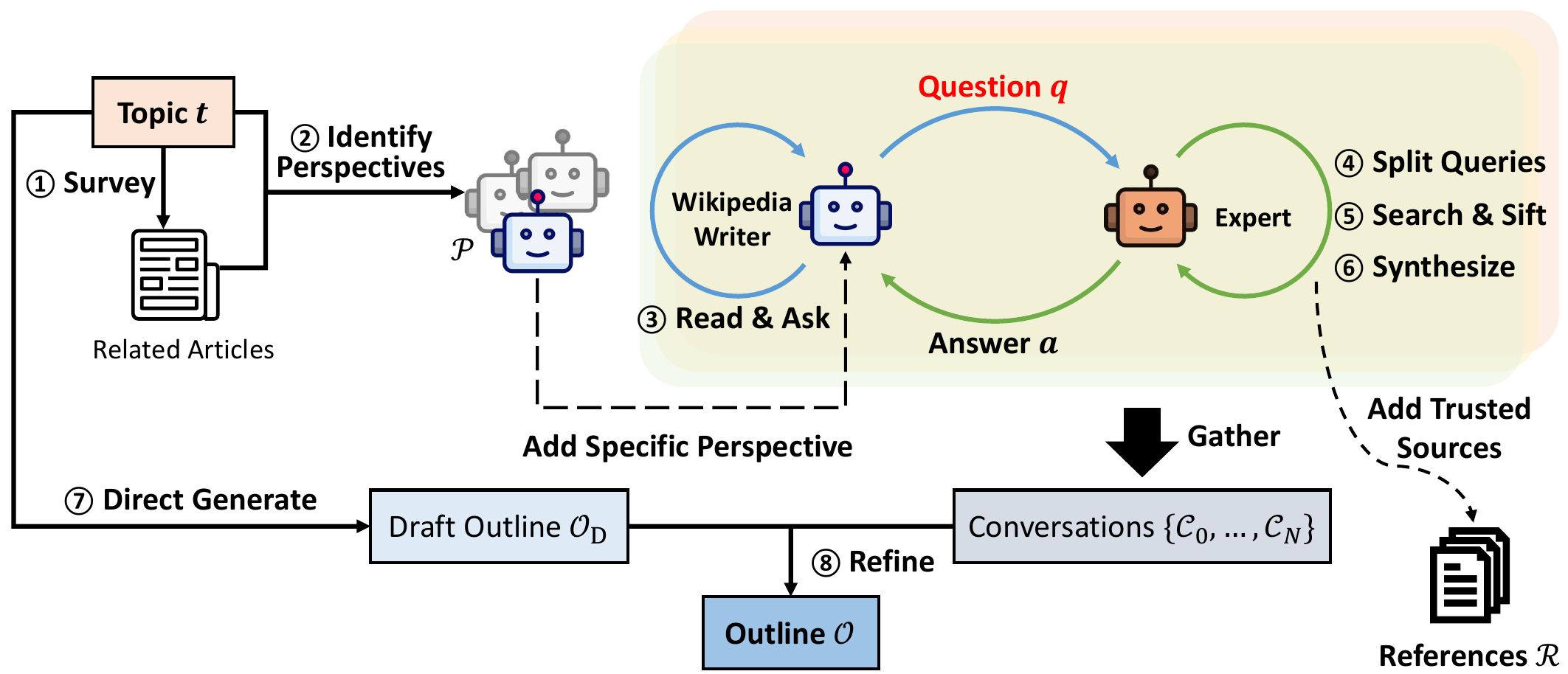
我们提出 STORM 以自动化写作前阶段:通过有效提问来研究给定主题(第 3.1–3.2 节),并据此生成文章大纲(第 3.3 节)。该大纲随后会在收集到的参考资料支持下被逐节扩写为完整文章(第 3.4 节)。图 2 展示了 STORM 的整体流程;伪代码见附录 B。
3.1 视角引导提问
Rohman(1965)将写作前阶段定义为写作过程中的“发现(discovery)”阶段[48]。类似于商业中的利益相关者理论(stakeholder theory)[15]:不同利益相关者会优先关注公司不同方面——在研究同一主题时,具有不同视角的人也会聚焦不同侧面,从而发现更为多面的信息。进一步地,具体视角还能作为一种先验知识,指导人们提出更深入的问题。例如,面对“2022 年冬奥会开幕式”这一主题,活动策划者可能会关注“交通安排”“预算”等问题,而普通读者更可能提出更一般性的基础信息问题(图 1(A))。
给定输入主题 $t$,STORM 通过调研相近主题的现有文章来发现不同视角,并用这些视角来控制提问过程。具体而言,STORM 首先提示 LLM 生成一组相关主题,然后通过 Wikipedia API 获取这些相关主题对应的维基百科文章并提取其目录(TOC)以作为上下文(图 2①;Wikipedia API:https://pypi.org/project/Wikipedia-API/)。接着,将这些目录拼接后输入 LLM,以识别可共同促成对主题 $t$ 的全面覆盖的 $N$ 个视角 $\mathcal{P}=\{p_1,...,p_N\}$(图 2②)。为确保主题的基础信息也能被覆盖,我们额外添加 $p_0$:“聚焦广泛覆盖主题基本事实的基础事实写作者”。$\mathcal{P}$ 中每个视角 $p$ 会被并行用于引导 LLM 提问。
3.2 对话模拟
问题与提问理论指出:对既有问题的回答会帮助形成对主题更完整的理解,同时也常常引出新的问题[45]。为启动这一动态过程,STORM 模拟一段“维基百科写作者—主题专家”的对话。在对话的第 $i$ 轮中,由 LLM 驱动的写作者基于主题 $t$、其分配视角 $p\in\mathcal{P}$,以及对话历史 $\{q_1,a_1,...,q_{i-1},a_{i-1}\}$ 生成一个问题 $q_i$,其中 $a_j$ 表示模拟专家对 $q_j$ 的回答。对话历史使 LLM 能够不断更新对主题的理解并提出追问。在实现中,我们将对话轮数最多限制为 $M$ 轮。
为确保对话历史包含事实信息,我们使用来自互联网的可信来源将每个问题 $q_i$ 的回答 $a_i$ 建立在可追溯证据之上。由于 $q_i$ 可能较为复杂,我们首先提示 LLM 将 $q_i$ 分解为一组搜索查询(图 2④),然后依据维基百科“可靠来源”指引(https://en.wikipedia.org/wiki/Wikipedia:Reliable_sources)对搜索结果进行规则过滤,以排除不可信来源(图 2⑤)。最后,LLM 综合可信来源生成回答 $a_i$;这些来源也会被加入参考集合 $\mathcal{R}$,用于后续生成完整文章(第 3.4 节)。
3.3 创建大纲
当通过 $N+1$ 段模拟对话(记为 $\{\mathcal{C}_0,\mathcal{C}_1,...,\mathcal{C}_N\}$)对主题完成充分研究后,STORM 会在正式写作之前生成文章大纲。为充分利用 LLM 的内在知识,我们首先仅给定主题 $t$,提示模型生成一个草稿大纲 $\mathcal{O}_\text{D}$(图 2⑦);$\mathcal{O}_\text{D}$ 通常提供一个总体性的、结构清晰的框架。随后,LLM 被输入主题 $t$、草稿大纲 $\mathcal{O}_\text{D}$ 以及多视角对话 $\{\mathcal{C}_0,\mathcal{C}_1,...,\mathcal{C}_N\}$,以进一步完善大纲(图 2⑧),得到改进后的大纲 $\mathcal{O}$,用于生成完整文章。
3.4 撰写全文
基于写作前阶段收集的参考资料 $\mathcal{R}$ 与生成的大纲 $\mathcal{O}$,系统可以逐节撰写全文。由于通常无法将整个 $\mathcal{R}$ 放入 LLM 的上下文窗口,我们使用“章节标题 + 该章节所有层级子标题”从 $\mathcal{R}$ 中按语义相似度检索相关文档;相似度由 Sentence-BERT 嵌入计算得到。有了相关信息后,LLM 被提示生成该章节并附带引用。所有章节生成后,将其拼接成完整文章。
由于各章节可并行生成,最终拼接后可能存在重复信息;为提升连贯性,我们进一步提示 LLM 基于拼接后的文章删除重复内容。此外,遵循维基百科写作风格,LLM 还会对整篇文章生成摘要,作为文章开头的导语(lead section)。
4. 实验
4.1 文章选择
STORM 能够研究较为复杂的主题,并依据细粒度大纲撰写长篇文章。然而在本次受控实验中,我们将最终输出限制在最多 4000 tokens(约 3000 词)。为进行有意义的对比,我们从 FreshWiki 数据集中随机抽取 100 个样本(见第 2.1 节),并要求其人类撰写文章长度不超过 3000 词。
4.2 自动指标
如第 2.2 节所述,我们通过计算标题软召回率与标题实体召回率来评估大纲质量,从而衡量写作前阶段的表现。更高的召回率意味着相较于人类文章,大纲覆盖更全面。
为评估最终长文质量,我们采用 ROUGE 指标[29],并基于 FLAIR NER 结果计算文章层面的实体召回率[2]。此外,我们参考维基百科“优良条目标准”(https://en.wikipedia.org/wiki/Wikipedia:Good_article_criteria),从以下方面评估文章:(1) 兴趣度(Interest Level),(2) 连贯性与组织性(Coherence and Organization),(3) 相关性与聚焦(Relevance and Focus),(4) 覆盖度(Coverage),以及 (5) 可核查性(Verifiability)。对于 (1)–(4),我们使用 Prometheus[24](13B 评测模型)依据与两位资深维基百科编辑共同制定的 5 分制评分细则对文章打分(见附录 C.2)。对于可核查性,我们按 Gao 等人[16] 的定义计算 citation recall 与 citation precision,并使用 Mistral 7B-Instruct[19] 判断引用片段是否蕴含生成句子。
| 方法 | ROUGE‑1 | ROUGE‑L | 实体召回率 | 兴趣度 | 组织性 | 相关性 | 覆盖度 |
|---|---|---|---|---|---|---|---|
| Direct Gen | 25.62 | 12.63 | 5.08 | 2.87 | 4.60 | 3.10 | 4.16 |
| RAG | 28.52 | 13.18 | 7.57 | 3.14 | 4.22 | 3.05 | 4.08 |
| oRAG | 44.26 | 16.51 | 12.57 | 3.90 | 4.79 | 4.09 | 4.70 |
| STORM | 45.82 | 16.70 | 14.10† | 3.99† | 4.82 | 4.45† | 4.88† |
| STORM(去除大纲阶段) | 26.77 | 12.77 | 7.39 | 3.33 | 4.87 | 3.35 | 4.37 |
表 2:自动文章质量评估结果。† 表示与最佳基线(oRAG)相比,配对 $t$ 检验差异显著($p<0.05$)。评分细则(rubric)为 1–5 分制。
| 模型 | 方法 | 标题软召回率(%) | 标题实体召回率(%) |
|---|---|---|---|
| GPT‑3.5 | Direct Gen | 80.23 | 32.39 |
| RAG / oRAG | 73.59 | 33.85 | |
| RAG‑expand | 74.40 | 33.85 | |
| STORM | 86.26† | 40.52† | |
| STORM(去除视角) | 84.49 | 40.12 | |
| STORM(去除对话) | 77.97 | 31.98 | |
| GPT‑4 | Direct Gen | 87.66 | 34.78 |
| RAG / oRAG | 89.55 | 42.38 | |
| RAG‑expand | 91.36 | 43.53 | |
| STORM | 92.73† | 45.91 | |
| STORM(去除视角) | 92.39 | 42.70 | |
| STORM(去除对话) | 88.75 | 39.30 |
表 3:大纲质量评估结果(%)。† 表示与基线相比配对 $t$ 检验差异显著($p<0.05$)。
4.3 基线
由于既有工作采用不同设定且多不使用 LLM,难以直接对比。我们因此构建了如下三个基于 LLM 的基线:
- Direct Gen:直接提示 LLM 生成文章大纲,再据此生成全文。
- RAG:用主题检索信息,并将检索结果与主题 $t$ 一并输入以生成大纲或整篇文章。
- 大纲驱动的 RAG(oRAG):在大纲生成阶段与 RAG 相同,但在写作阶段会进一步用章节标题检索额外信息,并按章节逐节生成全文。
4.4 实现细节
我们使用 DSPy 框架[23] 以零样本提示实现 STORM。伪代码与对应提示见附录 B。超参数 $N$ 与 $M$ 均设为 5。我们使用聊天模型 gpt-3.5-turbo 负责提问环节,并用 gpt-3.5-turbo-instruct 完成 STORM 的其他部分;同时我们也实验了使用 gpt-4 来起草与完善大纲(图 2⑦–⑧)。
在本文报告的结果中,STORM 的“主题专家”基于 You.com 的搜索 API 进行检索增强(https://documentation.you.com/api-reference/search),但所提出的流水线也兼容其他搜索引擎。我们从搜索结果中排除对应的真值维基百科文章。
在最终文章生成中,我们仅报告使用 gpt-4 的结果,因为 gpt-3.5 在生成带引用的文本时对来源不够忠实[16]。所有实验中温度(temperature)设为 1.0,top_p 设为 0.9。
5. 结果与分析
5.1 主要结果
我们使用大纲覆盖度作为衡量写作前阶段的代理指标(见第 2.2 节)。表 3 报告了标题软召回率与标题实体召回率。直接由 LLM 生成的大纲(Direct Gen)已经具有较高的标题软召回率,这体现了 LLM 依托其丰富参数化知识对主题高层要点的把握能力。但 STORM 通过更有效的提问来研究主题,能够生成召回率更高的大纲,从而覆盖更多与主题相关的细节。
值得注意的是,尽管 RAG 利用了额外信息,但把未经组织的检索结果直接堆叠进上下文窗口,会让较弱的模型(例如 GPT‑3.5)的“大纲生成”任务变得更困难,反而导致性能下降。为测试 RAG 基线的上限,我们进一步扩展检索来源:先用 RAG 生成初始大纲,再以其章节标题作为搜索查询收集更多来源,并将新增来源与初始大纲一并输入 LLM 生成更完善的大纲。我们将该改动称为 RAG‑expand(见表 3)。结果表明,尽管额外的检索与完善步骤能改进 RAG 生成的大纲,STORM 仍显著优于该方法。
我们进一步评估最终长文质量。如表 2 所示,oRAG 显著优于 RAG,说明“用大纲组织长文生成”是有效的。尽管 oRAG 在检索与大纲使用上有优势,STORM 仍能进一步超越它:有效提问机制带来了更高的实体召回率;评测模型也在“兴趣度”“相关性与聚焦”“覆盖度”等方面给出更高评分。我们也意识到评测模型可能会高估机器生成文本,因此在第 6 节中进一步给出更谨慎的人类评估;结果显示 STORM 仍有较大改进空间。
| 指标 | Citation Recall | Citation Precision |
|---|---|---|
| STORM | 84.83 | 85.18 |
表 4:由 Mistral 7B‑Instruct 判断的引用质量。
尽管本文主要关注写作前阶段,并未专门优化“带引用的文本生成”,我们仍检查了 STORM 生成文章的引用质量。表 4 显示,Mistral 7B‑Instruct 判断 84.83% 的句子得到其引用支持。附录 C.3 对不被支持的句子进行了进一步分析,发现主要问题来自不恰当的推断连接与不准确的改写,而非凭空捏造不存在的内容。
5.2 消融研究
| 方法 | 平均唯一参考数 $|\mathcal{R}|$ |
|---|---|
| STORM | 99.83 |
| 去除视角(w/o Perspective) | 54.36 |
| 去除对话(w/o Conversation) | 39.56 |
表 5:不同方法收集到的平均唯一参考资料数量($|\mathcal{R}|$)。
如第 3 节所述,STORM 通过发现特定视角并模拟多轮对话来促使 LLM 提出更有效的问题。我们在“大纲创建”上进行消融研究,将完整 STORM 与两个变体对比:(1) “STORM w/o Perspective”,在问题生成提示中省略视角;(2) “STORM w/o Conversation”,一次性生成固定数量的问题而不进行多轮对话。为保证公平,我们控制三种变体的总提问数量相同。表 3 给出结果:完整 STORM 的大纲召回率最高;而“去除对话”的结果显著更差,说明在生成有效问题之前阅读并吸收相关信息至关重要。
我们还检查不同变体在 $\mathcal{R}$ 中收集到的唯一来源数量。表 5 显示,完整流水线能够发现更多不同来源,且这一趋势与大纲质量的自动指标一致。
我们也验证了 STORM 是否必须包含“大纲阶段”。表 2 中 “STORM(去除大纲阶段)” 表示在给定主题与模拟对话的情况下直接生成整篇文章。移除大纲阶段会在几乎所有指标上显著恶化性能。
6. 人类评估
| 指标 | oRAG 平均 | oRAG ≥4 占比 | STORM 平均 | STORM ≥4 占比 | $p$ 值 |
|---|---|---|---|---|---|
| 兴趣度 | 3.63 | 57.5% | 4.03 | 70.0% | 0.077 |
| 组织性 | 3.25 | 45.0% | 4.00 | 70.0% | 0.005 |
| 相关性 | 3.93 | 62.5% | 4.15 | 65.0% | 0.347 |
| 覆盖度 | 3.58 | 57.5% | 4.00 | 67.5% | 0.084 |
| 可核查性 | 3.85 | 67.5% | 3.80 | 67.5% | 0.843 |
| 偏好次数(#Preferred) | 14 | 26 | — | ||
表 6:在 20 对文章上对 STORM 与 oRAG 的人类评估结果。每对文章由两位维基百科编辑评审。评分采用 1–7 分制(≥4 视为较好质量;评分细则见附录 D 的表 10)。我们进行配对 $t$ 检验并报告 $p$ 值。
为更好理解 STORM 的优势与不足,我们与 10 位经验丰富的维基百科编辑合作开展人类评估:他们在维基百科上至少完成 500 次编辑并具有 1 年以上经验。我们从数据集中随机抽取 20 个主题,对比 STORM 与自动评估中表现最佳的基线 oRAG(见第 4 节)。每对文章分配给 2 位编辑评审。
我们要求编辑按与自动评估相同的五个方面(见第 4.2 节)对文章进行评分,但使用 1–7 分制以获得更细粒度判断。与自动评估使用“引用质量”作为可核查性的代理不同,在人类评估中我们遵循维基百科标准“可核查且不含原创研究(verifiable with no original research)”。除评分外,编辑还需提供开放式反馈与两两偏好。在评审结束后,我们进一步请编辑将其刚评审的一篇 STORM 文章与对应的人类维基百科文章对比,并用 1–5 的李克特量表报告其对 STORM 的主观有用性评价。更多细节见附录 D。注:对 1–7 分制评分,我们计算 Krippendorff’s Alpha 以衡量标注一致性,分别为:兴趣度 0.349、组织性 0.221、相关性 0.256、覆盖度 0.346、可核查性 0.388。
STORM 生成文章在广度与深度上优于 oRAG。与第 5.1 节一致,编辑认为 STORM 生成文章在兴趣度、组织性与覆盖度上普遍优于 oRAG。具体而言,STORM 在“组织性”上被判为 ≥4 的文章多 25 个百分点,在“覆盖度”上被判为 ≥4 的文章多 10 个百分点。甚至在与人类文章对比时,一位编辑称 STORM 输出“提供了更多背景信息”,另一位指出“AI 文章比维基百科文章更有深度”。在两两偏好上,STORM 也优于最佳基线。
更大的 $|\mathcal{R}|$ 会带来超越事实性幻觉的挑战。我们分析了 14 份“编辑更偏好 oRAG”的两两比较反馈。排除其中 3 例偏好与评分不一致的情况后,我们发现编辑在超过一半的案例中给 STORM 文章打出更低的“可核查性”分数。结合文章与自由文本反馈,我们发现低可核查性往往源于“红鲱鱼谬误(red herring fallacy)”或“过度推断(overspeculation)”:生成文章在 $\mathcal{R}$ 的不同信息片段之间,或在信息与主题之间引入了不可核查的关联(示例见附录 E 的表 11)。与广泛讨论的事实性幻觉问题[54,17]相比,此类可核查性问题更为微妙,超出了基础事实核验的范畴[33]。
生成文章仍落后于经充分修订的人类作品。尽管 STORM 超过了 oRAG 基线,编辑指出生成文章仍“没有真实维基百科页面那么信息充分”。另一个主要问题是“互联网来源的偏见与语气迁移到生成文章中”:10 位编辑中有 7 位提到 STORM 生成文章听起来“情绪化”或“不够中立”。更深入分析见附录 E。这表明,在写作前阶段降低检索偏见是未来值得投入的方向。
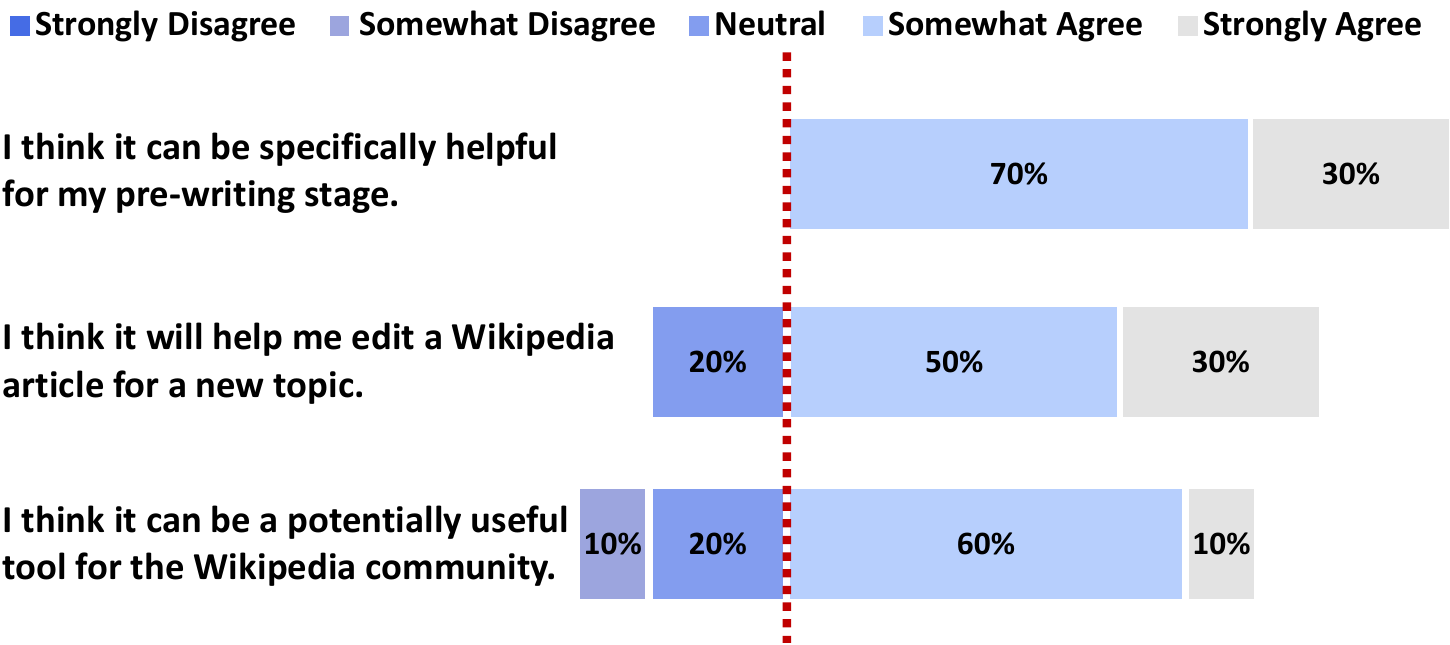
生成文章可以作为良好的起点。如图 3 所示,编辑一致认为 STORM 能帮助其写作前阶段。80% 的编辑认为 STORM 可以帮助他们为新主题编辑维基百科文章。对于其对整个维基百科社区的价值,编辑表达更谨慎:尽管如此,仍有 70% 认为其有用,仅 10% 表示不同意。
8. 结论
我们提出 STORM,一个基于大语言模型的写作系统,用于自动化从零撰写类维基百科文章的写作前阶段。我们构建 FreshWiki 数据集,并建立评估标准,以研究可溯源(grounded)的长篇文章生成。实验结果表明,STORM 的提问机制能够同时提升生成大纲与最终文章的质量。
随着覆盖面与深度的提升,STORM 也在专家评估中暴露出“有依据”写作系统面临的新挑战。参与研究的资深维基百科编辑一致认为,STORM 对他们的写作前阶段具有帮助。
局限性
本工作旨在通过从零生成类维基百科文章,推动自动化说明性写作与长篇文章生成的前沿。尽管我们的方法在自动与人工评估中都显著优于基线方法,但机器写作的质量仍落后于经过充分修订的人类文章,尤其在中立性与可核查性方面。尽管 STORM 在研究给定主题时能够发现不同视角,但其收集的信息仍可能偏向互联网中的主流来源,并可能包含宣传性内容。此外,本工作识别到的可核查性问题并不仅仅是事实性幻觉,这凸显了“有依据”写作系统面临的新挑战。
另一项局限在于,虽然我们聚焦从零生成类维基百科文章,但任务设定仍被简化为仅生成自由文本。人类撰写的高质量维基百科文章通常包含结构化数据与多模态信息。我们将生成多模态、可溯源文章的探索留待未来工作。
致谢
我们感谢 You.com 慷慨提供用于支持实验的搜索 API。我们也感谢 Sina J. Semnani、Shicheng Liu、Eric Zelikman 提供的宝贵反馈,并感谢 ACL ARR 审稿人提出的有益意见。本研究部分由 Verdant Foundation 和 Microsoft Azure AI credits 资助。Yijia Shao 得到 Stanford School of Engineering Fellowship 的支持。
伦理声明
与创意生成不同,有依据的文章生成可能影响人们学习主题的方式或对来源信息的消费方式。为防止错误信息传播,我们在本工作中的所有研究与评估设计都采取了措施:不将生成内容发布到互联网上,并实施严格的准确性检查。我们的系统不会与维基百科或相关社区的在线页面交互,从而避免对其造成任何干扰。此外,尽管我们尝试生成可溯源文章,我们认为本工作不存在隐私问题,因为我们仅使用互联网上公开可得的信息。
本工作最大的风险在于:系统生成的维基百科文章以互联网上的信息为依据,而这些信息本身可能包含偏见或歧视性内容。目前,我们的系统依赖搜索引擎进行信息检索,但尚未包含任何后处理模块。我们认为,提升检索模块以更好覆盖不同观点,并在现有系统中加入内容筛选模块,是实现更高程度中立性与平衡性的关键下一步。
从伦理角度看,我们也注意到另一项局限:本工作只考虑撰写英文维基百科文章。将当前系统扩展到多语言场景是未来一个重要方向,因为许多主题在非英语语言中并没有对应的维基百科页面。
参考文献
- Sweta Agrawal, Chunting Zhou, Mike Lewis, Luke Zettlemoyer, and Marjan Ghazvininejad. 2023. In-context examples selection for machine translation. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8857–8873, Toronto, Canada. Association for Computational Linguistics.
- Alan Akbik, Tanja Bergmann, Duncan Blythe, Kashif Rasul, Stefan Schweter, and Roland Vollgraf. 2019. FLAIR: An easy-to-use framework for state-of-the-art NLP. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), pages 54–59, Minneapolis, Minnesota. Association for Computational Linguistics.
- Mohammad Aliannejadi, Hamed Zamani, Fabio Crestani, and W Bruce Croft. 2019. Asking clarifying questions in open-domain information-seeking conversations. In Proceedings of the 42nd international acm sigir conference on research and development in information retrieval, pages 475–484.
- Nishant Balepur, Jie Huang, and Kevin Chang. 2023. Expository text generation: Imitate, retrieve, paraphrase. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11896–11919, Singapore. Association for Computational Linguistics.
- Siddhartha Banerjee and Prasenjit Mitra. 2015. WikiKreator: Improving Wikipedia stubs automatically. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 867–877, Beijing, China. Association for Computational Linguistics.
- Bernd Bohnet, Vinh Q. Tran, Pat Verga, Roee Aharoni, Daniel Andor, Livio Baldini Soares, Massimiliano Ciaramita, Jacob Eisenstein, Kuzman Ganchev, Jonathan Herzig, Kai Hui, Tom Kwiatkowski, Ji Ma, Jianmo Ni, Lierni Sestorain Saralegui, Tal Schuster, William W. Cohen, Michael Collins, Dipanjan Das, Donald Metzler, Slav Petrov, and Kellie Webster. 2023. Attributed question answering: Evaluation and modeling for attributed large language models.
- Wayne C Booth, Gregory G Colomb, and Joseph M Williams. 2003. The craft of research. University of Chicago press.
- Laura Dietz and John Foley. 2019. Trec car y3: Complex answer retrieval overview. In Proceedings of Text REtrieval Conference (TREC).
- Christina S Doyle. 1994. Information literacy in an information society: A concept for the information age. Diane Publishing.
- Ann-Marie Eriksson and Åsa Mäkitalo. 2015. Supervision at the outline stage: Introducing and encountering issues of sustainable development through academic writing assignments. Text & Talk, 35(2):123–153.
- Angela Fan and Claire Gardent. 2022. Generating biographies on Wikipedia: The impact of gender bias on the retrieval-based generation of women biographies. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8561–8576, Dublin, Ireland. Association for Computational Linguistics.
- Xiaocheng Feng, Ming Liu, Jiahao Liu, Bing Qin, Yibo Sun, and Ting Liu. 2018. Topic-to-essay generation with neural networks. In IJCAI, pages 4078–4084.
- Tira Nur Fitria. 2023. Artificial intelligence (ai) technology in openai chatgpt application: A review of chatgpt in writing english essay. In ELT Forum: Journal of English Language Teaching, volume 12, pages 44–58.
- Pasi Fränti and Radu Mariescu-Istodor. 2023. Soft precision and recall. Pattern Recognition Letters, 167:115–121.
- R Edward Freeman, Jeffrey S Harrison, Andrew C Wicks, Bidhan L Parmar, and Simone De Colle. 2010. Stakeholder theory: The state of the art.
- Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling large language models to generate text with citations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6465–6488, Singapore. Association for Computational Linguistics.
- Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2023. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.
- Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research, 24(251):1–43.
- Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023a. Mistral 7b. arXiv preprint arXiv:2310.06825.
- Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023b. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969–7992, Singapore. Association for Computational Linguistics.
- Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. 2023. Large language models struggle to learn long-tail knowledge. In International Conference on Machine Learning, pages 15696–15707. PMLR.
- Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. 2022. Demonstrate-search-predict: Composing retrieval and language models for knowledge-intensive NLP. arXiv preprint arXiv:2212.14024.
- Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714.
- Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. 2023. Prometheus: Inducing fine-grained evaluation capability in language models. arXiv preprint arXiv:2310.08491.
- Mojtaba Komeili, Kurt Shuster, and Jason Weston. 2022. Internet-augmented dialogue generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8460–8478, Dublin, Ireland. Association for Computational Linguistics.
- Kalpesh Krishna, Erin Bransom, Bailey Kuehl, Mohit Iyyer, Pradeep Dasigi, Arman Cohan, and Kyle Lo. 2023. LongEval: Guidelines for human evaluation of faithfulness in long-form summarization. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 1650–1669, Dubrovnik, Croatia. Association for Computational Linguistics.
- Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
- Xiaonan Li, Kai Lv, Hang Yan, Tianyang Lin, Wei Zhu, Yuan Ni, Guotong Xie, Xiaoling Wang, and Xipeng Qiu. 2023. Unified demonstration retriever for in-context learning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4644–4668, Toronto, Canada. Association for Computational Linguistics.
- Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2022. What makes good in-context examples for GPT-3? In Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, pages 100–114, Dublin, Ireland and Online. Association for Computational Linguistics.
- Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. 2018. Generating wikipedia by summarizing long sequences. In International Conference on Learning Representations.
- Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, and Nat McAleese. 2022. Teaching language models to support answers with verified quotes.
- Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, Singapore. Association for Computational Linguistics.
- Julià Minguillón, Maura Lerga, Eduard Aibar, Josep Lladós-Masllorens, and Antoni Meseguer-Artola. 2017. Semi-automatic generation of a corpus of wikipedia articles on science and technology. Profesional de la Información, 26(5):995–1005.
- Rosa Munoz-Luna. 2015. Main ingredients for success in l2 academic writing: Outlining, drafting and proofreading. PloS one, 10(6):e0128309.
- Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. 2022. Webgpt: Browser-assisted question-answering with human feedback.
- Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Aaron Parisi, Yao Zhao, and Noah Fiedel. 2022. Talm: Tool augmented language models.
- John V Pavlik. 2023. Collaborating with chatgpt: Considering the implications of generative artificial intelligence for journalism and media education. Journalism & Mass Communication Educator, 78(1):84–93.
- Gabriel Poesia, Alex Polozov, Vu Le, Ashish Tiwari, Gustavo Soares, Christopher Meek, and Sumit Gulwani. 2022. Synchromesh: Reliable code generation from pre-trained language models. In International Conference on Learning Representations.
- Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. 2023. Measuring and narrowing the compositionality gap in language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, Singapore. Association for Computational Linguistics.
- Peng Qi, Yuhao Zhang, and Christopher D. Manning. 2020. Stay hungry, stay focused: Generating informative and specific questions in information-seeking conversations. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 25–40, Online. Association for Computational Linguistics.
- Hongjing Qian, Yutao Zhu, Zhicheng Dou, Haoqi Gu, Xinyu Zhang, Zheng Liu, Ruofei Lai, Zhao Cao, Jian-Yun Nie, and Ji-Rong Wen. 2023. Webbrain: Learning to generate factually correct articles for queries by grounding on large web corpus.
- Hossein A. Rahmani, Xi Wang, Yue Feng, Qiang Zhang, Emine Yilmaz, and Aldo Lipani. 2023. A survey on asking clarification questions datasets in conversational systems. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2698–2716, Toronto, Canada. Association for Computational Linguistics.
- Ashwin Ram. 1991. A theory of questions and question asking. Journal of the Learning Sciences, 1(3-4):273–318.
- Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-context retrieval-augmented language models. Transactions of the Association for Computational Linguistics.
- Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
- D Gordon Rohman. 1965. Pre-writing the stage of discovery in the writing process. College composition and communication, 16(2):106–112.
- Christina Sauper and Regina Barzilay. 2009. Automatically generating Wikipedia articles: A structure-aware approach. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, pages 208–216, Suntec, Singapore. Association for Computational Linguistics.
- Sina Semnani, Violet Yao, Heidi Zhang, and Monica Lam. 2023. WikiChat: Stopping the hallucination of large language model chatbots by few-shot grounding on Wikipedia. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 2387–2413, Singapore. Association for Computational Linguistics.
- Zejiang Shen, Tal August, Pao Siangliulue, Kyle Lo, Jonathan Bragg, Jeff Hammerbacher, Doug Downey, Joseph Chee Chang, and David Sontag. 2023. Beyond summarization: Designing ai support for real-world expository writing tasks.
- Weijia Shi, Julian Michael, Suchin Gururangan, and Luke Zettlemoyer. 2022. Nearest neighbor zero-shot inference. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3254–3265, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Kurt Shuster, Mojtaba Komeili, Leonard Adolphs, Stephen Roller, Arthur Szlam, and Jason Weston. 2022. Language models that seek for knowledge: Modular search & generation for dialogue and prompt completion. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 373–393, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. 2021. Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3784–3803, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Christine M Tardy. 2010. Writing for the world: Wikipedia as an introduction to academic writing. In English teaching forum, volume 48, page 12. ERIC.
- Andrew A Tawfik, Arthur Graesser, Jessica Gatewood, and Jaclyn Gishbaugher. 2020. Role of questions in inquiry-based instruction: towards a design taxonomy for question-asking and implications for design. Educational Technology Research and Development, 68:653–678.
- Charles A Weaver III and Walter Kintsch. 1991. Expository text.
- Karsten Wenzlaff and Sebastian Spaeth. 2022. Smarter than humans? validating how openai’s chatgpt model explains crowdfunding, alternative finance and community finance. Validating how OpenAI’s ChatGPT model explains Crowdfunding, Alternative Finance and Community Finance.(December 22, 2022).
- Fangyuan Xu, Yixiao Song, Mohit Iyyer, and Eunsol Choi. 2023. A critical evaluation of evaluations for long-form question answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3225–3245, Toronto, Canada. Association for Computational Linguistics.
- Kevin Yang, Dan Klein, Nanyun Peng, and Yuandong Tian. 2023. DOC: Improving long story coherence with detailed outline control. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3378–3465, Toronto, Canada. Association for Computational Linguistics.
- Kevin Yang, Yuandong Tian, Nanyun Peng, and Dan Klein. 2022. Re3: Generating longer stories with recursive reprompting and revision. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 4393–4479, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations.
- Cyril Zakka, Akash Chaurasia, Rohan Shad, Alex R Dalal, Jennifer L Kim, Michael Moor, Kevin Alexander, Euan Ashley, Jack Boyd, Kathleen Boyd, et al. 2023. Almanac: Retrieval-augmented language models for clinical medicine. Research Square.
- Shuyan Zhou, Uri Alon, Frank F. Xu, Zhengbao Jiang, and Graham Neubig. 2023. Docprompting: Generating code by retrieving the docs. In The Eleventh International Conference on Learning Representations.
附录
本附录补充 FreshWiki 数据集的构建细节、STORM 的伪代码与提示词、自动评估实现细节、人类评估流程,以及对生成文章的错误分析与示例输出。
A. 数据集细节
如第 2.1 节所述,我们通过收集“近期”且“高质量”的英文维基百科文章来构建 FreshWiki 数据集。我们在某一时间窗口内选择编辑次数最多的页面,而不是用创建日期作为截断阈值,因为大多数维基百科文章在创建之初都只是“短小条目”(stub)或质量较低。就质量而言,我们筛选被预测为 B 级或更高质量的文章。根据维基百科统计数据(https://en.wikipedia.org/wiki/Wikipedia:Content_assessment),现有维基百科页面中只有约 3% 能达到这一质量标准。考虑到 LLM 已能够生成相当不错的输出,我们认为在进一步研究中使用高质量的人类撰写文章作为参考尤为重要。
| 指标 | 数值 |
|---|---|
| 平均章节数 | 8.4 |
| 平均(所有层级)标题数 | 15.8 |
| 平均单节长度 | 327.8 |
| 平均全文长度 | 2159.1 |
| 平均参考资料数量 | 90.1 |
表 7:本文实验所用数据集的统计信息。
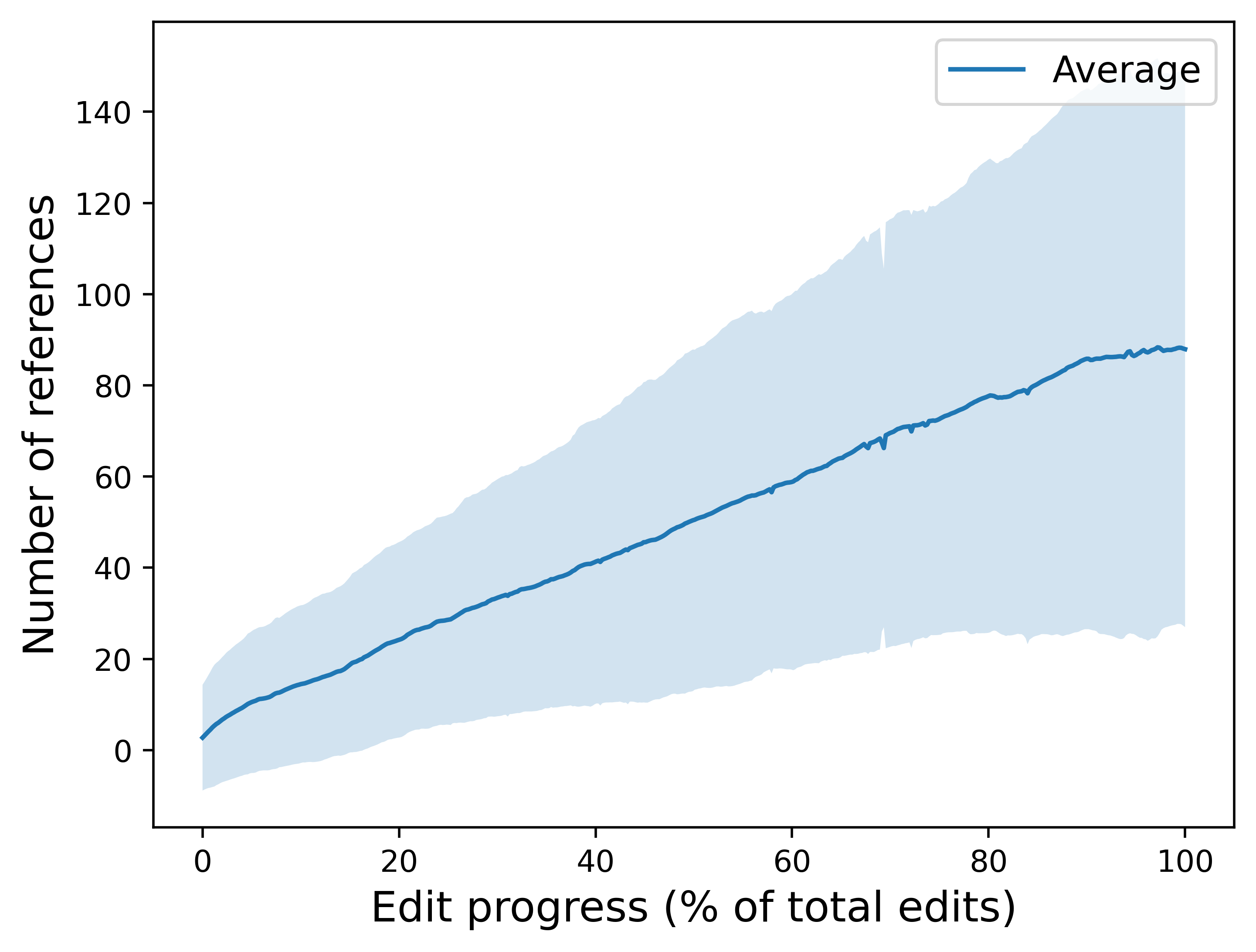
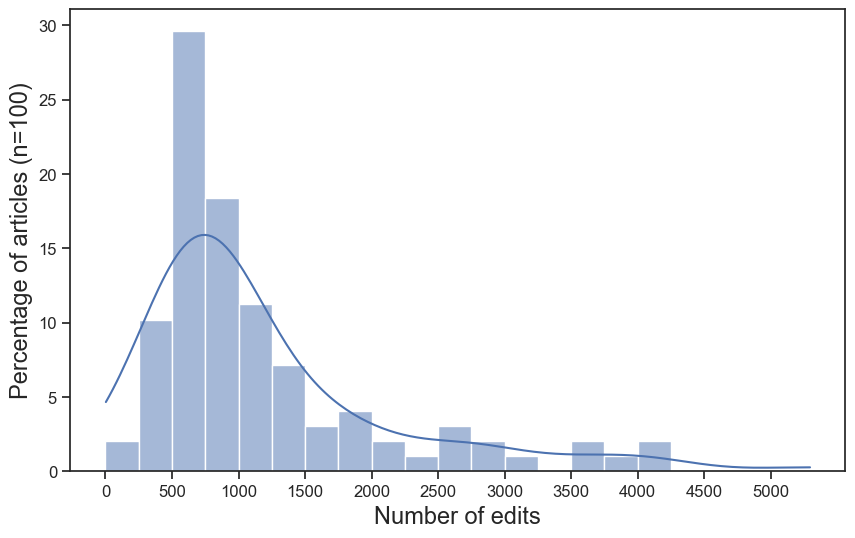
在本文实验中,为了进行更有意义的对比,我们随机选取 100 个样本,其对应的人类撰写文章长度均小于 3000 词。表 7 给出了数据统计。值得注意的是,人类撰写文章通常包含大量参考资料,但要达到这种引用规模往往需要经历大量编辑迭代。图 4 展示了文章编辑过程中的引用数量变化趋势,而图 5 展示了实验所用人类文章的编辑次数分布。
B. STORM 伪代码
在第 3 节中,我们介绍 STORM:一个通过发现不同视角、模拟信息寻求对话并创建全面大纲来自动化写作前阶段的框架。算法 1 展示了 STORM 的整体流程骨架。
我们使用 DSPy 框架[23] 以零样本提示(zero-shot prompting)实现 STORM。清单 1 与清单 2 展示了我们实现中使用的提示词。我们强调,STORM 提供的是一个通用框架,旨在辅助创建可溯源(grounded)的长篇文章,而不是依赖针对单一领域的大量提示工程。
输入:主题 t,最大视角数 N,最大对话轮数 M
输出:大纲 O,参考资料 R
P0 = "basic fact writer ..." # 常量
R ← [ ]
# 发现视角 P
related_topics ← gen_related_topics(t)
tocs ← [ ]
for related_t in related_topics:
article ← get_wiki_article(related_t)
if article:
tocs.append(extract_toc(article))
P ← gen_perspectives(t, tocs)
P ← [P0] + P[:N]
# 模拟对话
convos ← [ ]
for p in P:
convo_history ← [ ]
for i = 1 to M:
# 提问
q ← gen_qn(t, p, dlg_history)
convo_history.append(q)
# 回答
queries ← gen_queries(t, q)
sources ← search_and_sift(queries)
a ← gen_ans(t, q, sources)
convo_history.append(a)
R.append(sources)
convos.append(convo_history)
# 创建大纲
O_D ← direct_gen_outline(t)
O ← refine_outline(t, O_D, convos)
返回 O, R算法 1:STORM 的伪代码骨架。
class GenRelatedTopicsPrompt(dspy.Signature):
"""
我正在为下面提到的主题撰写一个维基百科页面。请识别并推荐一些与之密切相关的维基百科页面。
我希望这些例子能够揭示该主题常见的有趣侧面,或帮助我理解相似主题的维基百科页面通常包含的内容与结构。
请将 URL 分行列出。
"""
topic = dspy.InputField(prefix="感兴趣的主题:", format=str)
related_topics = dspy.OutputField()
class GenPerspectivesPrompt(dspy.Signature):
"""
你需要选择一组维基百科编辑协同创作该主题的综合性文章。每位编辑都代表与该主题相关的不同视角、角色或关联身份。
你可以参考相关主题的其他维基百科页面获取灵感。请为每位编辑补充其关注重点的描述。
请按如下格式作答:1. 编辑 1 的简短概述:描述\\n2. 编辑 2 的简短概述:描述\\n...
"""
topic = dspy.InputField(prefix="感兴趣的主题:", format=str)
examples = dspy.InputField(prefix="相关主题的维基页面大纲(供启发):\\n", format=str)
perspectives = dspy.OutputField()
class GenQnPrompt(dspy.Signature):
"""
你是一名经验丰富的维基百科写作者,正准备编辑某个特定页面。除“维基百科写作者”这一身份外,你在研究该主题时还有一个特定关注点。
现在,你正在与一位专家聊天以获取信息。请提出高质量问题,以获得更有用的信息。
当你没有更多问题要问时,说出 "Thank you so much for your help!" 来结束对话。
请一次只问一个问题,不要重复你之前问过的问题。你的问题应与要撰写的主题相关。
"""
topic = dspy.InputField(prefix="你想写的主题:", format=str)
persona = dspy.InputField(prefix="你的具体视角:", format=str)
conv = dspy.InputField(prefix="对话历史:\\n", format=str)
question = dspy.OutputField()
class GenQueriesPrompt(dspy.Signature):
"""
你希望使用 Google 搜索来回答该问题。你会在搜索框里输入什么?
请按以下格式写出你将使用的查询:- 查询 1\\n- 查询 2\\n...
"""
topic = dspy.InputField(prefix="你正在讨论的主题:", format=str)
question = dspy.InputField(prefix="你要回答的问题:", format=str)
queries = dspy.OutputField()清单 1:STORM 使用的提示词,对应算法 1 的第 4、11、19、22 行。
class GenAnswerPrompt(dspy.Signature):
"""
你是一位能够有效利用信息的专家。你正在与一位想就其了解的主题撰写维基百科页面的写作者对话。
你已经收集到相关信息,现在将利用这些信息形成回复。
请让回复尽可能信息丰富,并确保每一句话都有已收集信息的支撑。
"""
topic = dspy.InputField(prefix="你正在讨论的主题:", format=str)
conv = dspy.InputField(prefix="问题:\\n", format=str)
info = dspy.InputField(prefix="已收集信息:\\n", format=str)
answer = dspy.OutputField(prefix="现在给出你的回复:\\n")
class DirectGenOutlinePrompt(dspy.Signature):
"""
为一个维基百科页面撰写大纲。
写作格式如下:
1. 使用 "# 标题" 表示一级章节标题,使用 "## 标题" 表示二级小节标题,使用 "### 标题" 表示三级小节标题,依此类推。
2. 不要包含任何其他信息。
"""
topic = dspy.InputField(prefix="你想写的主题: ", format=str)
outline = dspy.OutputField(prefix="请写出维基百科页面大纲:\\n")
class RefineOutlinePrompt(dspy.Signature):
"""
改进一个维基百科页面的大纲。你已经有一个覆盖一般信息的草稿大纲;现在你希望基于信息寻求型对话中学到的信息来提升它,使其更全面。
写作格式如下:
1. 使用 "# 标题" 表示一级章节标题,使用 "## 标题" 表示二级小节标题,使用 "### 标题" 表示三级小节标题,依此类推。
2. 不要包含任何其他信息。
"""
topic = dspy.InputField(prefix="你想写的主题: ", format=str)
conv = dspy.InputField(prefix="对话历史:\\n", format=str)
old_outline = dspy.OutputField(prefix="当前大纲:\\n", format=str)
outline = dspy.OutputField(prefix="请写出维基百科页面大纲:\\n")清单 2:STORM 使用的提示词(续),对应算法 1 的第 24、31、32 行。
C. 自动评估细节
C.1 软标题召回(Soft Heading Recall)
我们计算生成大纲中的多层级标题(视为预测 $P$)与人类撰写文章中的多层级标题(视为真实 $G$)之间的软标题召回(soft heading recall)。该计算基于 Fränti 与 Mariescu‑Istodor 提出的软召回定义[14]。给定集合 $A=\{A_i\}_{i=1}^{K}$,某个条目的“软计数”(soft count)定义为其与集合内其他条目的相似度之和的倒数:
$$\begin{aligned} \operatorname{count}(A_i) &= \frac{1}{\sum_{j=1}^{K} \operatorname{Sim}(A_i, A_j)} \\ \operatorname{Sim}(A_i, A_j) &= \cos(\operatorname{embed}(A_i), \operatorname{embed}(A_j)) \end{aligned}$$
其中,$\operatorname{embed}(\cdot)$ 由 Sentence‑Transformers 库提供的 paraphrase‑MiniLM‑L6‑v2 参数化(链接:https://huggingface.co/sentence-transformers/paraphrase-MiniLM-L6-v2)。集合 $A$ 的“基数”(cardinality)定义为其各条目软计数之和:
$$\operatorname{card}(A)=\sum_{i=1}^{K}\operatorname{count}(A_i)$$
软标题召回定义为:
$$\textit{soft heading recall}=\frac{\operatorname{card}(G \cap P)}{\operatorname{card}(G)}$$
其中,交集的基数通过并集来定义:
$$\operatorname{card}(G \cap P)=\operatorname{card}(G)+\operatorname{card}(P)-\operatorname{card}(G \cup P)$$
C.2 LLM 评估器
| 维度 | 分数 | 说明 |
|---|---|---|
| 兴趣度(Interest Level) | 1 | 完全不吸引人;没有任何试图抓住读者注意力的努力。 |
| 2 | 较为吸引人,但仅有基本叙事且缺乏深度。 | |
| 3 | 中等吸引力;包含若干有趣要点。 | |
| 4 | 相当吸引人;叙事结构良好,且有值得关注的要点,能频繁抓住并保持注意力。 | |
| 5 | 全程极具吸引力;叙事引人入胜,持续激发兴趣。 | |
| 连贯性与组织(Coherence and Organization) | 1 | 组织混乱;缺乏逻辑结构与连贯性。 |
| 2 | 组织尚可;有基本结构,但未能始终一致地遵循。 | |
| 3 | 组织良好;大体遵循清晰结构,但偶有连贯性断裂。 | |
| 4 | 组织较好;结构清晰,仅有少量连贯性瑕疵。 | |
| 5 | 组织极佳;文章逻辑结构严密、过渡无缝且论述清晰。 | |
| 相关性与聚焦(Relevance and Focus) | 1 | 跑题;内容与标题或核心主题不一致。 |
| 2 | 一定程度相关,但偏题较多;核心主题可见,但未能始终保持聚焦。 | |
| 3 | 总体围绕主题,但包含少量不相关细节。 | |
| 4 | 大体聚焦且围绕主题;叙述与核心主题持续相关,偏题较少。 | |
| 5 | 高度聚焦且完全围绕主题;每一条信息都服务于对主题的全面理解。 | |
| 覆盖广度(Broad Coverage) | 1 | 严重不足;几乎没有覆盖主题的主要方面,导致视角非常狭窄。 |
| 2 | 覆盖不完整;包含部分主要方面但遗漏其他内容,导致呈现不充分。 | |
| 3 | 广度尚可;覆盖多数主要方面,但可能偏向一些不必要的次要细节或遗漏部分相关点。 | |
| 4 | 覆盖良好;广泛覆盖主题并触及所有关键要点,同时冗余信息较少。 | |
| 5 | 覆盖极佳;在不引入无关信息的前提下,全面而充分地呈现主题的所有关键方面。 |
表 8:用于评估器 LLM 的 1–5 分制评分细则。
我们使用 Prometheus(链接:https://huggingface.co/kaist-ai/prometheus-13b-v1.0)[24]——一个 13B 的开源评估器 LLM,可根据自定义的 1–5 分制细则对长文本进行评估——从 兴趣度、连贯性与组织、相关性与聚焦、覆盖广度 等方面对文章打分。表 8 给出了评分细则。Prometheus 最佳用法是在输入中提供一个“5 分参考答案”,但我们发现加入参考答案会超过模型上下文长度限制。鉴于 Kim 等人[24] 表明在不提供参考答案的条件下 Prometheus 的评分仍与人类偏好高度相关,我们省略参考答案,并将输入文章裁剪到 2000 词以内:通过迭代地从最短章节中移除内容来控制长度,确保输入能够适配模型的上下文窗口。
C.3 关于引用质量的更多讨论
| 错误类型 | 主题 | 不被支持的句子 | 来源 |
|---|---|---|---|
| 不恰当的推断连接(Improper Inferential Linking) | Lahaina, Hawaii | 纵观其历史,宗教一直是夏威夷生活中至关重要的方面,在 Lahaina 亦是如此,渗透到每一项日常活动和重大事件之中[5]。 | [5] “Religion, Beliefs & Spirituality” (该来源讨论宗教作为夏威夷生活的一部分,但并未提到 Lahaina。) |
| 不准确的改写(Inaccurate Paraphrasing) | 2022 Crimean Bridge explosion | 于 2020 年 6 月竣工,该桥是俄罗斯军队在该地区的重要补给路线,并对俄罗斯对争议领土的主张具有重要意义[2][11]。 | [2] “Crimean Bridge - Wikipedia” (来源写道:“第一列按时刻表运行的客运列车于 2019 年 12 月 25 日穿越大桥,而该桥于 2020 年 6 月 30 日向货运列车开放。”) |
| 引用无关来源(Citing Irrelevant Sources) | LK-99 | 例如,有人将 LK-9 的性能与《Battlefield 2042》等电子游戏的动态分辨率能力进行类比[22]。 | [22] “Battlefield 2042 PC performance guide: The best settings for a high frame rate” (该来源与 LK‑99 无关。) |
表 9:“不被引用支持”句子的不同错误类型示例。
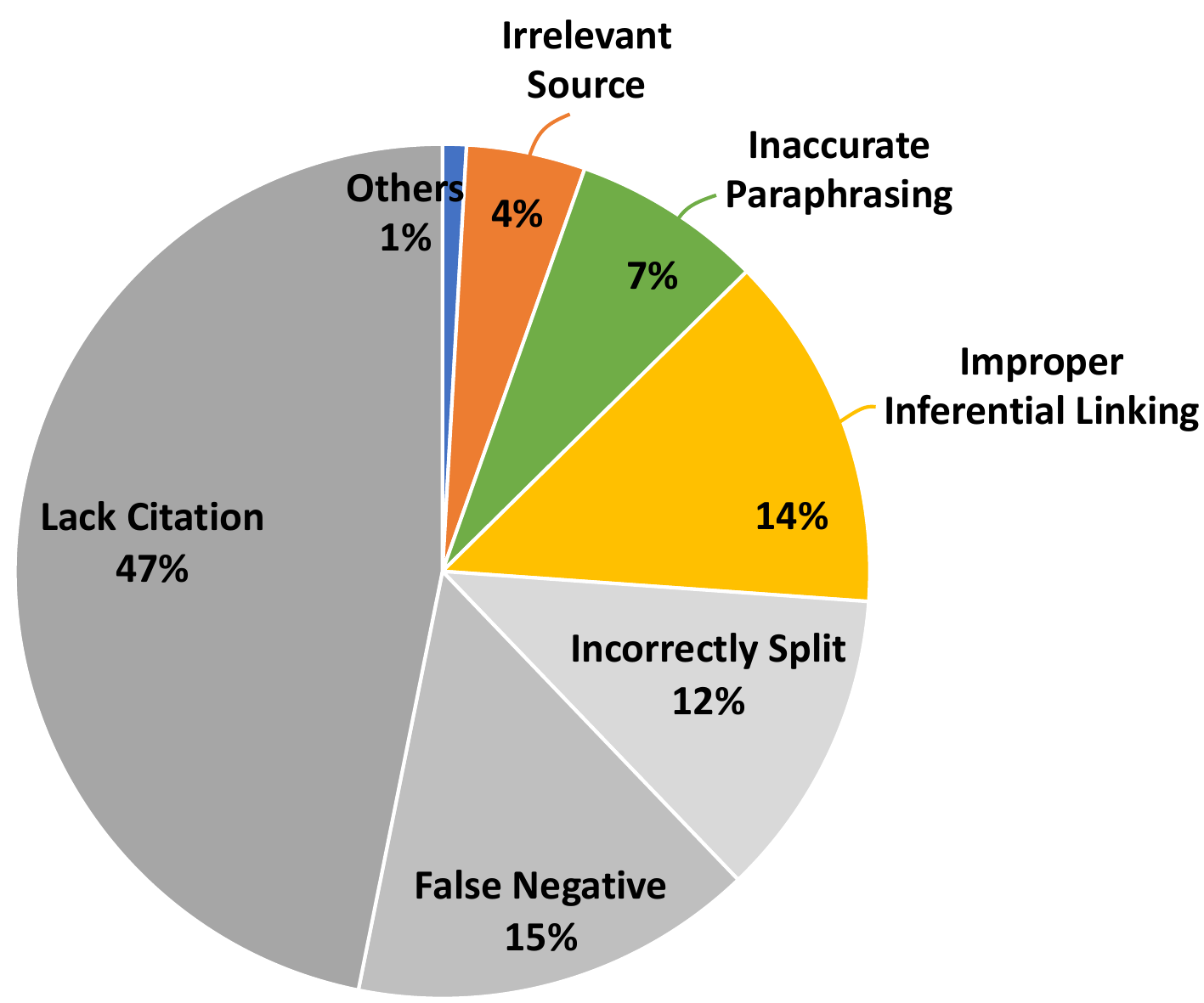
我们使用 Mistral 7B‑Instruct(链接:https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)[19] 来检查“被引用段落是否蕴含(entail)生成句子”。表 4 报告了本文方法生成文章的引用质量:约 15% 的句子不被其引用支持。我们进一步对失败案例进行分析:随机抽取 10 篇文章,由作者人工检查其中所有“不被支持”的句子。除去以下情况——(1) 被错误切分的句子(遵循 Gao 等人[16] 的做法,我们在句子级别检查引用质量,并使用 NLTK 的 sent_tokenize 将文章切分为句子;当文章包含诸如 “No.12847”“Bhatia et al.” 等特殊词形时,sent_tokenize 有时会切分失败);(2) 缺少引用;(3) 基于作者判断应视为“被支持”——我们的分析识别出三类主要错误(示例见表 9):不恰当的推断连接、不准确的改写、以及 引用无关来源。
图 6 展示了错误分布。值得注意的是,最常见的错误来自 LLM 倾向于在上下文窗口中不同信息片段之间建立不恰当的推断联系。我们的引用质量分析表明,除了避免幻觉之外,未来“有依据”的文本生成研究还应关注:如何防止 LLM 基于给定信息作出过度推断的“跳跃”。
D. 人类评估细节
我们通过在 Meta‑Wiki 上创建研究页面(https://meta.wikimedia.org),并联系近期曾批准维基百科条目的活跃编辑,招募了 10 位经验丰富的维基百科编辑参与研究。鉴于评估类维基百科文章耗时且需要专业知识,我们为每位参与者支付 50 美元。参与者中,3 人具有 1–5 年经验、4 人具有 6–10 年经验、3 人具有超过 15 年的贡献年限。本研究通过了所在机构的伦理审查(IRB),参与者在研究开始前通过 Qualtrics 问卷签署了知情同意书。
为简化对可溯源文章的评估,我们开发了一个网页应用:将文章正文与其对应的引用片段并排展示,以收集每篇文章的评分与开放式反馈。图 7 展示了该网页应用的截图;STORM 生成的完整文章示例见表 12。人类评估采用 1–7 分制以获得更细粒度的区分,评分细则见表 10。
我们还通过在线问卷收集了两两偏好与对 STORM “有用性”的主观评价。具体而言,在“有用性”维度上,我们要求编辑对以下陈述的同意程度进行评分:“我认为它可以在我的写作前阶段提供具体帮助(例如收集相关来源、拟定大纲、起草)”“我认为它会帮助我为一个新主题编辑维基百科条目”“我认为它可能成为维基百科社区的有用工具”。评分使用 1–5 的李克特量表,对应:强烈不同意、较不同意、既不同意也不赞同、较赞同、强烈赞同。
| 维度 | 分数 | 说明 |
|---|---|---|
| 兴趣度(Interest Level) | 1 | 完全不吸引人;没有任何试图抓住读者注意力的努力。 |
| 2 | 略有吸引力;仅有极少数瞬间能引起注意。 | |
| 3 | 较为吸引人;有基本叙事,但缺乏深度。 | |
| 4 | 中等吸引力;包含若干有趣要点。 | |
| 5 | 相当吸引人;叙事结构良好,且有值得关注的要点,能频繁抓住并保持注意力。 | |
| 6 | 非常吸引人;叙事引人入胜,能够吸引并在大多数情况下保持注意力。 | |
| 7 | 全程极具吸引力;叙事引人入胜,持续激发兴趣。 | |
| 连贯性与组织(Coherence and Organization) | 1 | 组织混乱;缺乏逻辑结构与连贯性。 |
| 2 | 组织较差;虽能看出一些结构,但非常薄弱。 | |
| 3 | 组织尚可;有基本结构,但未能始终一致地遵循。 | |
| 4 | 组织良好;大体遵循清晰结构,但偶有连贯性断裂。 | |
| 5 | 组织较好;结构清晰,仅有少量连贯性瑕疵。 | |
| 6 | 组织非常好;结构逻辑清楚,过渡自然且能有效引导读者。 | |
| 7 | 组织极佳;文章逻辑结构严密、过渡无缝且论述清晰。 | |
| 相关性与聚焦(Relevance and Focus) | 1 | 跑题;内容与标题或核心主题不一致。 |
| 2 | 大多跑题,但包含少量相关要点。 | |
| 3 | 一定程度相关,但偏题较多;核心主题可见,但未能始终保持聚焦。 | |
| 4 | 总体围绕主题,但包含少量不相关细节。 | |
| 5 | 大体聚焦且围绕主题;叙述与核心主题持续相关,偏题较少。 | |
| 6 | 高度相关;叙事聚焦且目标明确。 | |
| 7 | 极度聚焦且完全围绕主题;每一条信息都服务于对主题的全面理解。 | |
| 覆盖广度(Broad Coverage) | 1 | 严重不足;几乎没有覆盖主题的主要方面,导致视角非常狭窄。 |
| 2 | 覆盖极少;仅涉及主题主要方面中的很小一部分,存在大量缺失。 | |
| 3 | 覆盖不完整;包含部分主要方面但遗漏其他内容,导致呈现不充分。 | |
| 4 | 广度尚可;覆盖多数主要方面,但可能偏向一些不必要的次要细节或遗漏部分相关点。 | |
| 5 | 覆盖良好;广泛覆盖主题并触及所有关键要点,同时冗余信息较少。 | |
| 6 | 覆盖全面;对主题的所有重要方面提供较为充分的覆盖,且重心较为均衡。 | |
| 7 | 覆盖极佳;在不引入无关信息的前提下,全面而充分地呈现主题的所有关键方面。 | |
| 可核查性(Verifiability) | 1 | 没有支撑性证据;主张缺乏依据。 |
| 2 | 很少有证据支撑;大量主张缺乏依据。 | |
| 3 | 核查不一致;部分主张有证据支撑,但证据提供不稳定。 | |
| 4 | 总体可核查;主张通常有证据支撑,但仍可能存在少量缺乏核查的情况。 | |
| 5 | 支撑充分;绝大多数主张都有可信证据支撑,缺乏证据的情况较少。 | |
| 6 | 支撑非常充分;几乎每一条主张都由可信证据佐证,体现出很高的核查严谨性。 | |
| 7 | 核查示范级;每一条主张都由权威来源提供的强有力证据支撑,体现对“禁止原创研究”(no original research)政策的严格遵循。 |
表 10:人类评估使用的 1–7 分制评分细则。
E. 错误分析
| 问题 | 提及次数 | 示例评论 |
|---|---|---|
| 使用情绪化措辞、缺乏中立性 | 12 |
“significant” 这个词在文章里出现了 17 次。文章对更广泛的政治重要性与“关键作用”等作出了含糊且缺乏支撑的断言,不符合百科文体。(对条目 Lahaina, Hawaii 的评论) [ … ] 但他们仍然没有解决“中立观点”的问题。这篇文章也明显带有作者偏向 Taylor Swift 的立场。除此之外,它在总结关键要点、提供一定深度方面做得不错。(对条目 Speak Now (Taylor's Version) 的评论) “这部影片也在由 The California Endowment 主办的一场艺术与电影节上展映,强调了故事在重塑社区叙事方面的力量。”是的,严格来说来源确实这么写,但用维基百科的口吻表达就显得牵强,读起来像不够中立、带宣传意味的文案。(对条目 Gehraiyaan 的评论) |
| 红鲱鱼谬误:将不相关信息强行关联 | 11 |
不应加入来自美国的民调;除非来源明确建立联系,否则也不应把它与气候变化联系起来。(对条目 Typhoon Hinnamnor 的评论) 引用整体看起来大多没问题,但有些并不直接相关(例如 39、40)。(对条目 Gehraiyaan 的评论) 这里对 KISS 有一段很长的跑题性展开,没有必要;应该直接链接到该乐队的条目。(对条目 2022 AFL Grand Final 的评论) |
| 缺失重要信息 | 6 |
“一项由劳伦斯伯克利国家实验室的物理学家 Sinéad Griffin 开展的研究,使用超级计算机模拟对 LK‑99 的能力做了一些分析[20]。”——关于分析本身的信息太少,而这本应对文章非常有价值。(对条目 LK-99 的评论) 虽然对地震的直接后果与应对措施覆盖得还算充分,但可以更多讨论长期社会经济影响与恢复过程。(对条目 2022 West Java earthquake 的评论) |
| 对时效性信息处理不当 | 5 |
维基百科文章应避免使用“now”等词以防内容过时;应改用“截至 2023 年 12 月”等表述。(对条目 Cyclone Batsirai 的评论) “as of December 13” 没有注明年份,而且已经是过时信息。(对条目 2022 West Java earthquake 的评论) |
| 章节组织问题 | 5 |
“Recovery and Rehabilitation” 小节里有太多子标题。(对条目 2022 West Java earthquake 的评论) 我不喜欢文章的组织方式:标题太多把文章“挤得很乱”,可读性变差。除此之外,AI 在这篇文章上做得很好。(对条目 2022 Crimean Bridge explosion 的评论) |
表 11:维基百科编辑指出的 STORM 生成文章的主要问题汇总。
尽管 STORM 生成的文章在自动指标与人类评估中均更受偏好,资深编辑仍识别出机器生成文章中的多类问题。我们分析开放式评论,并在表 11 中总结这些主要问题。
被提及最多的问题是:生成文章常包含情绪化语言并缺乏中立性,这主要源于所依赖的来源材料。STORM 当前从互联网检索“支撑来源”,而互联网内容本身并不总是中立的,且包含相当多宣传性信息。如何在写作前阶段缓解这种偏差,是未来研究的重要方向。另一项主要问题是红鲱鱼谬误:对不相关事实的过度关联。解决这一挑战需要更高层次的意义建构(sensemaking),而不仅仅是对事实层面的逐句核查。
展开:Taylor Hawkins 示例文章(表 12)
Taylor Hawkins
奥利弗·泰勒·霍金斯(Oliver Taylor Hawkins,1972–2022)是一位美国音乐人,最为人所知的身份是摇滚乐队 Foo Fighters 的鼓手[1]。他出生于德克萨斯州沃尔顿堡(Fort Walton),从小就热爱音乐,尤其是在 1982 年观看皇后乐队(Queen)演唱会后,这份热情被进一步点燃[2][3][5]。他以艾拉妮丝·莫莉塞特(Alanis Morissette)的巡演乐队鼓手身份开启职业生涯,并随同她为畅销专辑《Jagged Little Pill》进行世界巡演[8][9]。随后,他的才华被戴夫·格罗尔(Dave Grohl)注意到,后者在 1997 年邀请他加入 Foo Fighters,开启了他在该乐队影响深远的鼓手生涯[7][8]。
霍金斯以多变而富有表现力的鼓击风格著称,他深受罗杰·泰勒(Roger Taylor)、尼尔·皮尔特(Neil Peart)、菲尔·柯林斯(Phil Collins)、亚历克斯·范·海伦(Alex Van Halen)以及斯图尔特·科普兰(Stewart Copeland)等著名鼓手的影响[14]。他在舞台上展现出独特的能量与富有攻击性的演奏方式,使其被视为同代最顶尖的摇滚鼓手之一[15]。除在 Foo Fighters 的工作外,霍金斯对音乐的热情也促使他参与众多副项目与合作,进一步巩固了他在摇滚乐界的地位[10]。
在职业生涯之外,霍金斯也以坚韧与对家庭的投入而被人所知。尽管他经历过个人困境,包括 2001 年一次几乎致命的药物过量事件,他仍持续投身音乐事业[4][9]。他对摇滚音乐的贡献与不屈的精神,使其在音乐产业中成为难以磨灭的标志性人物,并持续激励着音乐人与乐迷[13]。
2022 年,霍金斯在哥伦比亚波哥大(Bogotá)巡演期间突然去世,这一消息震惊了整个音乐界[34]。来自世界各地的悼念与致敬纷至沓来,反映出他生前所赢得的尊敬与爱戴[21][31]。洛杉矶为他举办的群星云集纪念演出对其人生与事业致敬,也印证了他音乐影响力的长久延续[22]。
# 早年生活与成长背景
奥利弗·泰勒·霍金斯(通常称为 Taylor Hawkins)出生并成长于德克萨斯州沃尔顿堡[3]。他四岁时随家人搬到加利福尼亚州拉古纳海滩(Laguna Beach)[3]。他有两个年幼的兄弟姐妹:弟弟 Jason 和妹妹 Heather[3]。童年时期,他尤其受到祖母 Josie Hawkins 的影响;Josie 在大萧条时期长大,曾居住于密西西比州杰克逊(Jackson, Mississippi)[1]。
在拉古纳海滩高中(Laguna Beach High School)就读期间(1990 年毕业),他结识了 Jon Davison(后成为乐队 Yes 的主唱)[2][3]。他对音乐的兴趣从小便得到滋养,尤其在 1982 年观看皇后乐队演唱会后更受启发,从而开始学习打鼓[2][5]。他也提到,音乐在他的家庭生活中始终是持续存在的一部分[5]。
尽管成长过程中也经历了一些困难,包括母亲与所谓“心魔”("demons")的斗争,霍金斯仍坚持追逐自己的音乐理想[4]。他将家庭在艰难时期得以维系的功劳归于姐姐 Heather,认为姐姐承担了照顾家人的责任[4]。
他最重要的早期音乐经历来自为艾拉妮丝·莫莉塞特的专辑《Jagged Little Pill》担任鼓手,并参与其随后的巡演[3]。这标志着他在音乐产业中职业生涯的正式起步。
# 职业生涯
泰勒·霍金斯的职业音乐生涯始于为艾拉妮丝·莫莉塞特效力:在 1995 至 1997 年间,他随她进行为畅销专辑《Jagged Little Pill》助阵的 18 个月世界巡演[8][9]。他不仅参与巡演演出,也出现在《You Oughta Know》《All I Really Want》《You Learn》等音乐视频中,这让他进入摇滚世界,也最终促成他与戴夫·格罗尔的相识[8]。在这一时期,霍金斯对乐队的音色与现场表现贡献显著——他把原本以鼓机循环为基础的编排转化为更具摇滚乐队质感的律动,使其更能与观众共鸣[1][7]。
1997 年,格罗尔邀请霍金斯加入 Foo Fighters,而霍金斯欣然接受[7][8]。当时,莫莉塞特正处于事业巅峰,格罗尔认为成功招募霍金斯的可能性不大;但霍金斯渴望成为摇滚乐队一员的愿望促使他做出转变[7]。自此,他开始担任 Foo Fighters 的鼓手,直至去世[6][9]。
除与莫莉塞特及 Foo Fighters 的工作外,霍金斯还有诸多音乐经历[10]。在加入莫莉塞特巡演乐队前,他曾为 Sass Jordan 担任鼓手[10]。他也是一个临时鼓手超级组合 SOS Allstars 的成员,并在 Coheed and Cambria 的鼓手 Josh Eppard 离队后,为该乐队 2007 年专辑补位录制[10]。此外,他在 2005 年组建了自己的副项目 Coattail Riders,通过该项目录制个人作品,并在 Foo Fighters 已成为体育馆级(arena‑status)乐队的情况下仍选择在小型俱乐部巡演演出[7]。他的儿子 Shane Hawkins 也延续父亲的遗产:在 2023 年 Boston Calling Music Festival 的一场演出中与 Foo Fighters 同台[6]。
# 音乐风格与影响
泰勒·霍金斯是一位极具造诣的鼓手,其音乐风格与影响遍及多种摇滚子类型[11]。他以对前辈乐队的热忱“粉丝”姿态著称,经常表达自己对 Rush、Genesis、The Police 等乐队的钦佩;这些乐队都拥有摇滚史上最伟大的鼓手之一,如 Neil Peart、Phil Collins 与 Stewart Copeland[11]。
他对经典摇滚的热爱也体现在其舞台表演中,例如翻奏 Van Halen 等乐队的作品[11]。
霍金斯从多种鼓击风格中汲取养分,发展出标志性的演奏语言,并以 Roger Taylor、Neil Peart、Phil Collins、Alex Van Halen、Stewart Copeland 等大师为灵感来源[14]。这种独特的风格与影响也延伸到他的鼓组配置:他在套鼓中加入了 rototoms 与 concert toms 等元素[14]。
除去其影响来源,霍金斯还拥有使其脱颖而出的独特能量。他的演出以力量感著称,并以热情且富有攻击性的演奏风格闻名[15]。这使他被公认为同代顶尖摇滚鼓手之一,而他对音乐的热爱也通过其舞台表演得以延续[14]。
在整个职业生涯中,霍金斯凭借独特风格、热情以及对音乐产业的贡献,在摇滚乐史上留下了难以磨灭的印记[13]。他对音乐的热爱与对技艺的投入,使他成为摇滚世界中令人难忘的标志性人物[13]。
# 个人生活
2005 年,泰勒·霍金斯与美国名人及企业家 Alison Hawkins 结婚[18]。两人育有三个孩子:Oliver、Annabelle 与 Everleigh[19]。霍金斯对家庭的投入显而易见;他甚至为自己的二女儿 Annabelle 写过一首歌[9]。
在个人生活中,霍金斯也曾受到药物问题困扰,2001 年一次过量事件几乎夺去他的生命[9][7][4]。不过,他最终克服了这一挑战,并在后来表示感谢这段经历——把它视为促使自己认识到所处自毁道路的教训[7]。
除在 Foo Fighters 的核心工作之外,霍金斯还投入多个副项目,包括 Birds of Satan、NHC 与 Chevy Metal。他从事这些尝试的动力来自持续的创作冲动以及对音乐的热爱[7]。他也以毫不掩饰的“迷弟”性格著称,常常公开表达对同行音乐人及其偶像的崇拜[7]。
# 遗产与影响
泰勒·霍金斯以质朴而真实的鼓击风格闻名,有人将其描述为“勇敢、带着伤痕且毫不矫饰的真实”("courageous, damaged and unflinchingly authentic")[20]。他在 Foo Fighters 的工作,以及众多合作与副项目,使他成为摇滚乐界备受赞誉的人物[10]。
霍金斯在 2022 年去世后,来自同侪与全球乐迷的真挚悼念接连涌现。尤为引人注目的致敬来自皇后乐队的 Roger Taylor 等摇滚传奇人物:他认为霍金斯善良而才华横溢,是鼓舞人心的导师,并将其离世比作“失去了一位更年轻、最爱的弟弟”("losing a younger favourite brother")[21]。同样,齐柏林飞艇(Led Zeppelin)的 Jimmy Page 也赞赏其技巧、能量与饱含激情的热忱[21]。
在洛杉矶为他举办的纪念演出中,Metallica 的 Lars Ulrich、blink‑182 的 Travis Barker、Rage Against the Machine 的 Brad Wilk 等鼓手担任嘉宾;Miley Cyrus 与 Alanis Morissette 等歌手也在演出中登台[22]。
除音乐之外,泰勒·霍金斯还支持了 Music Support 与 MusiCares 等慈善组织(均由霍金斯家人选定)[23]。他在职业生涯中获得诸多荣誉,包括 27 项格莱美提名,其中 14 次获奖[2]。2021 年,Foo Fighters 入选摇滚名人堂(Rock and Roll Hall of Fame)[9]。
# 唱片作品
泰勒·霍金斯也通过副项目与合作延展出一段引人注目的音乐生涯[10]。除 Foo Fighters 之外,他组建并担任乐队 Taylor Hawkins & The Coattail Riders 的主唱/核心人物,该项目起源于他与好友 Drew Hester 的即兴合奏(jamming)[10]。
### Taylor Hawkins & The Coattail Riders
Taylor Hawkins & The Coattail Riders 成立于 2004 年,已发行三张专辑,音乐风格涵盖硬摇滚(Hard Rock)、艺术摇滚(Art Rock)与另类摇滚(Alternative Rock)等[24][25][26]。该乐队从最初随意的合奏逐步发展为更正式的编制,最终推动了唱片专辑的制作。值得注意的是,这些专辑中邀请了多位知名音乐人客串,包括 Dave Grohl、皇后乐队的 Brian May 与 Roger Taylor、The Cars 的 Elliot Easton、Perry Farrell,以及霍金斯的高中好友 Jon Davison(Yes 的主唱)等[10]。
### Red Light Fever
Red Light Fever 于 2010 年 4 月 19 日发行,是该乐队的首张专辑[29][30]。在发行前的一次采访中,霍金斯透露该专辑已完成录制与制作环节,但标题与发行日期尚未最终确定[29]。专辑在加州 Foo Fighters 的 Studio 606 录制,并邀请了 Brian May 与 Roger Taylor(Queen)、Dave Grohl(Foo Fighters)、Elliot Easton(The Cars)等音乐人客串[29][30]。
## Get the Money
Get the Money 是 Taylor Hawkins & The Coattail Riders 的第三张专辑,于 2019 年 11 月 8 日发行[29]。该专辑的首支单曲《Crossed the Line》于 2019 年 10 月 15 日发布,由 Dave Grohl 与 Yes 主唱 Jon Davison 参与[29]。单曲《I Really Blew It》的音乐视频中也出现了 Grohl 与 Perry Farrell 的客串[29]。
# 合作与客串
在整个职业生涯中,泰勒·霍金斯与多位知名艺术家和乐队合作。Coattail Riders 的专辑中尤其汇聚了 Brian May 与 Roger Taylor(Queen)、Chrissie Hynde、Nancy Wilson(Heart)、Sex Pistols 的 Steve Jones,以及 James Gang 的 Joe Walsh 等音乐人客串[28]。霍金斯还担任另一支乐队 The Birds of Satan 的主唱/核心人物,该项目由他的重摇滚翻奏乐队 Chevy Metal 演变而来[28]。
尽管他涉猎多样的音乐项目,霍金斯始终与 Foo Fighters 保持紧密联系,该乐队也始终是其音乐生活的核心[7][28]。
# 悲剧离世
2022 年 3 月 25 日,Foo Fighters 在哥伦比亚波哥大巡演期间,乐队的另类摇滚鼓手泰勒·霍金斯突然去世[34]。官方公布的死因为心脏骤停,但也有人对其体内检出药物以及这些药物是否对死亡产生影响提出疑问[33][34]。在他去世当晚,因一名未具名住客报告胸痛,急救人员赶到波哥大的四季酒店(Four Seasons);随后确认该住客为霍金斯[34]。遗憾的是,抢救未能成功,他在现场被宣告死亡[34]。
霍金斯猝逝的消息在 2022 年 3 月 25 日早晨公布,令音乐界震惊[32]。乐队以简短声明确认噩耗,并表示对失去霍金斯深感悲痛,称他的“音乐精神与富有感染力的笑声”将永远长存[32]。
受其英年早逝影响,乐队取消了正在进行的南美巡演[33]。原定当晚 Foo Fighters 演出的 Estéreo Picnic Festival 舞台被改为烛光守夜,以纪念霍金斯[33]。
## 致敬与追忆
霍金斯去世后,来自全球乐迷与同业的致敬如潮涌现[21][31]。在众多表达哀悼的人中,包括摇滚史上的传奇音乐人,例如皇后乐队鼓手 Roger Taylor——霍金斯曾将其视为启发自己鼓手生涯的重要人物[21]。在真挚的社交媒体发文中,Taylor 称霍金斯为“鼓舞人心的导师”与“善良而才华横溢的人”("inspirational mentor"、"kind brilliant man")[21];与此同时,Led Zeppelin 的 Jimmy Page 也回忆与霍金斯同台的经历,并称赞其“技巧、能量与饱含激情的热忱”("technique, energy and spirited enthusiasm")[21]。
此外,也出现了大量舞台上的致敬。Miley Cyrus 在 Lollapalooza 演出时表达悲痛,并向 Foo Fighters 与霍金斯家人送上平安祝愿[31]。同样,绿洲(Oasis)的 Liam Gallagher 也在伦敦皇家阿尔伯特音乐厅(Royal Albert Hall)的演出中,将乐队最著名的一首作品献给霍金斯[31]。
乐迷们聚集在霍金斯去世的酒店外,点燃蜡烛、献上鲜花,并合唱乐队歌曲以示纪念[31]。
霍金斯的人生与事业也在洛杉矶一场群星云集的纪念演出中被庆祝;超过 50 位音乐人参与演出,阵容包括他曾合作的乐队与同业伙伴,如 Def Leppard、Queen 与 Foo Fighters 的成员等[22]。表 12:STORM 为 “Taylor Hawkins” 生成的文章示例。#、##、### 分别表示章节标题与不同层级的小节标题;方括号中的数字表示引用的参考来源。